Flink
# Flink框架处理流程
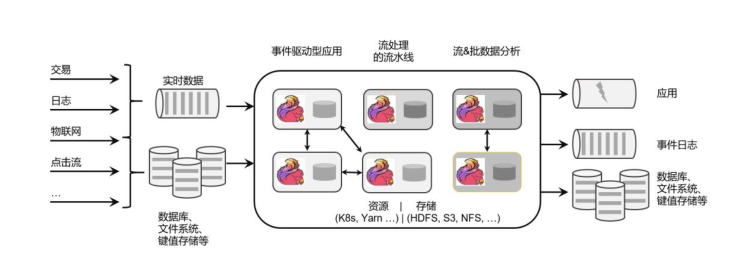
# Flink 的应用
# 电商和市场营销
举例:实时数据报表、广告投放、实时推荐
# 物联网(IOT)
举例:传感器实时数据采集和显示、实时报警,交通运输业
# 物流配送和服务业
举例:订单状态实时更新、通知信息推送
# 银行和金融业
举例:实时结算和通知推送,实时检测异常行为
# Flink 的特性
- 高吞吐和低延迟。每秒处理数百万个事件,毫秒级延迟。
- 结果的准确性。Flink 提供了事件时间(event-time)和处理时间(processing-time)语义。对于乱序事件流,事件时间语义仍然能提供一致且准确的结果。
- 精确一次(exactly-once)的状态一致性保证。
- 可以连接到最常用的存储系统,如 Apache Kafka、Apache Cassandra、Elasticsearch、JDBC、Kinesis 和(分布式)文件系统,如 HDFS 和 S3。
- 高可用。本身高可用的设置,加上与 K8s,YARN 和 Mesos 的紧密集成,再加上从故障中快速恢复和动态扩展任务的能力,Flink 能做到以极少的停机时间 7×24 全天候运行。
- 能够更新应用程序代码并将作业(jobs)迁移到不同的 Flink 集群,而不会丢失应用程序的状态。
# 分层 API
除了上述这些特性之外,Flink 还是一个非常易于开发的框架,因为它拥有易于使用的分层 API,整体 API 分层如图 1-11 所示

# Flink 快速上手
创建项目
添加依赖
<properties> <flink.version>1.13.0</flink.version> <java.version>1.8</java.version> <scala.binary.version>2.12</scala.binary.version> <slf4j.version>1.7.30</slf4j.version> </properties> <dependencies> <!-- 引入 Flink 相关依赖--> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-java</artifactId> <version>${flink.version}</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-streaming-java_${scala.binary.version}</artifactId> <version>${flink.version}</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-clients_${scala.binary.version}</artifactId> <version>${flink.version}</version> </dependency> <!-- 引入日志管理相关依赖--> <dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-api</artifactId> <version>${slf4j.version}</version> </dependency> <dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-log4j12</artifactId> <version>${slf4j.version}</version> </dependency> <dependency> <groupId>org.apache.logging.log4j</groupId> <artifactId>log4j-to-slf4j</artifactId> <version>2.14.0</version> </dependency> </dependencies>1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41配置日志管理
resource下创建log4j.properties文件
添加内容
log4j.rootLogger=error, stdout log4j.appender.stdout=org.apache.log4j.ConsoleAppender log4j.appender.stdout.layout=org.apache.log4j.PatternLayout log4j.appender.stdout.layout.ConversionPattern=%-4r [%t] %-5p %c %x - %m%n1
2
3
4
# 编写代码 - 批处理
public class BatchWordCount {
public static void main(String[] args) throws Exception {
// 1.创建执行环境
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
// 2.从文件中读取数据、按行读取
DataSource<String> lineDS = env.readTextFile("bigdata_09_flink/datas/words.txt");
// 3.转换数据格式
FlatMapOperator<String, Tuple2<String, Long>> wordAndOne = lineDS.flatMap((String line, Collector<Tuple2<String, Long>> out) -> {
String[] words = line.split(" ");
for (String word : words) {
out.collect(Tuple2.of(word, 1L));
}
}).returns(Types.TUPLE(Types.STRING, Types.LONG));
// 4. 按照 word 进行分组
UnsortedGrouping<Tuple2<String, Long>> wordAndOneUG = wordAndOne.groupBy(0);
// 5. 分组内聚合统计
AggregateOperator<Tuple2<String, Long>> sum = wordAndOneUG.sum(1);
// 6. 打印结果
sum.print();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
代码说明和注意事项:
Flink 在执行应用程序前应该获取执行环境对象,也就是运行时上下文环境
Flink 同时提供了 Java 和 Scala 两种语言的 API,有些类在两套 API 中名称是一样的。所以在引入包时,如果有 Java 和 Scala 两种选择,要注意选用 Java 的包
直接调用执行环境的 readTextFile 方法,可以从文件中读取数据。
我们的目标是将每个单词对应的个数统计出来,所以调用 flatmap 方法可以对一行文字进行分词转换。将文件中每一行文字拆分成单词后,要转换成(word,count)形式的二元组,初始 count 都为 1。returns 方法指定的返回数据类型 Tuple2,就是 Flink 自带的二元组数据类型
在分组时调用了 groupBy 方法,它不能使用分组选择器,只能采用位置索引或属性名称进行分组
// 使用索引定位 dataStream.groupBy(0) // 使用类属性名称 dataStream.groupBy("id")1
2
3
4在分组之后调用 sum 方法进行聚合,同样只能指定聚合字段的位置索引或属性名称。
运行程序,控制台会打印出结果:
(java,1) (flink,1) (world,1) (hello,3)1
2
3
4可以看到,我们将文档中的所有单词的频次,全部统计出来,以二元组的形式在控制台打印输出了。
需要注意的是,这种代码的实现方式,是基于 DataSet API 的,也就是我们对数据的处理转换,是看作数据集来进行操作的。事实上 Flink 本身是流批统一的处理架构,批量的数据集本质上也是流,没有必要用两套不同的 API 来实现。所以从 Flink 1.12 开始,官方推荐的做法 是直接使用 DataStream API,在提交任务时通过将执行模式设为 BATCH 来进行批处理:
bin/flink run -Dexecution.runtime-mode=BATCH BatchWordCount.jar1这样,DataSet API 就已经处于“软弃用”(soft deprecated)的状态,在实际应用中我们只要维护一套 DataStream API 就可以了。这里只是为了方便大家理解,我们依然用 DataSet API做了批处理的实现。
# 代码编写 - 流处理
public class BoundedStreamWordCount {
public static void main(String[] args) throws Exception {
// 1. 创建流式执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 2. 读取文件
DataStreamSource<String> lineDSS = env.readTextFile("bigdata_09_flink/datas/words.txt");
// 3. 转换数据格式
// 3. 转换数据格式
SingleOutputStreamOperator<Tuple2<String, Long>> wordAndOne = lineDSS
.flatMap((String line, Collector<String> words) -> {
Arrays.stream(line.split(" ")).forEach(words::collect);
})
.returns(Types.STRING)
.map(word -> Tuple2.of(word, 1L))
.returns(Types.TUPLE(Types.STRING, Types.LONG));
// 4. 分组
KeyedStream<Tuple2<String, Long>, String> wordAndOneKS = wordAndOne
.keyBy(t -> t.f0);
// 5. 求和
SingleOutputStreamOperator<Tuple2<String, Long>> result = wordAndOneKS
.sum(1);
// 6. 打印
result.print();
// 7. 执行
env.execute();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
主要观察与批处理程序 BatchWordCount 的不同:
- 创建执行环境的不同,流处理程序使用的是 StreamExecutionEnvironment。
- 每一步处理转换之后,得到的数据对象类型不同。
- 分组操作调用的是 keyBy 方法,可以传入一个匿名函数作为键选择器(KeySelector),指定当前分组的 key 是什么。
- 代码末尾需要调用 env 的 execute 方法,开始执行任务。
3> (world,1)
2> (hello,1)
4> (flink,1)
2> (hello,2)
2> (hello,3)
1> (java,1)
2
3
4
5
6
# 代码编写 - 读取文本流
public class StreamWordCount {
public static void main(String[] args) throws Exception {
// 1. 创建流式执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 2. 读取文本流
DataStreamSource<String> lineDSS = env.socketTextStream("ha01", 7777);
// 3. 数据类型转变
SingleOutputStreamOperator<Tuple2<String, Long>> wordAndOne = lineDSS.flatMap((String line, Collector<String> words) -> {
Stream.of(line.split(" ")).forEach(words::collect);
})
.returns(Types.STRING)
.map(word -> Tuple2.of(word, 1L))
.returns(Types.TUPLE(Types.STRING, Types.LONG));
// 4. 分组
KeyedStream<Tuple2<String, Long>, String> wordAndOneKS = wordAndOne
.keyBy(t -> t.f0);
// 5. 求和
SingleOutputStreamOperator<Tuple2<String, Long>> result = wordAndOneKS
.sum(1);
// 6. 打印
result.print();
// 7. 执行
env.execute();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
在 Linux 环境的主机 ha01上,执行下列命令,发送数据进行测试:
nc -lk 77771启动 StreamWordCount 程序 并发送数据
# Flink 部署
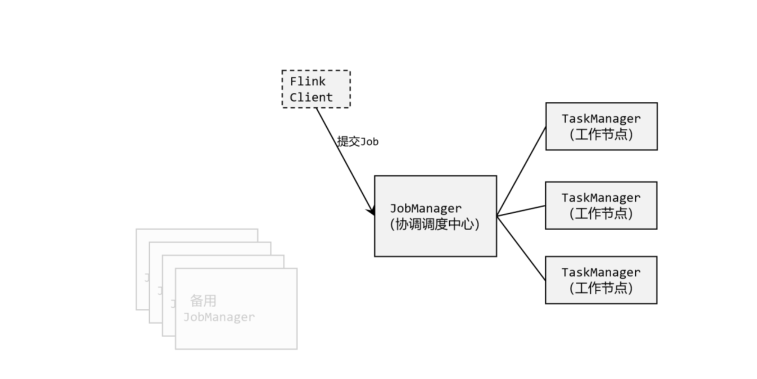
# 快速启动一个 Flink 集群
准备三台虚拟机 ha01,ha02,ha03
上传并解压文件
tar -zxvf flink-1.13.0-bin-scala_2.12.tgz -C /opt/module/1启动
bin/start-cluster.sh1访问 Web UI
http://ha01:80811关闭集群
bin/stop-cluster.sh1
# 集群启动
| 节点服务器 | ha01 | ha02 | ha03 |
|---|---|---|---|
| 角色 | JobManager | TaskManager | TaskManager |
修改集群配置 vim flink-conf.yaml
# JobManager 节点地址. jobmanager.rpc.address: ha011
2这就指定了 ha01节点服务器为 JobManager 节点
修改 workers 文件,将另外两台节点服务器添加为本 Flink 集群的 TaskManager 节点,具体修改如下:
vim workers ha02 ha031
2
3
4这样就指定了 hadoop103 和 hadoop104 为 TaskManager 节点
另外,在 flink-conf.yaml 文件中还可以对集群中的 JobManager 和 TaskManager 组件进行优化配置,主要配置项如下:
