KubeAdm安装
# kubeadm部署单Master节点kubernetes集群 1.21
# 一、kubernetes 1.21发布

# 1.1 介绍
2021年04月,Kubernetes 1.21正式与大家见面,这是我们 2021 年的第一个版本!这个版本包含 51 个增强功能:13 个增强功能升级为稳定版,16 个增强功能升级为 beta 版,20 个增强功能进入 alpha 版,还有 2 个功能已经弃用。
# 1.2 主要变化
- CronJobs 毕业到稳定!
自 Kubernetes 1.8 以来,CronJobs一直是一个测试版功能!在 1.21 中,我们终于看到这个广泛使用的 API 毕业到稳定。
CronJobs 用于执行定期计划的操作,如备份、报告生成等。每个任务都应该被配置为无限期地重复出现(例如:一天/一周/一个月);你可以在该间隔内定义作业应该启动的时间点。
- 不可变的 Secrets 和 ConfigMaps
Immutable Secrets和ConfigMaps为这些资源类型添加了一个新字段,如果设置了该字段,将拒绝对这些对象的更改。默认情况下,Secrets 和 ConfigMaps 是可变的,这对能够使用更改的 pod 是有益的。如果将错误的配置推送给使用它们的 pod,可变的 Secrets 和 ConfigMaps 也会导致问题。
通过将 Secrets 和 ConfigMaps 标记为不可变的,可以确保应用程序配置不会改变。如果你希望进行更改,则需要创建一个新的、唯一命名的 Secret 或 ConfigMap,并部署一个新的 pod 来消耗该资源。不可变资源也有伸缩性优势,因为控制器不需要轮询 API 服务器来观察变化。
这个特性在 Kubernetes 1.21 中已经毕业到稳定。
- IPv4/IPv6 双栈支持
IP 地址是一种可消耗的资源,集群操作人员和管理员需要确保它不会耗尽。特别是,公共 IPv4 地址现在非常稀少。双栈支持使原生 IPv6 路由到 pod 和服务,同时仍然允许你的集群在需要的地方使用 IPv4。双堆栈集群网络还改善了工作负载的可能伸缩限制。
Kubernetes 的双栈支持意味着 pod、服务和节点可以获得 IPv4 地址和 IPv6 地址。在 Kubernetes 1.21 中,双栈网络已经从 alpha 升级到 beta,并且已经默认启用了。
- 优雅的节点关闭
在这个版本中,优雅的节点关闭也升级到测试版(现在将提供给更大的用户群)!这是一个非常有益的特性,它允许 kubelet 知道节点关闭,并优雅地终止调度到该节点的 pod。
目前,当节点关闭时,pod 不会遵循预期的终止生命周期,也不会正常关闭。这可能会在许多不同的工作负载下带来问题。接下来,kubelet 将能够通过 systemd 检测到即将发生的系统关闭,然后通知正在运行的 pod,以便它们能够尽可能优雅地终止。
- PersistentVolume 健康监测器
持久卷(Persistent Volumes,PV)通常用于应用程序中获取本地的、基于文件的存储。它们可以以许多不同的方式使用,并帮助用户迁移应用程序,而不需要重新编写存储后端。
Kubernetes 1.21 有一个新的 alpha 特性,允许对 PV 进行监视,以了解卷的运行状况,并在卷变得不健康时相应地进行标记。工作负载将能够对运行状况状态作出反应,以保护数据不被从不健康的卷上写入或读取。
- 减少 Kubernetes 的构建维护
以前,Kubernetes 维护了多个构建系统。这常常成为新贡献者和当前贡献者的摩擦和复杂性的来源。
在上一个发布周期中,为了简化构建过程和标准化原生的 Golang 构建工具,我们投入了大量的工作。这应该赋予更广泛的社区维护能力,并降低新贡献者进入的门槛。
# 1.3 重大变化
- 弃用 PodSecurityPolicy
在 Kubernetes 1.21 中,PodSecurityPolicy 已被弃用。与 Kubernetes 所有已弃用的特性一样,PodSecurityPolicy 将在更多版本中继续可用并提供完整的功能。先前处于测试阶段的 PodSecurityPolicy 计划在 Kubernetes 1.25 中删除。
接下来是什么?我们正在开发一种新的内置机制来帮助限制 Pod 权限,暂定名为“PSP 替换策略”。我们的计划是让这个新机制覆盖关键的 PodSecurityPolicy 用例,并极大地改善使用体验和可维护性。
- 弃用 TopologyKeys
服务字段 topologyKeys 现在已弃用;所有使用该字段的组件特性以前都是 alpha 特性,现在也已弃用。我们用一种实现感知拓扑路由的方法替换了 topologyKeys,这种方法称为感知拓扑提示。支持拓扑的提示是 Kubernetes 1.21 中的一个 alpha 特性。你可以在拓扑感知提示中阅读关于替换特性的更多细节;相关的KEP解释了我们替换的背景。
