并发编程03
# 并发编程03
# 一、CountDownLatch,Semaphore的高频问题:
# 1.1 CountDownLatch是啥?有啥用?底层咋实现的?(可以融入到你的项目业务中。)
CountDownLatch本质其实就是一个计数器。
在多线程并形处理业务时,需要等待其他线程处理完,再做后续的合并等操作,再响应用户时,可以使用CountDownLatch做计数,等到其他线程出现完之后,主线程就会被唤醒。
CountDownLatch本身就是基于AQS实现的。
new CountDownLatch时,直接指定好具体的数值。这个数值会复制给state属性。
当子线程处理完任务后,执行countDown方法,内部就是直接给state - 1而已。
当state减为0之后,执行await挂起的线程,就会被唤醒。
CountDownLatch不能重复使用,用完就凉凉。
# 1.2 Semaphore是啥?有啥用?底层咋实现的?
信号量,就是一个可以用于做限流功能的工具类。
比如Hystrix中涉及到了信号量隔离,要求并发的线程数有限制,就可以使用信号量实现。
比如要求当前服务最多10个线程同时干活,将信号量设置为10。没一个任务提交都需要获取一个信号量,就去干活,干完了,归还信号量。
信号量也是基于AQS实现的。
构建信号量时,指定信号量资源数,获取时,指定获取几个信号量,也是CAS保证原子性,归还也是类似的。
# 1.3 main线程结束,程序会停止嘛?
如果main线程结束,但是还有用户线程在执行,不会结束!
如果main线程结束,剩下的都是守护线程,结束!
# 二、CopyOnWriteArrayList的高频问题:
# 2.1 CopyOnWriteArrayList是如何保证线程安全的?有什么缺点吗?
CopyOnWriteArrayList写数据时,是基于ReentrantLock保证原子性的。
其次,写数据时,会复制一个副本写入,写入成功后,才会写入到CopyOnWriteArrayList中的数组。
保证读数据时,不要出现数据不一致的问题。
如果数据量比较大时,每次写入数据,都需要复制一个副本,对空间的占用太大了。如果数据量比较大,不推荐使用CopyOnWriteArrayList。
写操作要求保证原子性,读操作保证并发,并且数据量不大 ~
# 三、ConcurrentHashMap(JDK1.8)的高频问题:
# 3.1 HashMap为啥线程不安全?
问题1:JDK1.7里有环(扩容时)。
问题2:数据会覆盖,数据可能丢失。
问题3:其次计数器,也是传统的++,在记录元素个数和HashMap写的次数时,记录不准确。
问题4:数据迁移,扩容,也可能会丢失数据。
# 3.2 ConcurrentHashMap如何保证线程安全的?
回答1:尾插,其次扩容有CAS保证线程安全
回答2:写入数组时,基于CAS保证安全,挂入链表或插入红黑树时,基于synchronized保证安全。
回答3:这里ConcurrentHashMap是采用LongAdder实现的技术,底层还是CAS。(AtomicLong)