- jobmanager.memory.process.size:对 JobManager 进程可使用到的全部内存进行配置,包括 JVM 元空间和其他开销,默认为 1600M,可以根据集群规模进行适当调整。
- taskmanager.memory.process.size:对 TaskManager 进程可使用到的全部内存进行配置,包括 JVM 元空间和其他开销,默认为 1600M,可以根据集群规模进行适当调整。
- taskmanager.numberOfTaskSlots:对每个 TaskManager 能够分配的 Slot 数量进行配置,默认为 1,可根据 TaskManager 所在的机器能够提供给 Flink 的 CPU 数量决定。所谓Slot 就是 TaskManager 中具体运行一个任务所分配的计算资源。
- parallelism.default:Flink 任务执行的默认并行度,优先级低于代码中进行的并行度配置和任务提交时使用参数指定的并行度数量。
分发安装目录
启动集群
在 ha01 节点服务器上执行 start-cluster.sh 启动 Flink 集群:
bin/start-cluster.sh1访问 Web UI
http://ha01:80811
# 向集群提交作业
添加打包插件打包代码
<build> <plugins> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-assembly-plugin</artifactId> <version>3.0.0</version> <configuration> <descriptorRefs> 34 <descriptorRef>jar-with-dependencies</descriptorRef> </descriptorRefs> </configuration> <executions> <execution> <id>make-assembly</id> <phase>package</phase> <goals> <goal>single</goal> </goals> </execution> </executions> </plugin> </plugins> </build>1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24在 Web UI 上提交作业
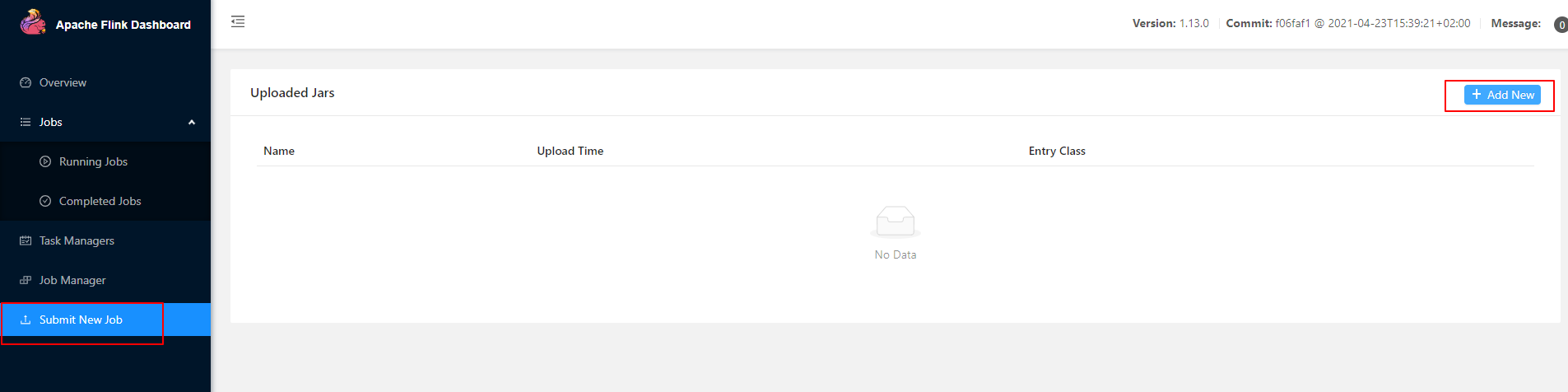
点击该 JAR 包,出现任务配置页面,进行相应配置
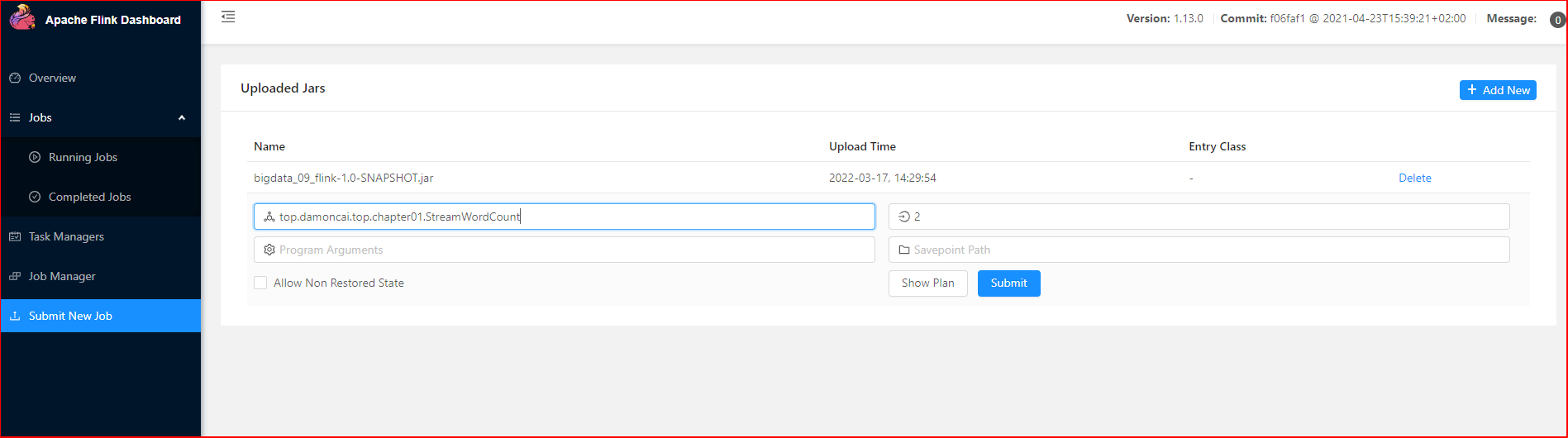
任务提交成功之后,可点击左侧导航栏的“Running Jobs”查看程序运行列表情况
# 命令行提交作业
首先需要启动集群
bin/start-cluster.sh1在 ha01 中执行以下命令启动 netcat
nc -lk 77771进入到 Flink 的安装路径下,在命令行使用 flink run 命令提交作业
bin/flink run -m ha01:8081 -c top.damoncai.top.chapter01.StreamWordCount ./FlinkTutorial-1.0-SNAPSHOT.jar1
4.用 netcat 输入数据,可以在 TaskManager 的标准输出(Stdout)看到对应的统计结果。
# 部署模式
在一些应用场景中,对于集群资源分配和占用的方式,可能会有特定的需求。Flink 为各种场景提供了不同的部署模式,主要有以下三种:
- 会话模式(Session Mode)
- 单作业模式(Per-Job Mode)
- 应用模式(Application Mode)
它们的区别主要在于:集群的生命周期以及资源的分配方式;以及应用的 main 方法到底在哪里执行——客户端(Client)还是 JobManager。接下来我们就做一个展开说明。
# 会话模式(Session Mode)
会话模式其实最符合常规思维。我们需要先启动一个集群,保持一个会话,在这个会话中通过客户端提交作业,如图 3-10 所示。集群启动时所有资源就都已经确定,所以所有提交的作业会竞争集群中的资源。
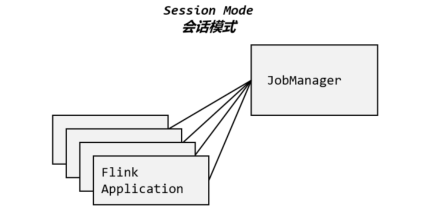
这样的好处很明显,我们只需要一个集群,就像一个大箱子,所有的作业提交之后都塞进去;集群的生命周期是超越于作业之上的,铁打的营盘流水的兵,作业结束了就释放资源,集群依然正常运行。当然缺点也是显而易见的:因为资源是共享的,所以资源不够了,提交新的作业就会失败。另外,同一个 TaskManager 上可能运行了很多作业,如果其中一个发生故障导致 TaskManager 宕机,那么所有作业都会受到影响。
我们在 3.1 节中先启动集群再提交作业,这种方式其实就是会话模式。
会话模式比较适合于单个规模小、执行时间短的大量作业。
# 单作业模式(Per-Job Mode)
会话模式因为资源共享会导致很多问题,所以为了更好地隔离资源,我们可以考虑为每个提交的作业启动一个集群,这就是所谓的单作业(Per-Job)模式,如图 3-11 所示。

单作业模式也很好理解,就是严格的一对一,集群只为这个作业而生。同样由客户端运行应用程序,然后启动集群,作业被提交给 JobManager,进而分发给 TaskManager 执行。作业作业完成后,集群就会关闭,所有资源也会释放。这样一来,每个作业都有它自己的 JobManager管理,占用独享的资源,即使发生故障,它的 TaskManager 宕机也不会影响其他作业。
这些特性使得单作业模式在生产环境运行更加稳定,所以是实际应用的首选模式。
需要注意的是,Flink 本身无法直接这样运行,所以单作业模式一般需要借助一些资源管理框架来启动集群,比如 YARN、Kubernetes。
# 应用模式(Application Mode)
前面提到的两种模式下,应用代码都是在客户端上执行,然后由客户端提交给 JobManager的。但是这种方式客户端需要占用大量网络带宽,去下载依赖和把二进制数据发送给JobManager;加上很多情况下我们提交作业用的是同一个客户端,就会加重客户端所在节点的资源消耗。
所以解决办法就是,我们不要客户端了,直接把应用提交到 JobManger 上运行。而这也就代表着,我们需要为每一个提交的应用单独启动一个 JobManager,也就是创建一个集群。这个 JobManager 只为执行这一个应用而存在,执行结束之后 JobManager 也就关闭了,这就是所谓的应用模式,如图 3-12 所示。
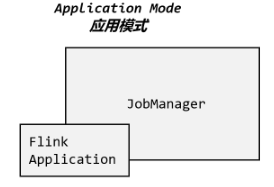
应用模式与单作业模式,都是提交作业之后才创建集群;单作业模式是通过客户端来提交的,客户端解析出的每一个作业对应一个集群;而应用模式下,是直接由 JobManager 执行应用程序的,并且即使应用包含了多个作业,也只创建一个集群。
总结一下,在会话模式下,集群的生命周期独立于集群上运行的任何作业的生命周期,并且提交的所有作业共享资源。而单作业模式为每个提交的作业创建一个集群,带来了更好的资源隔离,这时集群的生命周期与作业的生命周期绑定。最后,应用模式为每个应用程序创建一个会话集群,在 JobManager 上直接调用应用程序的 main()方法。
我们所讲到的部署模式,相对是比较抽象的概念。实际应用时,一般需要和资源管理平台结合起来,选择特定的模式来分配资源、部署应用。接下来,我们就针对不同的资源提供者(Resource Provider)的场景,具体介绍 Flink 的部署方式。
# 独立模式(Standalone)
独立模式(Standalone)是部署 Flink 最基本也是最简单的方式:所需要的所有 Flink 组件,都只是操作系统上运行的一个 JVM 进程。
独立模式是独立运行的,不依赖任何外部的资源管理平台;当然独立也是有代价的:如果资源不足,或者出现故障,没有自动扩展或重分配资源的保证,必须手动处理。所以独立模式一般只用在开发测试或作业非常少的场景下。
另外,我们也可以将独立模式的集群放在容器中运行。Flink 提供了独立模式的容器化部署方式,可以在 Docker 或者 Kubernetes 上进行部署。
# 会话模式部署
可以发现,独立模式的特点是不依赖外部资源管理平台,而会话模式的特点是先启动集群、后提交作业。所以,我们在第 3.1 节用的就是独立模式(Standalone)的会话模式部署。
# 单作业模式部署
在 3.2.2 节中我们提到,Flink 本身无法直接以单作业方式启动集群,一般需要借助一些资源管理平台。所以 Flink 的独立(Standalone)集群并不支持单作业模式部署。
# 应用模式部署
应用模式下不会提前创建集群,所以不能调用 start-cluster.sh 脚本。我们可以使用同样在bin 目录下的 standalone-job.sh 来创建一个 JobManager。
具体步骤如下:
进入到 Flink 的安装路径下,将应用程序的 jar 包放到 lib/目录下。
cp ./FlinkTutorial-1.0-SNAPSHOT.jar lib/1执行以下命令,启动 JobManager。
./bin/standalone-job.sh start --job-classname com.atguigu.wc.StreamWordCount1这里我们直接指定作业入口类,脚本会到 lib 目录扫描所有的 jar 包。
同样是使用 bin 目录下的脚本,启动 TaskManager。
./bin/taskmanager.sh start1如果希望停掉集群,同样可以使用脚本,命令如下
./bin/standalone-job.sh stop ./bin/taskmanager.sh stop1
2
# 高可用(High Availability )
分布式除了提供高吞吐,另一大好处就是有更好的容错性。对于 Flink 而言,因为一般会有多个 TaskManager,即使运行时出现故障,也不需要将全部节点重启,只要尝试重启故障节点就可以了。但是我们发现,针对一个作业而言,管理它的 JobManager 却只有一个,这同样有可能出现单点故障。为了实现更好的可用性,我们需要 JobManager 做一些主备冗余,这就是所谓的高可用(High Availability,简称 HA)。
我们可以通过配置,让集群在任何时候都有一个主 JobManager 和多个备用 JobManagers,如图 3-13 所示,这样主节点故障时就由备用节点来接管集群,接管后作业就可以继续正常运行。主备 JobManager 实例之间没有明显的区别,每个 JobManager 都可以充当主节点或者备节点。
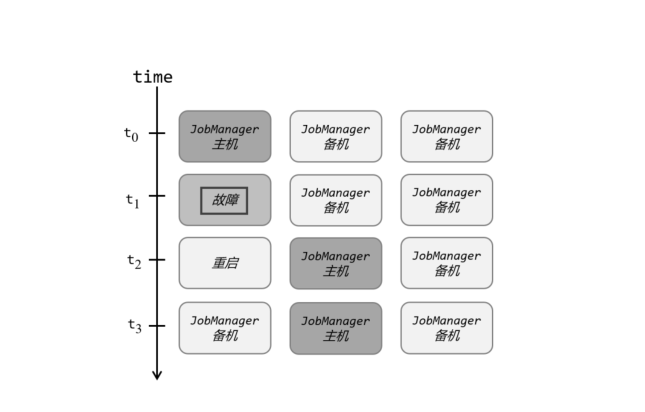
具体配置如下:
进入 Flink 的安装路径下的 conf 目录下,修改配置文件: flink-conf.yaml,增加如下配置。
high-availability: zookeeper high-availability.storageDir: hdfs://ha01:9820/flink/standalone/ha high-availability.zookeeper.quorum: ha01:2181,ha02:2181,ha03:2181 high-availability.zookeeper.path.root: /flink-standalone high-availability.cluster-id: /cluster_atguigu1
2
3
4
5
6修改配置文件: masters,配置备用 JobManager 列表。
ha01:8081 ha02:80811
2分发修改后的配置文件到其他节点服务器。
在/etc/profile.d/my_env.sh 中配置环境变量\
export HADOOP_CLASSPATH=`hadoop classpath`1注意:
- 需要提前保证 HAOOP_HOME 环境变量配置成功
- 分发到其他节点
具体部署方法如下:
首先启动 HDFS 集群和 Zookeeper 集群
执行以下命令,启动 standalone HA 集群
bin/start-cluster.sh1可以分别访问两个备用 JobManager 的 Web UI 页面
http://ha01:8081 http://ha02:80811
2在 zkCli.sh 中查看谁是 leader。
[zk: localhost:2181(CONNECTED) 1] get /flink-standalone/cluster_atguigu/leader/rest_server_lock1
2杀死 ha01上的 Jobmanager, 再看 leader。
[zk: localhost:2181(CONNECTED) 7] get /flink-standalone/cluster_atguigu/leader/rest_server_lock1
2注意: 不管是不是 leader,从 WEB UI 上是看不到区别的, 都可以提交应用。
# YARN 模式
独立(Standalone)模式由 Flink 自身提供资源,无需其他框架,这种方式降低了和其他第三方资源框架的耦合性,独立性非常强。但我们知道,Flink 是大数据计算框架,不是资源调度框架,这并不是它的强项;所以还是应该让专业的框架做专业的事,和其他资源调度框架集成更靠谱。而在目前大数据生态中,国内应用最为广泛的资源管理平台就是 YARN 了。所以接下来我们就将学习,在强大的 YARN 平台上 Flink 是如何集成部署的。
整体来说,YARN 上部署的过程是:客户端把 Flink 应用提交给 Yarn 的 ResourceManager,Yarn 的 ResourceManager 会向 Yarn 的 NodeManager 申请容器。在这些容器上,Flink 会部署JobManager 和 TaskManager 的实例,从而启动集群。Flink 会根据运行在 JobManger 上的作业所需要的 Slot 数量动态分配 TaskManager 资源。
# 相关准备和配置
在 Flink1.8.0 之前的版本,想要以 YARN 模式部署 Flink 任务时,需要 Flink 是有 Hadoop支持的。从 Flink 1.8 版本开始,不再提供基于 Hadoop 编译的安装包,若需要 Hadoop 的环境支持,需要自行在官网下载 Hadoop 相关版本的组件 flink-shaded-hadoop-2-uber-2.7.5-10.0.jar,并将该组件上传至 Flink 的 lib 目录下。在 Flink 1.11.0 版本之后,增加了很多重要新特性,其中就包括增加了对Hadoop3.0.0以及更高版本Hadoop的支持,不再提供“flink-shaded-hadoop-*”jar 包,而是通过配置环境变量完成与 YARN 集群的对接。
在将 Flink 任务部署至 YARN 集群之前,需要确认集群是否安装有 Hadoop,保证 Hadoop版本至少在 2.2 以上,并且集群中安装有 HDFS 服务。
具体配置步骤如下:
按照 3.1 节所述,下载并解压安装包,并将解压后的安装包重命名为 flink-1.13.0-yarn,本节的相关操作都将默认在此安装路径下执行
配置环境变量,增加环境变量配置如下