# 二、kubernetes 1.21.0 部署工具介绍
# What is Kubeadm ?
Kubeadm is a tool built to provide best-practice "fast paths" for creating Kubernetes clusters. It performs the actions necessary to get a minimum viable, secure cluster up and running in a user friendly way. Kubeadm's scope is limited to the local node filesystem and the Kubernetes API, and it is intended to be a composable building block of higher level tools.
Kubeadm是为创建Kubernetes集群提供最佳实践并能够“快速路径”构建kubernetes集群的工具。它能够帮助我们执行必要的操作,以获得最小可行的、安全的集群,并以用户友好的方式运行。
# Common Kubeadm cmdlets
- kubeadm init to bootstrap the initial Kubernetes control-plane node.
初始化 - kubeadm join to bootstrap a Kubernetes worker node or an additional control plane node, and join it to the cluster.
添加工作节点到kubernetes集群 - kubeadm upgrade to upgrade a Kubernetes cluster to a newer version.
更新kubernetes版本 - kubeadm reset to revert any changes made to this host by kubeadm init or kubeadm join.
重置kubernetes集群
# 三、kubernetes 1.21.0 部署环境准备
# 3.1 主机操作系统说明
| 序号 | 操作系统及版本 | 备注 |
|---|---|---|
| 1 | CentOS7u9 |
# 3.2 主机硬件配置说明
| 需求 | CPU | 内存 | 硬盘 | 角色 | 主机名 |
|---|---|---|---|---|---|
| 值 | 4C | 8G | 100GB | master | master01(ha01) |
| 值 | 4C | 8G | 100GB | worker(node) | worker01(ha02) |
| 值 | 4C | 8G | 100GB | worker(node) | worker02(ha03) |
# 3.3 主机配置
# 3.3.1 主机名配置
由于本次使用3台主机完成kubernetes集群部署,其中1台为master节点,名称为ha01;其中2台为worker节点,名称分别为:ha02及ha03
master节点,名称为ha01
# hostnamectl set-hostname ha01
2
worker1节点,名称为ha02
# hostnamectl set-hostname ha02
2
worker2节点,名称为ha03
# hostnamectl set-hostname ha03
2
# 3.3.2 主机IP地址配置
master节点IP地址为:192.168.100.101/24
# vim /etc/sysconfig/network-scripts/ifcfg-ens33
TYPE=Ethernet
PROXY_METHOD=none
BROWSER_ONLY=no
BOOTPROTO=static
DEFROUTE=yes
IPV4_FAILURE_FATAL=no
IPV6INIT=yes
IPV6_AUTOCONF=yes
IPV6_DEFROUTE=yes
IPV6_FAILURE_FATAL=no
IPV6_ADDR_GEN_MODE=stable-privacy
NAME=ens33
UUID=d5ef0913-2656-43bb-9c9f-265010f6451d
DEVICE=ens33
ONBOOT=yes
IPADDR=192.168.100.101
NETMASK=255.255.255.0
GATEWAY=192.168.100.2
DNS1=114.114.114.114
DNS2=8.8.4.4
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
worker1节点IP地址为:192.168.100.102/24
# vim /etc/sysconfig/network-scripts/ifcfg-ens33
TYPE=Ethernet
PROXY_METHOD=none
BROWSER_ONLY=no
BOOTPROTO=static
DEFROUTE=yes
IPV4_FAILURE_FATAL=no
IPV6INIT=yes
IPV6_AUTOCONF=yes
IPV6_DEFROUTE=yes