回答4:ConcurrentHashMap扩容时,一点基于CAS保证数据迁移不出现并发问题, 其次ConcurrentHashMap还提供了并发扩容的操作。举个例子,数组长度64扩容为128,两个线程同时扩容的话,
线程A领取64-48索引的数据迁移任务,线程B领取47-32的索引数据迁移任务。关键是领取任务时,是基于CAS保证线程安全的。
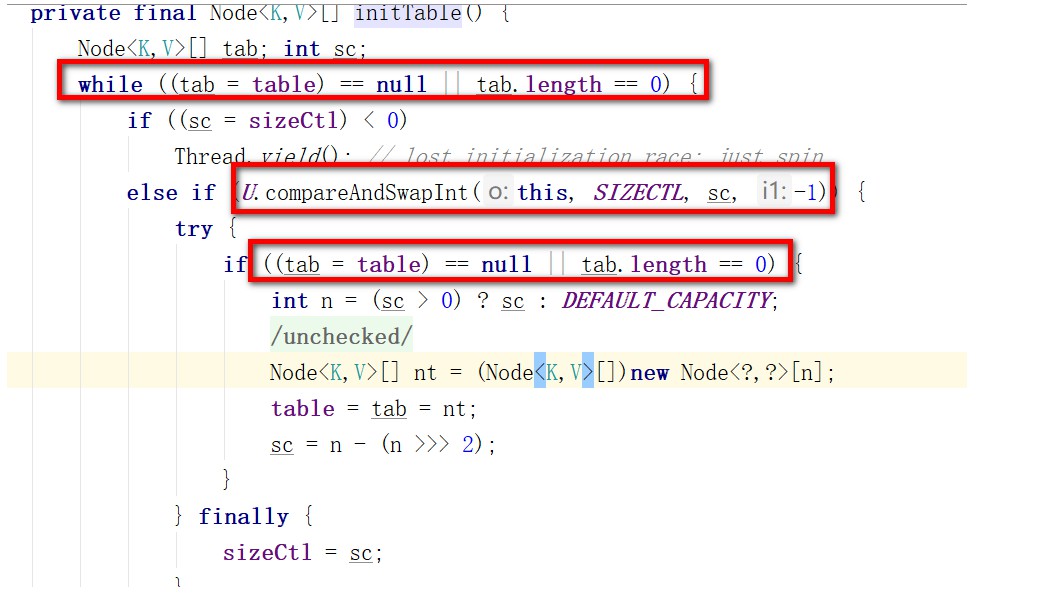
# 3.3 ConcurrentHashMap构建好,数组就创建出来了吗?如果不是,如何保证初始化数组的线程安全?
ConcurrentHashMap是懒加载的机制,而且大多数的框架组件都是懒加载的~
基于CAS来保证初始化线程安全的,这里不但涉及到了CAS去修改sizeCtl的变量去控制线程初始化数据的原子性,同时还使用了DCL,外层判断数组未初始化,中间基于CAS修改sizeCtl,内层再做数组未初始化判断。
# 3.4 put操作太频繁的场景,会造成扩容时期put的阻塞 ?
一般情况下不会造成阻塞。
因为如果在put操作时,发现当前索引位置并没有数据时,正常把数据落到老数组上。
如果put操作时,发现当前位置数据已经被迁移到了新数组,这时无法正常插入,去帮助扩容,快速结束扩容操作,并且重新选择索引位置查询
# 3.5 ConcurrentHashMap何时扩容,扩容的流程是什么?
- ConcurrentHashMap中的元素个数,达到了负载因子计算的阈值,那么直接扩容
- 当调用putAll方法,查询大量数据时,也可能会造成直接扩容的操作,大量数据是如果插入的数据大于下次扩容的阈值,直接扩容,然后再插入
- 数组长度小于64,并且链表长度大于等于8时,会触发扩容
# 3.6 ConcurrentHashMap得计数器如何实现的?
这里是基于LongAdder的机制实现,但是并没有直接用LongAdder的引用,而是根据LongAdder的原理写了一个相似度在80%以上的代码,直接使用。
LongAdder使用CAS添加,保证原子性,其次基于分段锁,保证并发性。
# 3.7 ConcurrentHashMap的读操作会阻塞嘛?
无论查哪,都不阻塞。
查询数组? :第一块就是查看元素是否在数组,在就直接返回。
查询链表?:第二块,如果没特殊情况,就在链表next,next查询即可。
扩容时?:第三块,如果当前索引位置是-1,代表当前位置数据全部都迁移到了新数组,直接去新数组查询,不管有没有扩容完。
查询红黑树?:如果有一个线程正在写入红黑树,此时读线程还能去红黑树查询吗?因为红黑树为了保证平衡可能会旋转,旋转会换指针,可能会出现问题。所以在转换红黑树时,不但有一个红黑树,还会保留一个双向链表,此时会查询双向链表,不让读线程阻塞。至于如何判断是否有线程在写,和等待写或者是读红黑树,根据TreeBin的lockState来判断,如果是1,代表有线程正在写,如果为2,代表有写线程等待写,如果是4n,代表有多个线程在做读操作。