sudo vim /etc/profile.d/my_env.sh source /etc/profile.d/my_env.sh HADOOP_HOME=/opt/module/hadoop-2.7.5 export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop export HADOOP_CLASSPATH=`hadoop classpath`1
2
3
4
5
6
7这里必须保证设置了环境变量 HADOOP_CLASSPATH
启动 Hadoop 集群,包括 HDFS 和 YARN
start-dfs.sh start-yarn.sh1
2分别在 3 台节点服务器查看进程启动情况。
进入 conf 目录,修改 flink-conf.yaml 文件,修改以下配置,这些配置项的含义在进行 Standalone 模式配置的时候进行过讲解,若在提交命令中不特定指明,这些配置将作为默认配置。
cd /opt/module/flink-1.13.0-yarn/conf/ vim flink-conf.yaml jobmanager.memory.process.size: 1600m taskmanager.memory.process.size: 1728m taskmanager.numberOfTaskSlots: 8 parallelism.default: 11
2
3
4
5
6
7
# 会话模式部署
YARN 的会话模式与独立集群略有不同,需要首先申请一个 YARN 会话(YARN session)来启动 Flink 集群。具体步骤如下:
启动集群
启动 hadoop 集群(HDFS, YARN)
执行脚本命令向 YARN 集群申请资源,开启一个 YARN 会话,启动 Flink 集群
bin/yarn-session.sh -nm test1可用参数解读:
- -d:分离模式,如果你不想让 Flink YARN 客户端一直前台运行,可以使用这个参数,即使关掉当前对话窗口,YARN session 也可以后台运行。
- -jm(--jobManagerMemory):配置 JobManager 所需内存,默认单位 MB。
- -nm(--name):配置在 YARN UI 界面上显示的任务名。
- -qu(--queue):指定 YARN 队列名。
- -tm(--taskManager):配置每个 TaskManager 所使用内存
注意:Flink1.11.0 版本不再使用-n 参数和-s 参数分别指定 TaskManager 数量和 slot 数量,YARN 会按照需求动态分配 TaskManager 和 slot。所以从这个意义上讲,YARN 的会话模式也不会把集群资源固定,同样是动态分配的。
YARN Session启动之后会给出一个web UI地址以及一个YARN application ID,用户可以通过 web UI 或者命令行两种方式提交作业。
提交作业
通过 Web UI 提交作业
这种方式比较简单,与上文所述 Standalone 部署模式基本相同。
通过命令行提交作业
将 Standalone 模式讲解中打包好的任务运行 JAR 包上传至集群
执行以下命令将该任务提交到已经开启的 Yarn-Session 中运行
bin/flink run -c com.atguigu.wc.StreamWordCount FlinkTutorial-1.0-SNAPSHOT.jar1客户端可以自行确定 JobManager 的地址,也可以通过-m 或者-jobmanager 参数指定JobManager 的地址,JobManager 的地址在 YARN Session 的启动页面中可以找到。
任务提交成功后,可在 YARN 的 Web UI 界面查看运行情况

从图中可以看到我们创建的 Yarn-Session 实际上是一个 Yarn 的Application,并且有唯一的 Application ID
也可以通过 Flink 的 Web UI 页面查看提交任务的运行情况,如图 3-15 所示。

# 单作业模式部署
在 YARN 环境中,由于有了外部平台做资源调度,所以我们也可以直接向 YARN 提交一个单独的作业,从而启动一个 Flink 集群。
执行命令提交作业。
bin/flink run -d -t yarn-per-job -c com.atguigu.wc.StreamWordCount FlinkTutorial-1.0-SNAPSHOT.jar1注意这里是通过参数-m yarn-cluster 指定向 YARN 集群提交任务。
在 YARN 的 ResourceManager 界面查看执行情况

可以使用命令行查看或取消作业,命令如下
./bin/flink list -t yarn-per-job -Dyarn.application.id=application_XXXX_YY ./bin/flink cancel -t yarn-per-job -Dyarn.application.id=application_XXXX_YY <jobId>1
2这里的 application_XXXX_YY 是当前应用的 ID,
是作业的 ID。注意如果取消作业,整个 Flink 集群也会停掉
# 应用模式部署
应用模式同样非常简单,与单作业模式类似,直接执行 flink run-application 命令即可
执行命令提交作业
bin/flink run-application -t yarn-application -c com.atguigu.wc.StreamWordCount FlinkTutorial-1.0-SNAPSHOT.jar1在命令行中查看或取消作业
./bin/flink list -t yarn-application -Dyarn.application.id=application_XXXX_YY ./bin/flink cancel -t yarn-application -Dyarn.application.id=application_XXXX_YY <jobId>1
2也可以通过 yarn.provided.lib.dirs 配置选项指定位置,将 jar 上传到远程
./bin/flink run-application -t yarn-application-Dyarn.provided.lib.dirs="hdfs://myhdfs/my-remote-flink-dist-dir" hdfs://myhdfs/jars/my-application.jar1
2这种方式下 jar 可以预先上传到 HDFS,而不需要单独发送到集群,这就使得作业提交更加轻量了
# 高可用
YARN 模式的高可用和独立模式(Standalone)的高可用原理不一样。Standalone 模式中, 同时启动多个 JobManager, 一个为“领导者”(leader),其他为“后备” (standby), 当 leader 挂了, 其他的才会有一个成为 leader。
而 YARN 的高可用是只启动一个 Jobmanager, 当这个 Jobmanager挂了之后, YARN 会再次启动一个, 所以其实是利用的 YARN 的重试次数来实现的高可用。
在 yarn-site.xml 中配置
<property> <name>yarn.resourcemanager.am.max-attempts</name> <value>4</value> <description> The maximum number of application master execution attempts. </description> </property>1
2
3
4
5
6
7注意: 配置完不要忘记分发, 和重启 YARN。
在 flink-conf.yaml 中配置
yarn.application-attempts: 3 high-availability: zookeeper high-availability.storageDir: hdfs://ha01:9820/flink/yarn/ha high-availability.zookeeper.quorum: ha01:2181,ha02:2181,ha03:2181 high-availability.zookeeper.path.root: /flink-yarn1
2
3
4
5
6启动 yarn-session。
杀死 JobManager, 查看复活情况
注意: yarn-site.xml 中配置的是 JobManager 重启次数的上限, flink-conf.xml 中的次数应该小于这个值
# DataStream API(基础篇)
一个 Flink 程序,其实就是对 DataStream 的各种转换。具体来说,代码基本上都由以下几部分构成
- 获取执行环境(execution environment)
- 读取数据源(source)
- 定义基于数据的转换操作(transformations)
- 定义计算结果的输出位置(sink)
- 触发程序执行(execute)
其中,获取环境和触发执行,都可以认为是针对执行环境的操作。所以本章我们就从执行环境、数据源(source)、转换操作(transformation)、输出(sink)四大部分,对常用的 DataStreamAPI 做基本介绍。

# 执行环境(Execution Environment)
# getExecutionEnvironment
最简单的方式,就是直接调用 getExecutionEnvironment 方法。它会根据当前运行的上下文直接得到正确的结果:如果程序是独立运行的,就返回一个本地执行环境;如果是创建了 jar包,然后从命令行调用它并提交到集群执行,那么就返回集群的执行环境。也就是说,这个方法会根据当前运行的方式,自行决定该返回什么样的运行环境。
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
这种“智能”的方式不需要我们额外做判断,用起来简单高效,是最常用的一种创建执行环境的方式
# createLocalEnvironment
这个方法返回一个本地执行环境。可以在调用时传入一个参数,指定默认的并行度;如果不传入,则默认并行度就是本地的 CPU 核心数
StreamExecutionEnvironment localEnv = StreamExecutionEnvironment.createLocalEnvironment();
# createRemoteEnvironment
这个方法返回集群执行环境。需要在调用时指定 JobManager 的主机名和端口号,并指定要在集群中运行的 Jar 包
StreamExecutionEnvironment remoteEnv = StreamExecutionEnvironment
.createRemoteEnvironment(
"host", // JobManager 主机名
1234, // JobManager 进程端口号
"path/to/jarFile.jar" // 提交给 JobManager 的 JAR 包
);
2
3
4
5
6
# 执行模式(Execution Mode)
# 流执行模式(STREAMING)
这是 DataStream API 最经典的模式,一般用于需要持续实时处理的无界数据流。默认情况下,程序使用的就是 STREAMING 执行模式。
# 批执行模式(BATCH)
专门用于批处理的执行模式, 这种模式下,Flink 处理作业的方式类似于 MapReduce 框架。对于不会持续计算的有界数据,我们用这种模式处理会更方便。
# 自动模式(AUTOMATIC)
在这种模式下,将由程序根据输入数据源是否有界,来自动选择执行模式。
# BATCH 模式的配置方法
由于 Flink 程序默认是 STREAMING 模式,我们这里重点介绍一下 BATCH 模式的配置。主要有两种方式:
通过命令行配置
bin/flink run -Dexecution.runtime-mode=BATCH ...1在提交作业时,增加 execution.runtime-mode 参数,指定值为 BATCH。
通过代码配置
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setRuntimeMode(RuntimeExecutionMode.BATCH);1
2在代码中,直接基于执行环境调用 setRuntimeMode 方法,传入 BATCH 模式。
# 源算子(Source)
# 准备工作
创建Event类
public class Event { public String user; public String url; public Long timestamp; public Event() { } public Event(String user, String url, Long timestamp) { this.user = user; this.url = url; this.timestamp = timestamp; } @Override public String toString() { return "Event{" + "user='" + user + '\'' + ", url='" + url + '\'' + ", timestamp=" + new Timestamp(timestamp) + '}'; } }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20- 类是公有(public)的
- 有一个无参的构造方法
- 所有属性都是公有(public)的
- 所有属性的类型都是可以序列化的
# 从集合中读取数据
public class Demo_01_Source_Collection {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
List<Event> events = Arrays.asList(
new Event("Mary", "./home", 1000L),
new Event("Bob", "./cart", 2000L)
);
DataStreamSource<Event> stream = env.fromCollection(events);
//我们也可以不构建集合,直接将元素列举出来,调用 fromElements 方法进行读取数据
DataStreamSource<Event> stream2 = env.fromElements(
new Event("Mary", "./home", 1000L),
new Event("Bob", "./cart", 2000L)
);
stream.print("1");
stream2.print("2");
env.execute();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
# 从文件读取数据
DataStream<String> stream = env.readTextFile("clicks.csv");
参数可以是目录,也可以是文件;