IPV6_FAILURE_FATAL=no
IPV6_ADDR_GEN_MODE=stable-privacy
NAME=ens33
UUID=d5ef0913-2656-43bb-9c9f-265010f6451d
DEVICE=ens33
ONBOOT=yes
IPADDR=192.168.100.102
NETMASK=255.255.255.0
GATEWAY=192.168.100.2
DNS1=114.114.114.114
DNS2=8.8.4.4
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
worker1节点IP地址为:192.168.100.103/24
# vim /etc/sysconfig/network-scripts/ifcfg-ens33
TYPE=Ethernet
PROXY_METHOD=none
BROWSER_ONLY=no
BOOTPROTO=static
DEFROUTE=yes
IPV4_FAILURE_FATAL=no
IPV6INIT=yes
IPV6_AUTOCONF=yes
IPV6_DEFROUTE=yes
IPV6_FAILURE_FATAL=no
IPV6_ADDR_GEN_MODE=stable-privacy
NAME=ens33
UUID=d5ef0913-2656-43bb-9c9f-265010f6451d
DEVICE=ens33
ONBOOT=yes
IPADDR=192.168.100.103
NETMASK=255.255.255.0
GATEWAY=192.168.100.2
DNS1=114.114.114.114
DNS2=8.8.4.4
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
# 3.3.3 主机名与IP地址解析
所有集群主机均需要进行配置。
# cat /etc/hosts
192.168.100.101 ha01
192.168.100.102 ha02
192.168.100.103 ha03
2
3
4
# 3.3.4 防火墙配置
所有主机均需要操作。
关闭现有防火墙firewalld
systemctl disable firewalld
systemctl stop firewalld
firewall-cmd --state
not running
2
3
4
5
6
7
# 3.3.5 SELINUX配置
所有主机均需要操作。修改SELinux配置需要重启操作系统。
sed -ri 's/SELINUX=enforcing/SELINUX=disabled/' /etc/selinux/config
# 3.3.6 时间同步配置
所有主机均需要操作。最小化安装系统需要安装ntpdate软件。
crontab -e
# 添加
0 */1 * * * /usr/sbin/ntpdate time1.aliyun.com
2
3
# 3.3.7 升级操作系统内核
所有主机均需要操作。
导入elrepo gpg key
rpm --import https://www.elrepo.org/RPM-GPG-KEY-elrepo.org
安装elrepo YUM源仓库
yum -y install https://www.elrepo.org/elrepo-release-7.0-4.el7.elrepo.noarch.rpm
安装kernel-ml版本,ml为长期稳定版本,lt为长期维护版本
yum --enablerepo="elrepo-kernel" -y install kernel-ml.x86_64
设置grub2默认引导为0
grub2-set-default 0
重新生成grub2引导文件
grub2-mkconfig -o /boot/grub2/grub.cfg
更新后,需要重启,使用升级的内核生效。
reboot
重启后,需要验证内核是否为更新对应的版本
uname -r
# 3.3.9 安装ipset及ipvsadm
所有主机均需要操作。主要用于实现service转发。
安装ipset及ipvsadm
yum -y install ipset ipvsadm
配置ipvsadm模块加载方式 添加需要加载的模块
cat > /etc/sysconfig/modules/ipvs.modules <<EOF
#!/bin/bash
modprobe -- ip_vs
modprobe -- ip_vs_rr
modprobe -- ip_vs_wrr
modprobe -- ip_vs_sh
modprobe -- nf_conntrack
EOF
2
3
4
5
6
7
8
授权、运行、检查是否加载
chmod 755 /etc/sysconfig/modules/ipvs.modules && bash /etc/sysconfig/modules/ipvs.modules && lsmod | grep -e ip_vs -e nf_conntrack
# 3.3.10 关闭SWAP分区
修改完成后需要重启操作系统,如不重启,可临时关闭,命令为swapoff -a
永远关闭swap分区,需要重启操作系统
vim /etc/fstab
......
# /dev/mapper/centos-swap swap swap defaults 0 0
在上一行中行首添加#
2
3
4
5
6
reboot
# 3.4 Docker准备
所有集群主机均需操作。
# 3.4.1 获取YUM源
使用阿里云开源软件镜像站。
wget https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo -O /etc/yum.repos.d/docker-ce.repo
# 3.4.2 查看可安装版本
yum list docker-ce.x86_64 --showduplicates | sort -r
# 3.4.3 安装指定版本并设置启动及开机自启动
yum -y install --setopt=obsoletes=0 docker-ce-20.10.9-3.el7
systemctl enable docker ; systemctl start docker
# 3.4.4 修改cgroup方式
在/etc/docker/daemon.json添加如下内容
vim /etc/docker/daemon.json
{
"exec-opts": ["native.cgroupdriver=systemd"]
}
2
3
4
# 3.4.5 重启docker
systemctl restart docker
# 四、kubernetes 1.21.0 集群部署
# 4.1 集群软件及版本说明
| kubeadm | kubelet | kubectl | |
|---|---|---|---|
| 版本 | 1.21.0 | 1.21.0 | 1.21.0 |
| 安装位置 | 集群所有主机 | 集群所有主机 | 集群所有主机 |
| 作用 | 初始化集群、管理集群等 | 用于接收api-server指令,对pod生命周期进行管理 | 集群应用命令行管理工具 |
# 4.2 kubernetes YUM源准备
# 4.2.1 谷歌YUM源
vim /etc/yum.repos.d/k8s.repo
[kubernetes]
name=Kubernetes
baseurl=https://packages.cloud.google.com/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=1
repo_gpgcheck=1
gpgkey=https://packages.cloud.google.com/yum/doc/yum-key.gpg
https://packages.cloud.google.com/yum/doc/rpm-package-key.gpg
2
3
4
5
6
7
8
9
10
# 4.2.2 阿里云YUM源
vim /etc/yum.repos.d/k8s.repo
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/
enabled=1
gpgcheck=1
repo_gpgcheck=0
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
2
3
4
5
6
7
8
9
# 4.2.3 查看yum源
yum repolist
base/7/x86_64 CentOS-7 - Base 10,072
docker-ce-stable/7/x86_64 Docker CE Stable - x86_64 169
elrepo ELRepo.org Community Enterprise Linux Repository - el7 156
epel/x86_64 Extra Packages for Enterprise Linux 7 - x86_64 13,735
extras/7/x86_64 CentOS-7 - Extras 515
kubernetes Kubernetes 0
updates/7/x86_64 CentOS-7 - Updates 4,300
repolist: 28,947
2
3
4
5
6
7
8
# 4.3 集群软件安装
查看指定版本
yum list kubeadm.x86_64 --showduplicates | sort -r
yum list kubelet.x86_64 --showduplicates | sort -r
yum list kubectl.x86_64 --showduplicates | sort -r