路径可以是相对路径,也可以是绝对路径;
相对路径是从系统属性 user.dir 获取路径: idea 下是 project 的根目录, standalone 模式 下是集群节点根目录;
也可以从 hdfs 目录下读取, 使用路径 hdfs://..., 由于 Flink 没有提供 hadoop 相关依赖,需要 pom 中添加相关依赖:
<dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>2.7.5</version> <scope>provided</scope> </dependency>1
2
3
4
5
6
# 从 Socket 读取数据
DataStream<String> stream = env.socketTextStream("localhost", 7777);
# 从 Kafka 读取数据
Kafka 作为分布式消息传输队列,是一个高吞吐、易于扩展的消息系统。而消息队列的传输方式,恰恰和流处理是完全一致的。所以可以说 Kafka 和 Flink 天生一对,是当前处理流式数据的双子星。在如今的实时流处理应用中,由 Kafka 进行数据的收集和传输,Flink 进行分析计算,这样的架构已经成为众多企业的首选

略微遗憾的是,与 Kafka 的连接比较复杂,Flink 内部并没有提供预实现的方法。所以我们只能采用通用的 addSource 方式、实现一个 SourceFunction 了
好在Kafka与Flink确实是非常契合,所以Flink官方提供了连接工具flink-connector-kafka,直接帮我们实现了一个消费者 FlinkKafkaConsumer,它就是用来读取 Kafka 数据的SourceFunction。
所以想要以 Kafka 作为数据源获取数据,我们只需要引入 Kafka 连接器的依赖。Flink 官方提供的是一个通用的 Kafka 连接器,它会自动跟踪最新版本的 Kafka 客户端。目前最新版本只支持 0.10.0 版本以上的 Kafka,读者使用时可以根据自己安装的 Kafka 版本选定连接器的依赖版本。这里我们需要导入的依赖如下。
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
2
3
4
5
然后调用 env.addSource(),传入 FlinkKafkaConsumer 的对象实例就可以了。
public class Demo_02_Source_Kafka {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "ha01:9092,ha02:9092,ha03:9092");
properties.setProperty("group.id", "consumer-group");
properties.setProperty("key.deserializer",
"org.apache.kafka.common.serialization.StringDeserializer");
properties.setProperty("value.deserializer",
"org.apache.kafka.common.serialization.StringDeserializer");
properties.setProperty("auto.offset.reset", "latest");
DataStreamSource<String> stream = env.addSource(new FlinkKafkaConsumer<String>(
"click",
new SimpleStringSchema(),
properties
));
stream.print("Kafka");
env.execute();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
创建 FlinkKafkaConsumer 时需要传入三个参数:
- 第一个参数 topic,定义了从哪些主题中读取数据。可以是一个 topic,也可以是 topic列表,还可以是匹配所有想要读取的 topic 的正则表达式。当从多个 topic 中读取数据时,Kafka 连接器将会处理所有 topic 的分区,将这些分区的数据放到一条流中去。
- 第二个参数是一个 DeserializationSchema 或者 KeyedDeserializationSchema。Kafka 消息被存储为原始的字节数据,所以需要反序列化成 Java 或者 Scala 对象。上面代码中使用的 SimpleStringSchema,是一个内置的 DeserializationSchema,它只是将字节数组简单地反序列化成字符串。DeserializationSchema 和 KeyedDeserializationSchema 是公共接口,所以我们也可以自定义反序列化逻辑。
- 第三个参数是一个 Properties 对象,设置了 Kafka 客户端的一些属性。
# 自定义 Source
大多数情况下,前面的数据源已经能够满足需要。但是凡事总有例外,如果遇到特殊情况,我们想要读取的数据源来自某个外部系统,而 flink 既没有预实现的方法、也没有提供连接器,又该怎么办呢
那就只好自定义实现 SourceFunction 了
接下来我们创建一个自定义的数据源,实现 SourceFunction 接口。主要重写两个关键方法:run()和 cancel()
- run()方法:使用运行时上下文对象(SourceContext)向下游发送数据
- cancel()方法:通过标识位控制退出循环,来达到中断数据源的效果
自定义数据源
public class Demo_03_Source_Customer {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<Event> stream = env.addSource(new ClickSource());
stream.print();
env.execute();
}
}
class ClickSource implements SourceFunction<Event> {
// 声明一个布尔变量,作为控制数据生成的标识位
private Boolean running = true;
@Override
public void run(SourceContext<Event> ctx) throws Exception {
Random random = new Random(); // 在指定的数据集中随机选取数据
String[] users = {"Mary", "Alice", "Bob", "Cary"};
String[] urls = {"./home", "./cart", "./fav", "./prod?id=1", "./prod?id=2"};
while (running) {
ctx.collect(new Event(
users[random.nextInt(users.length)],
urls[random.nextInt(urls.length)],
Calendar.getInstance().getTimeInMillis()
));
// 隔 2 秒生成一个点击事件,方便观测
Thread.sleep(2000);
}
}
@Override
public void cancel() {
running = false;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
这里要注意的是 SourceFunction 接口定义的数据源,并行度只能设置为 1,如果数据源设置为大于 1 的并行度,则会抛出异常。如下程序所示:
public class Demo_03_Source_Customer {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<Event> stream = env.addSource(new ClickSource()).setParallelism(2);
stream.print();
env.execute();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
输出的异常如下:
Exception in thread "main" java.lang.IllegalArgumentException: The parallelism of non parallel operator must be 1.
所以如果我们想要自定义并行的数据源的话,需要使用 ParallelSourceFunction,示例程序如下:
public class Demo_04_Source_Customer_Parallel {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<Integer> stream = env.addSource(new CustomSource()).setParallelism(2);
stream.print();
env.execute();
}
}
class CustomSource implements ParallelSourceFunction<Integer>
{
private boolean running = true;
private Random random = new Random();
@Override
public void run(SourceContext<Integer> sourceContext) throws Exception {
while (running) {
sourceContext.collect(random.nextInt());
}
}
@Override
public void cancel() {
running = false;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
# Flink 支持的数据类型
简单来说,对于常见的 Java 和 Scala 数据类型,Flink 都是支持的。Flink 在内部,Flink对支持不同的类型进行了划分,这些类型可以在 Types 工具类中找到:
基本类型
所有 Java 基本类型及其包装类,再加上 Void、String、Date、BigDecimal 和 BigInteger。
数组类型
包括基本类型数组(PRIMITIVE_ARRAY)和对象数组(OBJECT_ARRAY)
复合数据类型
- Java 元组类型(TUPLE):这是 Flink 内置的元组类型,是 Java API 的一部分。最多25 个字段,也就是从 Tuple0~Tuple25,不支持空字段
- Scala 样例类及 Scala 元组:不支持空字段
- 行类型(ROW):可以认为是具有任意个字段的元组,并支持空字段
- POJO:Flink 自定义的类似于 Java bean 模式的类
辅助类型
Option、Either、List、Map 等
泛型类型(GENERIC)
Flink 支持所有的 Java 类和 Scala 类。不过如果没有按照上面 POJO 类型的要求来定义,就会被 Flink 当作泛型类来处理。Flink 会把泛型类型当作黑盒,无法获取它们内部的属性;它们也不是由 Flink 本身序列化的,而是由 Kryo 序列化的
在这些类型中,元组类型和 POJO 类型最为灵活,因为它们支持创建复杂类型。而相比之下,POJO 还支持在键(key)的定义中直接使用字段名,这会让我们的代码可读性大大增加。所以,在项目实践中,往往会将流处理程序中的元素类型定为 Flink 的 POJO 类型
Flink 对 POJO 类型的要求如下:
- 类是公共的(public)和独立的(standalone,也就是说没有非静态的内部类);
- 类有一个公共的无参构造方法;
- 类中的所有字段是 public 且非 final 的;或者有一个公共的 getter 和 setter 方法,这些方法需要符合 Java bean 的命名规范。
所以我们看到,之前的 UserBehavior,就是我们创建的符合 Flink POJO 定义的数据类型
类型提示(Type Hints)
.map(word -> Tuple2.of(word, 1L)) .returns(Types.TUPLE(Types.STRING, Types.LONG));1
2二元组的两个元素都是基本数据类型。那如果元组中的一个元素又有泛型,该怎么处理呢
Flink 专门提供了 TypeHint 类,它可以捕获泛型的类型信息,并且一直记录下来,为运行时提供足够的信息。我们同样可以通过.returns()方法,明确地指定转换之后的 DataStream 里元素的类型
returns(new TypeHint<Tuple2<Integer, SomeType>>(){})1
# 转换算子(Transformation)
# 基本转换算子
# 映射(map )
public class Demo_01_Transform_Map {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<Event> stream = env.fromElements(
new Event("Mary", "./home", 1000L),
new Event("Bob", "./cart", 2000L)
);
SingleOutputStreamOperator<String> map = stream.map(line -> line.user);
map.print();
env.execute();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# 过滤(filter )
public class Demo_02_Transform_Filter {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<Event> stream = env.fromElements(
new Event("Mary", "./home", 1000L),
new Event("Bob", "./cart", 2000L)
);
SingleOutputStreamOperator<Event> events = stream.filter(line -> line.timestamp > 1000L);
events.print();
env.execute();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# 扁平映射(flatMap )
public class Demo_02_Transform_FlatMap {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<Event> stream = env.fromElements(
new Event("Mary", "./home", 1000L),