2
3
4
安装指定版本
yum -y install --setopt=obsoletes=0 kubeadm-1.21.0-0 kubelet-1.21.0-0 kubectl-1.21.0-0
# 4.4 配置kubelet
为了实现docker使用的cgroupdriver与kubelet使用的cgroup的一致性,建议修改如下文件内容。
vim /etc/sysconfig/kubelet
KUBELET_EXTRA_ARGS="--cgroup-driver=systemd"
2
设置kubelet为开机自启动即可,由于没有生成配置文件,集群初始化后自动启动
systemctl enable kubelet
# 4.5 集群镜像准备
在master上操作
可使用VPN实现下载。
# kubeadm config images list --kubernetes-version=v1.21.0
k8s.gcr.io/kube-apiserver:v1.21.0
k8s.gcr.io/kube-controller-manager:v1.21.0
k8s.gcr.io/kube-scheduler:v1.21.0
k8s.gcr.io/kube-proxy:v1.21.0
k8s.gcr.io/pause:3.4.1
k8s.gcr.io/etcd:3.4.13-0
k8s.gcr.io/coredns/coredns:v1.8.0
2
3
4
5
6
7
8
# cat image_download.sh
#!/bin/bash
images_list='
k8s.gcr.io/kube-apiserver:v1.21.0
k8s.gcr.io/kube-controller-manager:v1.21.0
k8s.gcr.io/kube-scheduler:v1.21.0
k8s.gcr.io/kube-proxy:v1.21.0
k8s.gcr.io/pause:3.4.1
k8s.gcr.io/etcd:3.4.13-0
k8s.gcr.io/coredns/coredns:v1.8.0'
for i in $images_list
do
docker pull $i
done
docker save -o k8s-1-21-0.tar $images_list
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
非VPN下载实现
先使用阿里云现在,在重新打上标签
# 拉取镜像
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/kube-apiserver:v1.21.0
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/kube-proxy:v1.21.0
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/kube-controller-manager:v1.21.0
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/kube-scheduler:v1.21.0
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/pause:3.4.1
docker pull coredns/coredns:1.8.0 k8s.gcr.io/coredns/coredns:v1.8.0
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/etcd:3.4.13-0
# 修改标签
docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/kube-apiserver:v1.21.0 k8s.gcr.io/kube-apiserver:v1.21.0
docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/kube-proxy:v1.21.0 k8s.gcr.io/kube-proxy:v1.21.0
docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/kube-controller-manager:v1.21.0 k8s.gcr.io/kube-controller-manager:v1.21.0
docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/kube-scheduler:v1.21.0 k8s.gcr.io/kube-scheduler:v1.21.0
docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/pause:3.4.1 k8s.gcr.io/pause:3.4.1
docker tag coredns/coredns:1.8.0 k8s.gcr.io/coredns/coredns:v1.8.0
docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/etcd:3.4.13-0 k8s.gcr.io/etcd:3.4.13-0
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
将镜像打包供其他服务器使用
images_list='
k8s.gcr.io/kube-apiserver:v1.21.0
k8s.gcr.io/kube-controller-manager:v1.21.0
k8s.gcr.io/kube-scheduler:v1.21.0
k8s.gcr.io/kube-proxy:v1.21.0
k8s.gcr.io/pause:3.4.1
k8s.gcr.io/etcd:3.4.13-0
k8s.gcr.io/coredns/coredns:v1.8.0'
docker save -o k8s-1-21-0.tar $images_list
2
3
4
5
6
7
8
9
10
11
# 4.6 集群初始化
master节点操作
kubeadm init --kubernetes-version=v1.21.0 --pod-network-cidr=10.244.0.0/16 --apiserver-advertise-address=192.168.100.101
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 192.168.100.101:6443 --token n7nq5q.ndmxhr5nroitt1ey \
--discovery-token-ca-cert-hash sha256:41830251802f60ea4e6a68bc5ebd512baf8285c8bb79b62daa9be61b42a46d0e
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
输出内容,一定保留,便于后继操作使用。
# 4.7 集群应用客户端管理集群文件准备
mkdir -p $HOME/.kube
cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
chown $(id -u):$(id -g) $HOME/.kube/config
ls /root/.kube/
config
2
3
4
5
export KUBECONFIG=/etc/kubernetes/admin.conf
# 4.8 集群网络准备
使用calico部署集群网络
安装参考网址:https://projectcalico.docs.tigera.io/about/about-calico
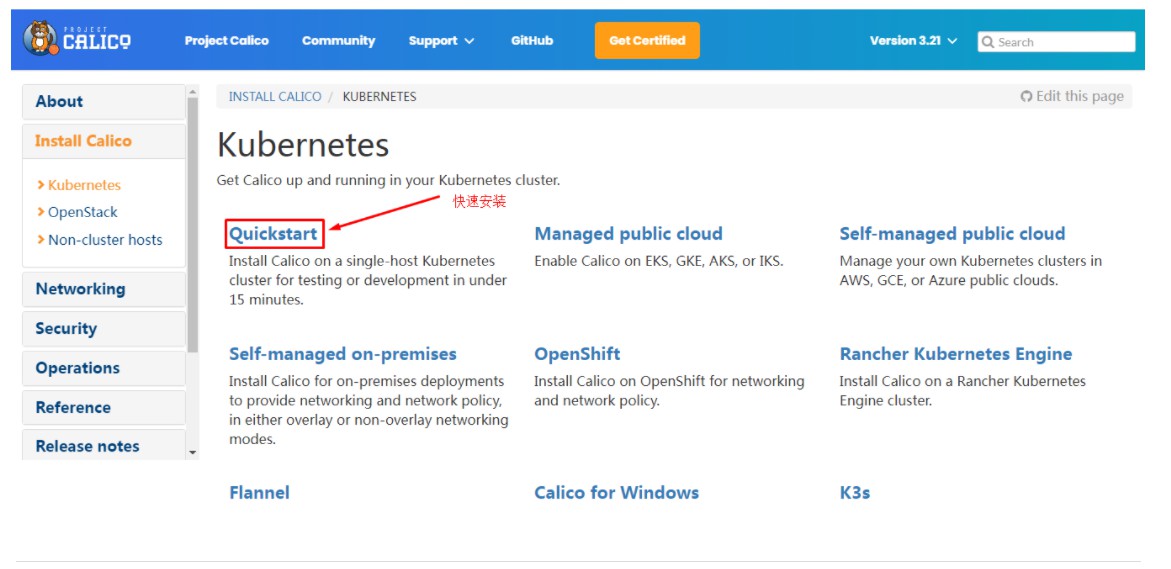
# 4.8.1 calico安装

下载operator资源清单文件
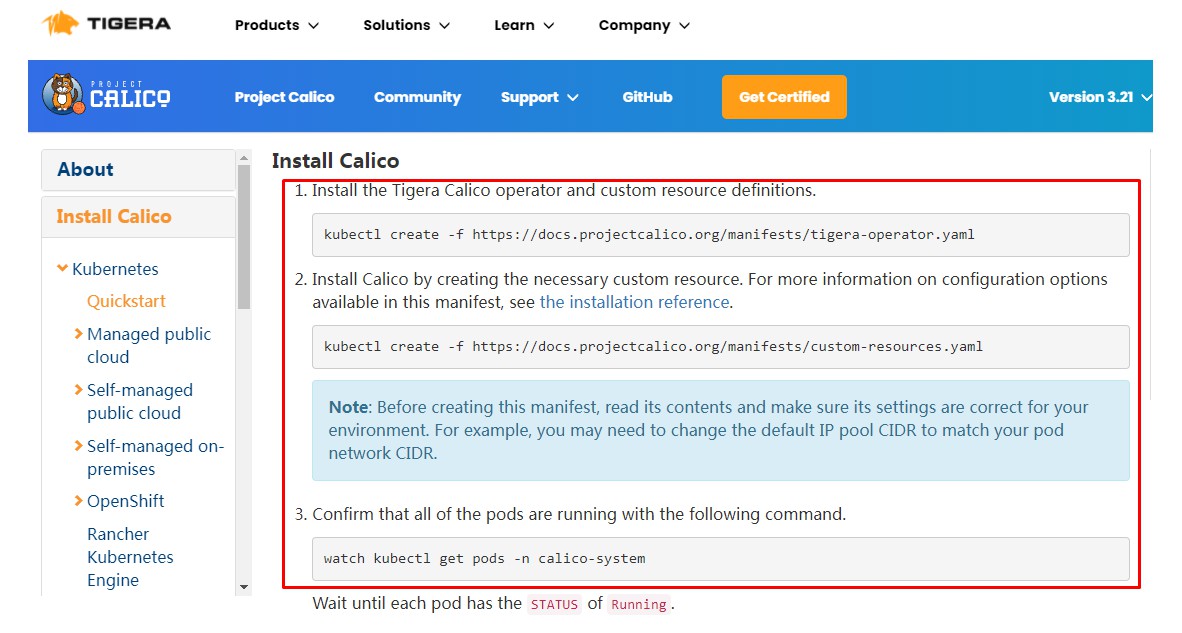
wget https://docs.projectcalico.org/manifests/tigera-operator.yaml
应用资源清单文件,创建operator
kubectl create -f tigera-operator.yaml
通过自定义资源方式安装
wget https://docs.projectcalico.org/manifests/custom-resources.yaml
修改文件第13行,修改为使用kubeadm init ----pod-network-cidr对应的IP地址段
vim custom-resources.yaml
......