new Event("Bob", "./cart", 2000L)
);
SingleOutputStreamOperator<String> flatMap = stream.flatMap(
(Event event, Collector<String> out) -> {
out.collect(event.user);
out.collect(event.url);
out.collect(event.timestamp + "");
}
).returns(new TypeHint<String>() {});
flatMap.print();
env.execute();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
# 聚合算子(Aggregation)
# 按键分区(keyBy )
在内部,是通过计算 key 的哈希值(hash code),对分区数进行取模运算来实现的。所以这里 key 如果是 POJO 的话,必须要重写 hashCode()方法。
keyBy()方法需要传入一个参数,这个参数指定了一个或一组 key。有很多不同的方法来指定 key:比如对于 Tuple 数据类型,可以指定字段的位置或者多个位置的组合;对于 POJO 类型,可以指定字段的名称(String);另外,还可以传入 Lambda 表达式或者实现一个键选择器(KeySelector),用于说明从数据中提取key 的逻辑。
public class Demo_04_Aggregation_Keyby {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<Event> stream = env.fromElements(
new Event("Mary", "./home", 1000L),
new Event("Bob", "./cart", 2000L),
new Event("Mary", "./cart", 3000L)
);
KeyedStream<Event, String> keyBy = stream.keyBy(event -> event.user);
keyBy.print();
env.execute();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
需要注意的是,keyBy 得到的结果将不再是 DataStream,而是会将 DataStream 转换为KeyedStream。KeyedStream 可以认为是“分区流”或者“键控流”,它是对 DataStream 按照key 的一个逻辑分区,所以泛型有两个类型:除去当前流中的元素类型外,还需要指定 key 的类型。
KeyedStream 也继承自 DataStream,所以基于它的操作也都归属于 DataStream API。但它跟之前的转换操作得到的 SingleOutputStreamOperator 不同,只是一个流的分区操作,并不是一个转换算子。KeyedStream 是一个非常重要的数据结构,只有基于它才可以做后续的聚合操作(比如 sum,reduce);而且它可以将当前算子任务的状态(state)也按照 key 进行划分、限定为仅对当前 key 有效。关于状态的相关知识我们会在后面章节继续讨论。
# 简单聚合
有了按键分区的数据流 KeyedStream,我们就可以基于它进行聚合操作了。Flink 为我们内置实现了一些最基本、最简单的聚合 API,主要有以下几种:
- sum():在输入流上,对指定的字段做叠加求和的操作。
- min():在输入流上,对指定的字段求最小值。
- max():在输入流上,对指定的字段求最大值。
- minBy():与 min()类似,在输入流上针对指定字段求最小值。不同的是,min()只计算指定字段的最小值,其他字段会保留最初第一个数据的值;而 minBy()则会返回包含字段最小值的整条数据。
- maxBy():与 max()类似,在输入流上针对指定字段求最大值。两者区别与min()/minBy()完全一致。
简单聚合算子使用非常方便,语义也非常明确。这些聚合方法调用时,也需要传入参数;但并不像基本转换算子那样需要实现自定义函数,只要说明聚合指定的字段就可以了。指定字段的方式有两种:指定位置,和指定名称。
对于元组类型的数据,同样也可以使用这两种方式来指定字段。需要注意的是,元组中字段的名称,是以 f0、f1、f2、…来命名的
public class Demo_05_Aggregation_Sum_Min_Minby_Max_Maxby {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<Tuple2<String, Integer>> stream = env.fromElements(
Tuple2.of("a", 1),
Tuple2.of("a", 3),
Tuple2.of("b", 3),
Tuple2.of("b", 4)
);
stream.keyBy(r -> r.f0).sum(1).print();
stream.keyBy(r -> r.f0).sum("f1").print();
stream.keyBy(r -> r.f0).max(1).print();
stream.keyBy(r -> r.f0).max("f1").print();
stream.keyBy(r -> r.f0).min(1).print();
stream.keyBy(r -> r.f0).min("f1").print();
stream.keyBy(r -> r.f0).maxBy(1).print();
stream.keyBy(r -> r.f0).maxBy("f1").print();
stream.keyBy(r -> r.f0).minBy(1).print();
stream.keyBy(r -> r.f0).minBy("f1").print();
env.execute();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
而如果数据流的类型是 POJO 类,那么就只能通过字段名称来指定,不能通过位置来指定了。
简单聚合算子返回的,同样是一个 SingleOutputStreamOperator,也就是从 KeyedStream 又转换成了常规的 DataStream。所以可以这样理解:keyBy 和聚合是成对出现的,先分区、后聚合,得到的依然是一个 DataStream。而且经过简单聚合之后的数据流,元素的数据类型保持不变。
一个聚合算子,会为每一个key保存一个聚合的值,在Flink中我们把它叫作“状态” (state)。所以每当有一个新的数据输入,算子就会更新保存的聚合结果,并发送一个带有更新后聚合值的事件到下游算子。对于无界流来说,这些状态是永远不会被清除的,所以我们使用聚合算子,应该只用在含有有限个 key 的数据流上。
# 归约聚合(reduce )
public class Demo_06_Aggregation_Reduce {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<Tuple2<String, Integer>> stream = env.fromElements(
Tuple2.of("a", 1),
Tuple2.of("a", 3),
Tuple2.of("b", 3),
Tuple2.of("b", 4)
);
SingleOutputStreamOperator<Tuple2<String, Integer>> reduce =
stream
.keyBy(tuple -> tuple.f0)
.reduce((e1, e2) -> Tuple2.of(e1.f0, e1.f1 + e2.f1));
reduce.print();
env.execute();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
# 用户自定义函数(UDF)
前面的介绍我们可以发现,Flink 的 DataStream API 编程风格其实是一致的:基本上都是基于 DataStream 调用一个方法,表示要做一个转换操作;方法需要传入一个参数,这个参数都是需要实现一个接口。我们还可以扩展到 5.2 节讲到的 Source 算子,其实也是需要自定义类实现一个 SourceFunction 接口。我们能否从中总结出一些规律呢?
很容易发现,这些接口有一个共同特点:全部都以算子操作名称 + Function 命名,例如源算子需要实现 SourceFunction 接口,map 算子需要实现 MapFunction 接口,reduce 算子需要实现 ReduceFunction 接口。而且查看源码会发现,它们都继承自 Function 接口;这个接口是空的,主要就是为了方便扩展为单一抽象方法(Single Abstract Method,SAM)接口,这就是我们所说的“函数接口”——比如 MapFunction 中需要实现一个 map()方法,ReductionFunction中需要实现一个 reduce()方法,它们都是 SAM 接口。我们知道,Java 8 新增的 Lambda 表达式就可以实现 SAM 接口;所以这样的好处就是,我们不仅可以通过自定义函数类或者匿名类来实现接口,也可以直接传入 Lambda 表达式。这就是所谓的用户自定义函数(user-definedfunction,UDF)。
接下来我们就对这几种编程方式做一个梳理总结。
# 函数类(Function Classes)
对于大部分操作而言,都需要传入一个用户自定义函数(UDF),实现相关操作的接口,来完成处理逻辑的定义。Flink 暴露了所有 UDF 函数的接口,具体实现方式为接口或者抽象类,例如 MapFunction、FilterFunction、ReduceFunction 等
所以最简单直接的方式,就是自定义一个函数类,实现对应的接口。之前我们对于 API的练习,主要就是基于这种方式
# 匿名函数(Lambda )
例如flatMap函数可能存在泛型擦除导致报错
解决方案:
- 使用显式的 ".returns(...)"
- 使用类来替代 Lambda 表达式
- 使用匿名类来代替 Lambda 表达式
# 富函数类(Rich Function Classes)
“富函数类”也是 DataStream API 提供的一个函数类的接口,所有的 Flink 函数类都有其Rich 版本。富函数类一般是以抽象类的形式出现的。例如:RichMapFunction、RichFilterFunction、RichReduceFunction 等。
既然“富”,那么它一定会比常规的函数类提供更多、更丰富的功能。与常规函数类的不同主要在于,富函数类可以获取运行环境的上下文,并拥有一些生命周期方法,所以可以实现更复杂的功能。
Rich Function 有生命周期的概念。典型的生命周期方法有:
- open()方法,是 Rich Function 的初始化方法,也就是会开启一个算子的生命周期。当一个算子的实际工作方法例如 map()或者 filter()方法被调用之前,open()会首先被调用。所以像文件 IO 的创建,数据库连接的创建,配置文件的读取等等这样一次性的工作,都适合在 open()方法中完成。
- close()方法,是生命周期中的最后一个调用的方法,类似于解构方法。一般用来做一些清理工作。
需要注意的是,这里的生命周期方法,对于一个并行子任务来说只会调用一次;而对应的,实际工作方法,例如 RichMapFunction 中的 map(),在每条数据到来后都会触发一次调用。
public class Demo_07_Transform_RichMapFunction {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DataStreamSource<Event> stream = env.fromElements(
new Event("Mary", "./home", 1000L),
new Event("Bob", "./cart", 2000L)
);
SingleOutputStreamOperator<Integer> myMap = stream.map(new MyMap()).setParallelism(2);
myMap.print();
env.execute();
}
}
class MyMap extends RichMapFunction<Event,Integer> {
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
System.out.println("open:" + getRuntimeContext().getIndexOfThisSubtask() + "号启动了");
}
@Override
public Integer map(Event event) throws Exception {
return event.user.length();
}
@Override
public void close() throws Exception {
super.close();
System.out.println("close:" + getRuntimeContext().getIndexOfThisSubtask() + "号关闭了");
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
open和close调用次数和并行度setParallelism()有关
另外,富函数类提供了 getRuntimeContext()方法(我们在本节的第一个例子中使用了一下),可以获取到运行时上下文的一些信息,例如程序执行的并行度,任务名称,以及状态(state)。这使得我们可以大大扩展程序的功能,特别是对于状态的操作,使得 Flink 中的算子具备了处理复杂业务的能力。关于 Flink 中的状态管理和状态编程,我们会在后续章节逐渐展开。
# 物理分区(Physical Partitioning)
“分区”(partitioning)操作就是要将数据进行重新分布,传递到不同的流分区去进行下一步处理。其实我们对分区操作并不陌生,前面介绍聚合算子时,已经提到了 keyBy,它就是一种按照键的哈希值来进行重新分区的操作。只不过这种分区操作只能保证把数据按key“分开”,至于分得均不均匀、每个 key 的数据具体会分到哪一区去,这些是完全无从控制的——所以我们有时也说,keyBy 是一种逻辑分区(logical partitioning)操作。
如果说 keyBy 这种逻辑分区是一种“软分区”,那真正硬核的分区就应该是所谓的“物理分区”(physical partitioning)。也就是我们要真正控制分区策略,精准地调配数据,告诉每个数据到底去哪里。其实这种分区方式在一些情况下已经在发生了:例如我们编写的程序可能对多个处理任务设置了不同的并行度,那么当数据执行的上下游任务并行度变化时,数据就不应该还在当前分区以直通(forward)方式传输了——因为如果并行度变小,当前分区可能没有下游任务了;而如果并行度变大,所有数据还在原先的分区处理就会导致资源的浪费。所以这种情况下,系统会自动地将数据均匀地发往下游所有的并行任务,保证各个分区的负载均衡。