11 ipPools:
12 - blockSize: 26
13 cidr: 10.244.0.0/16
14 encapsulation: VXLANCrossSubnet
......
2
3
4
5
6
7
应用资源清单文件
kubectl create -f custom-resources.yaml
2
监视calico-sysem命名空间中pod运行情况
watch kubectl get pods -n calico-system
Wait until each pod has the
STATUSofRunning.
已经全部运行
kubectl get pods -n calico-system
NAME READY STATUS RESTARTS AGE
calico-kube-controllers-666bb9949-dzp68 1/1 Running 0 11m
calico-node-jhcf4 1/1 Running 4 11m
calico-typha-68b96d8d9c-7qfq7 1/1 Running 2 11m
2
3
4
5
查看kube-system命名空间中coredns状态,处于Running状态表明联网成功。
kubectl get pods -n kube-system
NAME READY STATUS RESTARTS AGE
coredns-558bd4d5db-4jbdv 1/1 Running 0 113m
coredns-558bd4d5db-pw5x5 1/1 Running 0 113m
etcd-master01 1/1 Running 0 113m
kube-apiserver-master01 1/1 Running 0 113m
kube-controller-manager-master01 1/1 Running 4 113m
kube-proxy-kbx4z 1/1 Running 0 113m
kube-scheduler-master01 1/1 Running 3 113m
2
3
4
5
6
7
8
9
10
# 4.8.2 calico客户端安装
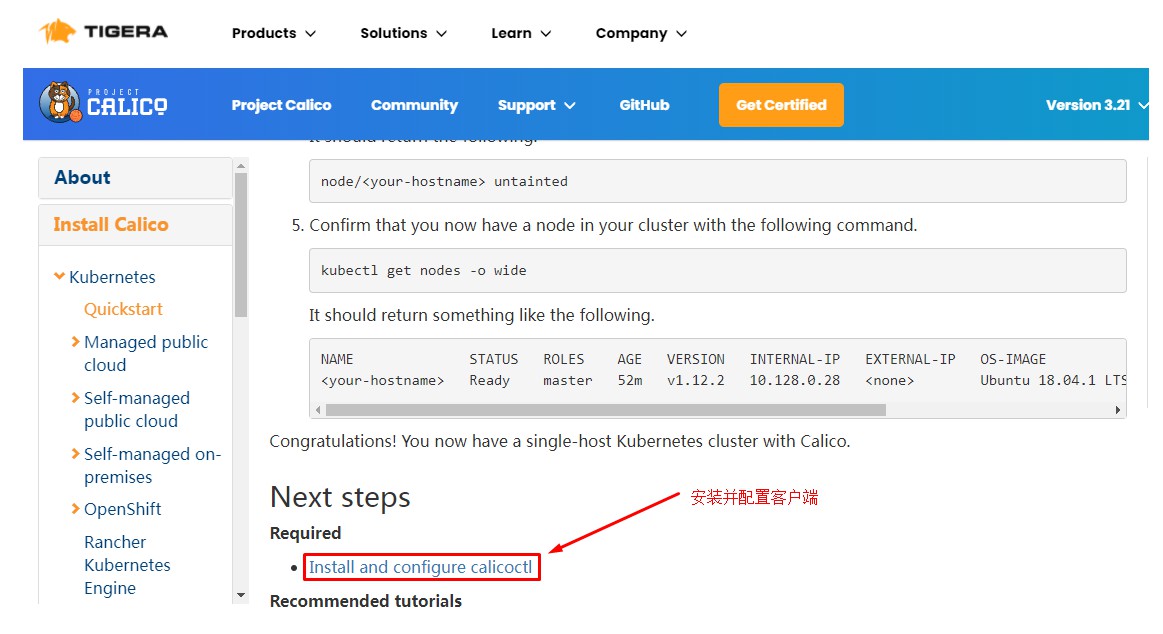
下载二进制文件
curl -L https://github.com/projectcalico/calico/releases/download/v3.21.4/calicoctl-linux-amd64 -o calicoctl
安装calicoctl
mv calicoctl /usr/bin/
为calicoctl添加可执行权限
chmod +x /usr/bin/calicoctl
查看添加权限后文件
ls /usr/bin/calicoctl
/usr/bin/calicoctl
查看calicoctl版本
calicoctl version
Client Version: v3.21.4
Git commit: 220d04c94
Cluster Version: v3.21.4
Cluster Type: typha,kdd,k8s,operator,bgp,kubeadm
2
3
4
5
6
7
8
9
10
11
12
13
14
15
通过~/.kube/config连接kubernetes集群,查看已运行节点
DATASTORE_TYPE=kubernetes KUBECONFIG=~/.kube/config calicoctl get nodes
NAME
master01
2
3
# 4.9 集群工作节点添加
因容器镜像下载较慢,可能会导致报错,主要错误为没有准备好cni(集群网络插件),如有网络,请耐心等待即可。
ha02
kubeadm join 192.168.100.101:6443 --token 3qfska.n01ymv7qlr6iby3m \
--discovery-token-ca-cert-hash sha256:0e3ae6a9d1bcff5dfe98e8c6843ed839ce6ded0322f7f8851f6072429674b333
2
ha03
kubeadm join 192.168.100.101:6443 --token 3qfska.n01ymv7qlr6iby3m \