有些时候,我们还需要手动控制数据分区分配策略。比如当发生数据倾斜的时候,系统无法自动调整,这时就需要我们重新进行负载均衡,将数据流较为平均地发送到下游任务操作分区中去。Flink 对于经过转换操作之后的 DataStream,提供了一系列的底层操作接口,能够帮我们实现数据流的手动重分区。为了同 keyBy 相区别,我们把这些操作统称为“物理分区”操作。物理分区与 keyBy 另一大区别在于,keyBy 之后得到的是一个 KeyedStream,而物理分区之后结果仍是 DataStream,且流中元素数据类型保持不变。从这一点也可以看出,分区算子并不对数据进行转换处理,只是定义了数据的传输方式。
常见的物理分区策略有随机分配(Random)、轮询分配(Round-Robin)、重缩放(Rescale)和广播(Broadcast),下边我们分别来做了解。
# 随机分区(shuffle)
最简单的重分区方式就是直接“洗牌”。通过调用 DataStream 的.shuffle()方法,将数据随机地分配到下游算子的并行任务中去
随机分区服从均匀分布(uniform distribution),所以可以把流中的数据随机打乱,均匀地传递到下游任务分区,如图 5-9 所示。因为是完全随机的,所以对于同样的输入数据, 每次执行得到的结果也不会相同。
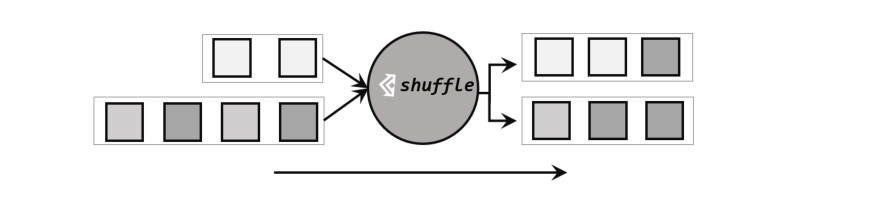
经过随机分区之后,得到的依然是一个 DataStream。
我们可以做个简单测试:将数据读入之后直接打印到控制台,将输出的并行度设置为 4,中间经历一次 shuffle。执行多次,观察结果是否相同。
public class Demo_08_Partition_Shuffle {
public static void main(String[] args) throws Exception {
// 创建执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 读取数据源,并行度为 1
DataStreamSource<Event> stream = env.addSource(new Demo_03_Source_Customer.ClickSource());
// 经洗牌后打印输出,并行度为 4
stream.shuffle().print("shuffle").setParallelism(4);
env.execute();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
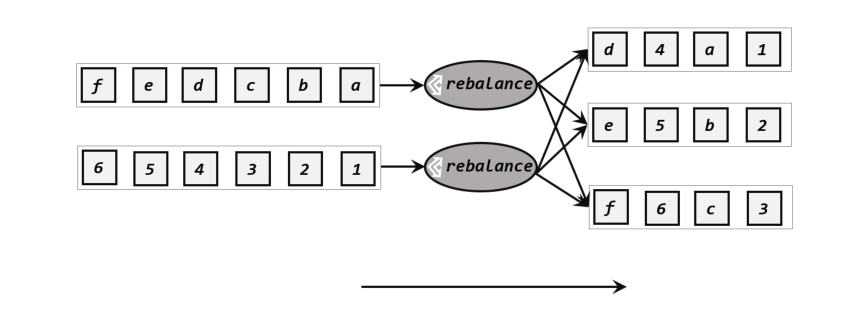
# 轮询分区(Round-Robin )
轮询也是一种常见的重分区方式。简单来说就是“发牌”,按照先后顺序将数据做依次分发,通过调用 DataStream 的.rebalance()方法,就可以实现轮询重分区。rebalance使用的是 Round-Robin 负载均衡算法,可以将输入流数据平均分配到下游的并行任务中去。 注:Round-Robin 算法用在了很多地方,例如 Kafka 和 Nginx。
public class Demo_09_Partition_Round_Robin {
public static void main(String[] args) throws Exception {
// 创建执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 读取数据源,并行度为 1
DataStreamSource<Event> stream = env.addSource(new Demo_03_Source_Customer.ClickSource());
// 经洗牌后打印输出,并行度为 4
stream.rebalance().print("Round-Robin").setParallelism(4);
env.execute();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
# 重缩放分区(rescale)
重缩放分区和轮询分区非常相似。当调用 rescale()方法时,其实底层也是使用 Round-Robin算法进行轮询,但是只会将数据轮询发送到下游并行任务的一部分中,也就是说,“发牌人”如果有多个,那么 rebalance 的方式是每个发牌人都面向所有人发牌;而 rescale的做法是分成小团体,发牌人只给自己团体内的所有人轮流发牌。
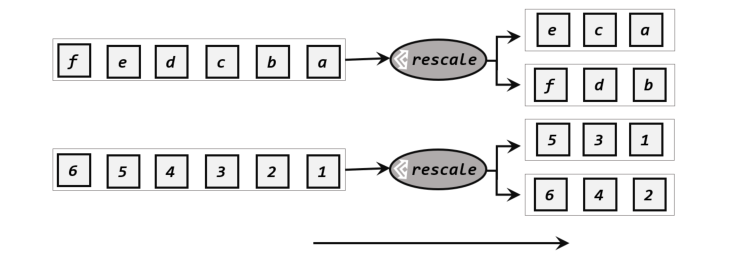
当下游任务(数据接收方)的数量是上游任务(数据发送方)数量的整数倍时,rescale的效率明显会更高。比如当上游任务数量是 2,下游任务数量是 6 时,上游任务其中一个分区的数据就将会平均分配到下游任务的 3 个分区中。
由于 rebalance 是所有分区数据的“重新平衡”,当 TaskManager 数据量较多时,这种跨节点的网络传输必然影响效率;而如果我们配置的 task slot 数量合适,用 rescale 的方式进行“局部重缩放”,就可以让数据只在当前 TaskManager 的多个 slot 之间重新分配,从而避免了网络传输带来的损耗。
从底层实现上看,rebalance 和 rescale 的根本区别在于任务之间的连接机制不同。rebalance将会针对所有上游任务(发送数据方)和所有下游任务(接收数据方)之间建立通信通道,这是一个笛卡尔积的关系;而 rescale 仅仅针对每一个任务和下游对应的部分任务之间建立通信通道,节省了很多资源。
public class Demo_10_Partition_Rescale {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 这里使用了并行数据源的富函数版本
// 这样可以调用 getRuntimeContext 方法来获取运行时上下文的一些信息
env
.addSource(new RichParallelSourceFunction<Integer>() {
@Override
public void run(SourceContext<Integer> sourceContext) throws
Exception {
for (int i = 0; i < 8; i++) {
// 将奇数发送到索引为 1 的并行子任务
// 将偶数发送到索引为 0 的并行子任务
if ((i + 1) % 2 ==
getRuntimeContext().getIndexOfThisSubtask()) {
sourceContext.collect(i + 1);
}
}
}
@Override
public void cancel() {
}
})
.setParallelism(2)
.rescale()
.print().setParallelism(4);
env.execute();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
# 广播(broadcast
这种方式其实不应该叫做“重分区”,因为经过广播之后,数据会在不同的分区都保留一份,可能进行重复处理。可以通过调用 DataStream 的 broadcast()方法,将输入数据复制并发送到下游算子的所有并行任务中去。
public class Demo_11_Partition_Broadcast {
public static void main(String[] args) throws Exception {
// 创建执行环境
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 读取数据源,并行度为 1
DataStreamSource<Event> stream = env.addSource(new Demo_03_Source_Customer.ClickSource());
// 经广播后打印输出,并行度为 4
stream. broadcast().print("broadcast").setParallelism(4);
env.execute();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
# 全局分区(global )
全局分区也是一种特殊的分区方式。这种做法非常极端,通过调用.global()方法,会将所有的输入流数据都发送到下游算子的第一个并行子任务中去。这就相当于强行让下游任务并行度变成了 1,所以使用这个操作需要非常谨慎,可能对程序造成很大的压力。
# 自定义分区(Custom)
当 Flink 提供的所有分区策略都不能满足用户的需求时,我们可以通过使用partitionCustom()方法来自定义分区策略。
在调用时,方法需要传入两个参数,第一个是自定义分区器(Partitioner)对象,第二个是应用分区器的字段,它的指定方式与 keyBy 指定 key 基本一样:可以通过字段名称指定,也可以通过字段位置索引来指定,还可以实现一个 KeySelector。
public class Demo_12_Partition_Customer {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 将自然数按照奇偶分区
env.fromElements(1, 2, 3, 4, 5, 6, 7, 8)
.partitionCustom(new Partitioner<Integer>() {
@Override
public int partition(Integer key, int numPartitions) {
return key % 2;
}
}, new KeySelector<Integer, Integer>() {
@Override
public Integer getKey(Integer value) throws Exception {
return value;
}
})
.print().setParallelism(4);
env.execute();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
# 输出算子(Sink)
在 Flink 中,如果我们希望将数据写入外部系统,其实并不是一件难事。我们知道所有算子都可以通过实现函数类来自定义处理逻辑,所以只要有读写客户端,与外部系统的交互在任何一个处理算子中都可以实现。例如在 MapFunction 中,我们完全可以构建一个到 Redis 的连接,然后将当前处理的结果保存到 Redis 中。如果考虑到只需建立一次连接,我们也可以利用RichMapFunction,在 open() 生命周期中做连接操作。
这样看起来很方便,却会带来很多问题。Flink 作为一个快速的分布式实时流处理系统,对稳定性和容错性要求极高。一旦出现故障,我们应该有能力恢复之前的状态,保障处理结果的正确性。这种性质一般被称作“状态一致性”。Flink 内部提供了一致性检查点(checkpoint)来保障我们可以回滚到正确的状态;但如果我们在处理过程中任意读写外部系统,发生故障后就很难回退到从前了。
为了避免这样的问题,Flink 的 DataStream API 专门提供了向外部写入数据的方法:addSink。与 addSource 类似,addSink 方法对应着一个“Sink”算子,主要就是用来实现与外部系统连接、并将数据提交写入的;Flink 程序中所有对外的输出操作,一般都是利用 Sink 算子完成的。
Sink 一词有“下沉”的意思,有些资料会相对于“数据源”把它翻译为“数据汇”。不论怎样理解,Sink 在 Flink 中代表了将结果数据收集起来、输出到外部的意思,所以我们这里统一把它直观地叫作“输出算子”。
之前我们一直在使用的 print 方法其实就是一种 Sink,它表示将数据流写入标准控制台打印输出。查看源码可以发现,print 方法返回的就是一个 DataStreamSink。
public DataStreamSink<T> print(String sinkIdentifier) {
PrintSinkFunction<T> printFunction = new PrintSinkFunction<>(sinkIdentifier,
false);
return addSink(printFunction).name("Print to Std. Out");
}
2
3
4
5
与 Source 算子非常类似,除去一些 Flink 预实现的 Sink,一般情况下 Sink 算子的创建是通过调用 DataStream 的.addSink()方法实现的。
stream.addSink(new SinkFunction(…));
addSource 的参数需要实现一个 SourceFunction 接口;类似地,addSink 方法同样需要传入一个参数,实现的是 SinkFunction 接口。在这个接口中只需要重写一个方法 invoke(),用来将指定的值写入到外部系统中。这个方法在每条数据记录到来时都会调用:
当然,SinkFuntion 多数情况下同样并不需要我们自己实现。Flink 官方提供了一部分的框架的 Sink 连接器。如图 5-13 所示,列出了 Flink 官方目前支持的第三方系统连接器:

我们可以看到,像 Kafka 之类流式系统,Flink 提供了完美对接,source/sink 两端都能连接,可读可写;而对于 Elasticsearch、文件系统(FileSystem)、JDBC 等数据存储系统,则只提供了输出写入的 sink 连接器。
除 Flink 官方之外,Apache Bahir 作为给 Spark 和 Flink 提供扩展支持的项目,也实现了一些其他第三方系统与 Flink 的连接器
除此以外,就需要用户自定义实现 sink 连接器了。
# 输出到文件
public class Demo_01_Sink_File {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<Event> stream = env.fromElements(
new Event("Bob", "./cart", 2000L),
new Event("Alice", "./prod?id=100", 3000L),
new Event("Alice", "./prod?id=200", 3500L),
new Event("Bob", "./prod?id=2", 2500L),
new Event("Alice", "./prod?id=300", 3600L),
new Event("Bob", "./home", 3000L),
new Event("Bob", "./prod?id=1", 2300L),
new Event("Bob", "./prod?id=3", 3300L)
);
StreamingFileSink<String> fileSink = StreamingFileSink.<String>forRowFormat(
new Path("./output"),
new SimpleStringEncoder<>("UTF-8")
)
.withRollingPolicy(
DefaultRollingPolicy.builder()
.withRolloverInterval(TimeUnit.MINUTES.toMillis(15))
.withInactivityInterval(TimeUnit.MINUTES.toMillis(5))
.withMaxPartSize(1024 * 1024 * 1024)
.build()
) .build();
// 将 Event 转换成 String 写入文件
stream.map(Event::toString).addSink(fileSink).setParallelism(2);
env.execute();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
# 输出到 Kafka
public class Demo_02_Sink_Kafka {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
Properties properties = new Properties();
properties.put("bootstrap.servers", "ha01:9092");
DataStreamSource<String> stream = env.readTextFile("input/clicks.csv");
stream
.addSink(new FlinkKafkaProducer<String>(
"clicks",
new SimpleStringSchema(),
properties
));
env.execute();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# 输出到 Redis
依赖
<dependency>
<groupId>org.apache.bahir</groupId>
<artifactId>flink-connector-redis_2.11</artifactId>
<version>1.0</version>
</dependency>
2
3
4
5
public class Demo_03_Sink_Redis {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 创建一个到 redis 连接的配置
FlinkJedisPoolConfig conf = new
FlinkJedisPoolConfig.Builder().setHost("ha01").build();
env.addSource(new Demo_03_Source_Customer.ClickSource())
.addSink(new RedisSink<Event>(conf, new MyRedisMapper()));
env.execute();
}
public static class MyRedisMapper implements RedisMapper<Event> {
@Override
public String getKeyFromData(Event e) {
return e.user;
}
@Override
public String getValueFromData(Event e) {
return e.url;
}
@Override
public RedisCommandDescription getCommandDescription() {
return new RedisCommandDescription(RedisCommand.HSET, "clicks");
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
# 输出到 Elasticsearch
依赖
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-elasticsearch6_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
2
3
4
5
public class Demo_04_Sink_ES {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DataStreamSource<Event> stream = env.fromElements(
new Event("Mary", "./home", 1000L),
new Event("Bob", "./cart", 2000L),
new Event("Alice", "./prod?id=100", 3000L),
new Event("Alice", "./prod?id=200", 3500L),
new Event("Bob", "./prod?id=2", 2500L),
new Event("Alice", "./prod?id=300", 3600L),
new Event("Bob", "./home", 3000L),
new Event("Bob", "./prod?id=1", 2300L),
new Event("Bob", "./prod?id=3", 3300L));
ArrayList<HttpHost> httpHosts = new ArrayList<>();
httpHosts.add(new HttpHost("ha01", 9200,"http"));
// 创建一个 ElasticsearchSinkFunction
ElasticsearchSinkFunction<Event> elasticsearchSinkFunction = new
ElasticsearchSinkFunction<Event>() {
@Override
public void process(Event element, RuntimeContext ctx, RequestIndexer indexer) {
HashMap<String, String> data = new HashMap<>();
data.put(element.user, element.url);
IndexRequest request = Requests.indexRequest()
.index("clicks")
.type("type") // Es 6 必须定义 type
.source(data);
indexer.add(request);
}
};
stream.addSink(new ElasticsearchSink.Builder<Event>(httpHosts, elasticsearchSinkFunction).build());
env.execute();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
# 输出到 MySQL(JDBC)
依赖
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-jdbc_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.47</version>
</dependency>
2
3
4
5
6
7
8
9
10
启动 MySQL,在 database 库下建表 clicks
public class Demo_05_Sink_MySQL {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DataStreamSource<Event> stream = env.fromElements(
new Event("Mary", "./home", 1000L),
new Event("Bob", "./cart", 2000L),
new Event("Alice", "./prod?id=100", 3000L),
new Event("Alice", "./prod?id=200", 3500L),
new Event("Bob", "./prod?id=2", 2500L),
new Event("Alice", "./prod?id=300", 3600L),
new Event("Bob", "./home", 3000L),
new Event("Bob", "./prod?id=1", 2300L),
new Event("Bob", "./prod?id=3", 3300L));
stream.addSink(
JdbcSink.sink(
"INSERT INTO clicks (user, url) VALUES (?, ?)",
(statement, r) -> {
statement.setString(1, r.user);
statement.setString(2, r.url);
},
JdbcExecutionOptions.builder()
.withBatchSize(1000)
.withBatchIntervalMs(200)
.withMaxRetries(5)
.build(),
new
JdbcConnectionOptions.JdbcConnectionOptionsBuilder()
.withUrl("jdbc:mysql://localhost:3306/userbe havior")
// 对于 MySQL 5.7,用"com.mysql.jdbc.Driver"
.withDriverName("com.mysql.cj.jdbc.Driver")
.withUsername("username")
.withPassword("password")
.build()
)
);
env.execute();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
# 自定义 Sink 输出 - Hbase
依赖
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>${hbase.version}</version>
</dependency>
2
3
4
5
public class Demo_06_Sink_Customer_Hbase {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
env
.fromElements("hello", "world")
.addSink(
new RichSinkFunction<String>() {
public org.apache.hadoop.conf.Configuration
configuration; // 管理 Hbase 的配置信息,这里因为 Configuration 的重名问题,将类以完整路径导入
public Connection connection; // 管理 Hbase 连接
@Override
public void open(Configuration parameters) throws
Exception {
super.open(parameters);
configuration = HBaseConfiguration.create();
configuration.set("hbase.zookeeper.quorum", "ha01:2181");
connection = ConnectionFactory.createConnection(configuration);
}
@Override
public void invoke(String value, Context context) throws
Exception {
Table table =
connection.getTable(TableName.valueOf("test")); // 表名为 test
Put put = new Put("rowkey".getBytes(StandardCharsets.UTF_8)); // 指定 rowkey
put.addColumn(
"info".getBytes(StandardCharsets.UTF_8) // 指定列名
, value.getBytes(StandardCharsets.UTF_8) // 写入的数据
, "1".getBytes(StandardCharsets.UTF_8)); // 写入的数据
table.put(put); // 执行 put 操作
table.close(); // 将表关闭
}
@Override
public void close() throws Exception {
super.close();
connection.close(); // 关闭连接
}
}
);
env.execute();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
# Flink 中的时间和窗口
我们已经了解了基本 API 的用法,熟悉了 DataStream 进行简单转换、聚合的一些操作。除此之外,Flink 还提供了丰富的转换算子,可以用于更加复杂的处理场景。
在流数据处理应用中,一个很重要、也很常见的操作就是窗口计算。所谓的“窗口”,一般就是划定的一段时间范围,也就是“时间窗”;对在这范围内的数据进行处理,就是所谓的窗口计算。所以窗口和时间往往是分不开的。接下来我们就深入了解一下 Flink 中的时间语义和窗口的应用。
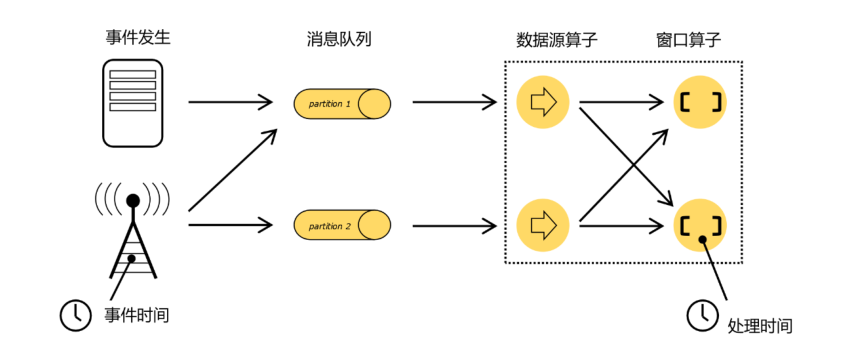
在事件发生之后,生成的数据被收集起来,首先进入分布式消息队列,然后被 Flink 系统中的 Source 算子读取消费,进而向下游的转换算子(窗口算子)传递,最终由窗口算子进行计算处理。
很明显,这里有两个非常重要的时间点:一个是数据产生的时间,我们把它叫作“事件时间”(Event Time);另一个是数据真正被处理的时刻,叫作“处理时间”(Processing Time)。我们所定义的窗口操作,到底是以那种时间作为衡量标准,就是所谓的“时间语义”(Notions of Time)。由于分布式系统中网络传输的延迟和时钟漂移,处理时间相对事件发生的时间会有所滞后。
处理时间(Processing Time)
处理时间的概念非常简单,就是指执行处理操作的机器的系统时间
如果我们以它作为衡量标准,那么数据属于哪个窗口就很明显了:只看窗口任务处理这条数据时,当前的系统时间。比如之前举的例子,数据 8 点 59 分 59 秒产生,而窗口计算时的时间是 9 点零 1 秒,那么这条数据就属于 9 点—10 点的窗口;如果数据传输非常快,9 点之前就到了窗口任务,那么它就属于 8 点—9 点的窗口了。每个并行的窗口子任务,就只按照自己的系统时钟划分窗口。假如我们在早上 8 点 10 分启动运行程序,那么接下来一直到 9 点以前处理的所有数据,都属于第一个窗口;9 点之后、10 点之前的所有数据就将属于第二个窗口。