--discovery-token-ca-cert-hash sha256:0e3ae6a9d1bcff5dfe98e8c6843ed839ce6ded0322f7f8851f6072429674b333
2
在master节点上操作,查看网络节点是否添加
DATASTORE_TYPE=kubernetes KUBECONFIG=~/.kube/config calicoctl get nodes
NAME
master01
worker01
worker02
2
3
4
5
# 4.10 验证集群可用性
kubectl get nodes
NAME STATUS ROLES AGE VERSION
master01 Ready control-plane,master 169m v1.21.0
worker01 Ready <none> 28m v1.21.0
worker02 Ready <none> 28m v1.21.0
2
3
4
5
6
查看集群健康情况,理想状态
kubectl get cs
NAME STATUS MESSAGE ERROR
controller-manager Healthy ok
scheduler Healthy ok
etcd-0 Healthy {"health":"true"}
2
3
4
5
6
真实情况
kubectl get cs
Warning: v1 ComponentStatus is deprecated in v1.19+
NAME STATUS MESSAGE ERROR
scheduler Unhealthy Get "http://127.0.0.1:10251/healthz": dial tcp 127.0.0.1:10251: connect: connection refused
controller-manager Unhealthy Get "http://127.0.0.1:10252/healthz": dial tcp 127.0.0.1:10252: connect: connection refused
etcd-0 Healthy {"health":"true"}
2
3
4
5
6
查看kubernetes集群pod运行情况
kubectl get pods -n kube-system
NAME READY STATUS RESTARTS AGE
coredns-558bd4d5db-4jbdv 1/1 Running 1 169m
coredns-558bd4d5db-pw5x5 1/1 Running 1 169m
etcd-master01 1/1 Running 1 170m
kube-apiserver-master01 1/1 Running 1 170m
kube-controller-manager-master01 1/1 Running 14 170m
kube-proxy-kbx4z 1/1 Running 1 169m
kube-proxy-rgtr8 1/1 Running 0 29m
kube-proxy-sq9xv 1/1 Running 0 29m
kube-scheduler-master01 1/1 Running 11 170m
2
3
4
5
6
7
8
9
10
11
再次查看calico-system命名空间中pod运行情况。
kubectl get pods -n calico-system
NAME READY STATUS RESTARTS AGE
calico-kube-controllers-666bb9949-dzp68 1/1 Running 3 70m
calico-node-jhcf4 1/1 Running 15 70m
calico-node-jxq9p 1/1 Running 0 30m
calico-node-kf78q 1/1 Running 0 30m
calico-typha-68b96d8d9c-7qfq7 1/1 Running 13 70m
calico-typha-68b96d8d9c-wz2zj 1/1 Running 0 20m
2
3
4
5
6
7
8