这种方法非常简单粗暴,不需要各个节点之间进行协调同步,也不需要考虑数据在流中的位置,简单来说就是“我的地盘听我的”。所以处理时间是最简单的时间语义。
事件时间(Event Time)
事件时间,是指每个事件在对应的设备上发生的时间,也就是数据生成的时间。
数据一旦产生,这个时间自然就确定了,所以它可以作为一个属性嵌入到数据中。这其实就是这条数据记录的“时间戳”(Timestamp)。
在事件时间语义下,我们对于时间的衡量,就不看任何机器的系统时间了,而是依赖于数据本身。
当然我们会发现,这里有个前提,就是“先产生的数据先被处理”,这要求我们可以保证数据到达的顺序。但是由于分布式系统中网络传输延迟的不确定性,实际应用中我们要面对的数据流往往是乱序的。在这种情况下,就不能简单地把数据自带的时间戳当作时钟了,而需要用另外的标志来表示事件时间进展,在 Flink 中把它叫作事件时间的“水位线”(Watermarks)。关于水位线的概念和用法
# 水位线(Watermark)
在介绍事件时间语义时,我们提到了“水位线”的概念,已经知道了它其实就是用来度量事件时间的。那么水位线具体有什么含义,又跟数据的时间戳有什么关系呢?接下来我们就来深入探讨一下这个流处理中的核心概念
# 事件时间和窗口
在实际应用中,一般会采用事件时间语义。而水位线,就是基于事件时间提出的概念。所以在介绍水位线之前,我们首先来梳理一下事件时间和窗口的关系。
一个数据产生的时刻,就是流处理中事件触发的时间点,这就是“事件时间”,一般都会125以时间戳的形式作为一个字段记录在数据里。这个时间就像商品的“生产日期”一样,一旦产生就是固定的,印在包装袋上,不会因为运输辗转而变化。如果我们想要统计一段时间内的数据,需要划分时间窗口,这时只要判断一下时间戳就可以知道数据属于哪个窗口了
明确了一个数据的所属窗口,还不能直接进行计算。因为窗口处理的是有界数据,我们需要等窗口的数据都到齐了,才能计算出最终的统计结果。那什么时候数据就都到齐了呢?对于时间窗口来说这很明显:到了窗口的结束时间,自然就应该收集到了所有数据,就可以触发计算输出结果了。比如我们想统计 8 点~9 点的用户点击量,那就是从 8 点开始收集数据,到 9点截止,将收集的数据做处理计算
# 什么是水位线
在事件时间语义下,我们不依赖系统时间,而是基于数据自带的时间戳去定义了一个时钟,用来表示当前时间的进展。于是每个并行子任务都会有一个自己的逻辑时钟,它的前进是靠数据的时间戳来驱动的
但在分布式系统中,这种驱动方式又会有一些问题。因为数据本身在处理转换的过程中会变化,如果遇到窗口聚合这样的操作,其实是要攒一批数据才会输出一个结果,那么下游的数据就会变少,时间进度的控制就不够精细了。另外,数据向下游任务传递时,一般只能传输给一个子任务(除广播外),这样其他的并行子任务的时钟就无法推进了。例如一个时间戳为 9点整的数据到来,当前任务的时钟就已经是 9 点了;处理完当前数据要发送到下游,如果下游任务是一个窗口计算,并行度为 3,那么接收到这个数据的子任务,时钟也会进展到 9 点,9点结束的窗口就可以关闭进行计算了;而另外两个并行子任务则时间没有变化,不能进行窗口计算。
所以我们应该把时钟也以数据的形式传递出去,告诉下游任务当前时间的进展;而且这个时钟的传递不会因为窗口聚合之类的运算而停滞。一种简单的想法是,在数据流中加入一个时钟标记,记录当前的事件时间;这个标记可以直接广播到下游,当下游任务收到这个标记,就可以更新自己的时钟了。由于类似于水流中用来做标志的记号,在 Flink 中,这种用来衡量事件时间(Event Time)进展的标记,就被称作“水位线”(Watermark)。
具体实现上,水位线可以看作一条特殊的数据记录,它是插入到数据流中的一个标记点,主要内容就是一个时间戳,用来指示当前的事件时间。而它插入流中的位置,就应该是在某个数据到来之后;这样就可以从这个数据中提取时间戳,作为当前水位线的时间戳了。

每个事件产生的数据,都包含了一个时间戳,我们直接用一个整数表示。这里没有指定单位,可以理解为秒或者毫秒(方便起见,下面讲述统一认为是秒)。当产生于2 秒的数据到来之后,当前的事件时间就是 2 秒;在后面插入一个时间戳也为 2 秒的水位线,随着数据一起向下游流动。而当 5 秒产生的数据到来之后,同样在后面插入一个水位线,时间戳也为 5,当前的时钟就推进到了 5 秒。这样,如果出现下游有多个并行子任务的情形,我们只要将水位线广播出去,就可以通知到所有下游任务当前的时间进度了。
水位线就像它的名字所表达的,是数据流中的一部分,随着数据一起流动,在不同任务之间传输。这看起来非常简单;接下来我们就进一步探讨一些复杂的状况。
# 有序流中的水位线
在理想状态下,数据应该按照它们生成的先后顺序、排好队进入流中;也就是说,它们处理的过程会保持原先的顺序不变,遵守先来后到的原则。这样的话我们从每个数据中提取时间戳,就可以保证总是从小到大增长的,从而插入的水位线也会不断增长、事件时钟不断向前推进。
实际应用中,如果当前数据量非常大,可能会有很多数据的时间戳是相同的,这时每来一条数据就提取时间戳、插入水位线就做了大量的无用功。而且即使时间戳不同,同时涌来的数据时间差会非常小(比如几毫秒),往往对处理计算也没什么影响。所以为了提高效率,一般会每隔一段时间生成一个水位线,这个水位线的时间戳,就是当前最新数据的时间戳

这里需要注意的是,水位线插入的“周期”,本身也是一个时间概念。在当前事件时间语义下,假如我们设定了每隔 100ms 生成一次水位线,那就是要等事件时钟推进 100ms 才能插入;但是事件时钟本身的进展,本身就是靠水位线来表示的——现在要插入一个水位线,可前提又是水位线要向前推进 100ms,这就陷入了死循环。所以对于水位线的周期性生成,周期时间是指处理时间(系统时间),而不是事件时间。
# 乱序流中的水位线
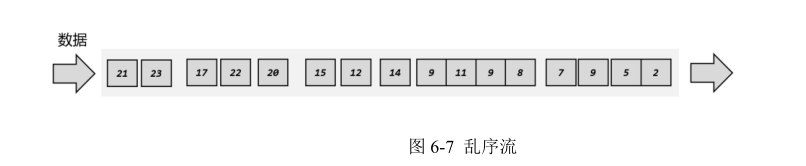
有序流的处理非常简单,看起来水位线也并没有起到太大的作用。但这种情况只存在于理想状态下。我们知道在分布式系统中,数据在节点间传输,会因为网络传输延迟的不确定性,导致顺序发生改变,这就是所谓的“乱序数据”。
这里所说的“乱序”(out-of-order),是指数据的先后顺序不一致,主要就是基于数据的产生时间而言的。如图 6-7 所示,一个 7 秒时产生的数据,生成时间自然要比 9 秒的数据早;但是经过数据缓存和传输之后,处理任务可能先收到了 9 秒的数据,之后 7 秒的数据才姗姗来迟。这时如果我们希望插入水位线,来指示当前的事件时间进展,又该怎么做呢?
最直观的想法自然是跟之前一样,我们还是靠数据来驱动,每来一个数据就提取它的时间戳、插入一个水位线。不过现在的情况是数据乱序,所以有可能新的时间戳比之前的还小,如果直接将这个时间的水位线再插入,我们的“时钟”就回退了——水位线就代表了时钟,时光不能倒流,所以水位线的时间戳也不能减小。
解决思路也很简单:我们插入新的水位线时,要先判断一下时间戳是否比之前的大,否则就不再生成新的水位线,也就是说,只有数据的时间戳比当前时钟大,才能推动时钟前进,这时才插入水位线。

如果考虑到大量数据同时到来的处理效率,我们同样可以周期性地生成水位线。这时只需要保存一下之前所有数据中的最大时间戳,需要插入水位线时,就直接以它作为时间戳生成新的水位线

这样做尽管可以定义出一个事件时钟,却也会带来一个非常大的问题:我们无法正确处理“迟到”的数据。在上面的例子中,当 9 秒产生的数据到来之后,我们就直接将时钟推进到了9 秒;如果有一个窗口结束时间就是 9 秒(比如,要统计 0~9 秒的所有数据),那么这时窗口就应该关闭、将收集到的所有数据计算输出结果了。但事实上,由于数据是乱序的,还可能有时间戳为 7 秒、8 秒的数据在 9 秒的数据之后才到来,这就是“迟到数据”(late data)。它们本来也应该属于 0~9 秒这个窗口,但此时窗口已经关闭,于是这些数据就被遗漏了,这会导致统计结果不正确。
为了让窗口能够正确收集到迟到的数据,我们也可以等上 2 秒;也就是用当前已有数据的最大时间戳减去 2 秒,就是要插入的水位线的时间戳,如图 6-10 所示。这样的话,9 秒的数据到来之后,事件时钟不会直接推进到 9 秒,而是进展到了 7 秒;必须等到11 秒的数据到来之后,事件时钟才会进展到 9 秒,这时迟到数据也都已收集齐,0~9 秒的窗口就可以正确计算结果了。
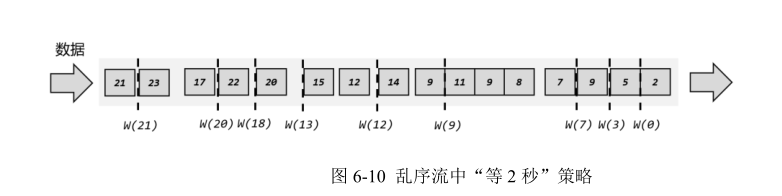
如果仔细观察就会看到,这种“等 2 秒”的策略其实并不能处理所有的乱序数据。比如22 秒的数据到来之后,插入的水位线时间戳为 20,也就是当前时钟已经推进到了 20 秒;对于10~20 秒的窗口,这时就该关闭了。但是之后又会有 17 秒的迟到数据到来,它本来应该属于10~20 秒窗口,现在却被遗漏丢弃了。那又该怎么办呢?
既然现在等 2 秒还是等不到 17 秒产生的迟到数据,那自然我们可以试着多等几秒,也就是把时钟调得更慢一些。最终的目的,就是要让窗口能够把所有迟到数据都收进来,得到正确的计算结果。对应到水位线上,其实就是要保证,当前时间已经进展到了这个时间戳,在这之后不可能再有迟到数据来了。
下面是一个示例,我们可以使用周期性的方式生成正确的水位线。

如图 6-11 所示,第一个水位线时间戳为 7,它表示当前事件时间是 7 秒,7 秒之前的数据都已经到齐,之后再也不会有了;同样,第二个、第三个水位线时间戳分别为 12 和 20,表示11 秒、20 秒之前的数据都已经到齐,如果有对应的窗口就可以直接关闭了,统计的结果一定是正确的。这里由于水位线是周期性生成的,所以插入的位置不一定是在时间戳最大的数据后面。
另外需要注意的是,这里一个窗口所收集的数据,并不是之前所有已经到达的数据。因为数据属于哪个窗口,是由数据本身的时间戳决定的,一个窗口只会收集真正属于它的那些数据。也就是说,上图中尽管水位线 W(20)之前有时间戳为 22 的数据到来,10~20 秒的窗口中也不会收集这个数据,进行计算依然可以得到正确的结果。关于窗口的原理,我们会在后面继续展开讲解。
# 水位线的特性
水位线就代表了当前的事件时间时钟,而且可以在数据的时间戳基础上加一些延迟来保证不丢数据,这一点对于乱序流的正确处理非常重要
我们可以总结一下水位线的特性:
- 水位线是插入到数据流中的一个标记,可以认为是一个特殊的数据
- 水位线主要的内容是一个时间戳,用来表示当前事件时间的进展
- 水位线是基于数据的时间戳生成的
- 水位线的时间戳必须单调递增,以确保任务的事件时间时钟一直向前推进
- 水位线可以通过设置延迟,来保证正确处理乱序数据
- 一个水位线 Watermark(t),表示在当前流中事件时间已经达到了时间戳 t, 这代表 t 之前的所有数据都到齐了,之后流中不会出现时间戳 t’ ≤ t 的数据
水位线是 Flink 流处理中保证结果正确性的核心机制,它往往会跟窗口一起配合,完成对乱序数据的正确处理。关于这部分内容,我们会稍后进一步展开讲解。
# 如何生成水位线
# 水位线生成策略(Watermark Strategies)
在 Flink 的 DataStream API 中 , 有 一 个 单 独 用 于 生 成 水 位 线 的 方法:.assignTimestampsAndWatermarks(),它主要用来为流中的数据分配时间戳,并生成水位线来指示事件时间:
public SingleOutputStreamOperator<T> assignTimestampsAndWatermarks(WatermarkStrategy<T> watermarkStrategy)
具体使用时,直接用 DataStream 调用该方法即可,与普通的 transform 方法完全一样
DataStream<Event> stream = env.addSource(new ClickSource());
DataStream<Event> withTimestampsAndWatermarks = stream.assignTimestampsAndWatermarks(<watermark strategy>);
2
.assignTimestampsAndWatermarks()方法需要传入一个 WatermarkStrategy 作为参数,这就是 所 谓 的 “ 水 位 线 生 成 策 略 ” 。 WatermarkStrategy 中 包 含 了 一 个 “ 时 间 戳 分 配器”TimestampAssigner 和一个“水位线生成器”WatermarkGenerator。
public interface WatermarkStrategy<T> extends TimestampAssignerSupplier<T>,WatermarkGeneratorSupplier<T>{
@Override
TimestampAssigner<T> createTimestampAssigner(TimestampAssignerSupplier.Context context);
@Override
WatermarkGenerator<T> createWatermarkGenerator(WatermarkGeneratorSupplier.Context context);
}
2
3
4
5
6
TimestampAssigner:主要负责从流中数据元素的某个字段中提取时间戳,并分配给元素。时间戳的分配是生成水位线的基础。
WatermarkGenerator:主要负责按照既定的方式,基于时间戳生成水位线。在WatermarkGenerator 接口中,主要又有两个方法:onEvent()和 onPeriodicEmit()。
onEvent:每个事件(数据)到来都会调用的方法,它的参数有当前事件、时间戳,以及允许发出水位线的一个 WatermarkOutput,可以基于事件做各种操作
onPeriodicEmit:周期性调用的方法,可以由 WatermarkOutput 发出水位线。周期时间为处理时间,可以调用环境配置的.setAutoWatermarkInterval()方法来设置,默认为200ms。
env.getConfig().setAutoWatermarkInterval(60 * 1000L);1
# Flink 内置水位线生成器
WatermarkStrategy 这个接口是一个生成水位线策略的抽象,让我们可以灵活地实现自己的需求;但看起来有些复杂,如果想要自己实现应该还是比较麻烦的。好在 Flink 充分考虑到了我们的痛苦,提供了内置的水位线生成器(WatermarkGenerator),不仅开箱即用简化了编程,而且也为我们自定义水位线策略提供了模板。
这两个生成器可以通过调用 WatermarkStrategy 的静态辅助方法来创建。它们都是周期性生成水位线的,分别对应着处理有序流和乱序流的场景。
有序流
对于有序流,主要特点就是时间戳单调增长(Monotonously Increasing Timestamps),所以永远不会出现迟到数据的问题。这是周期性生成水位线的最简单的场景,直接调用WatermarkStrategy.forMonotonousTimestamps()方法就可以实现。简单来说,就是直接拿当前最大的时间戳作为水位线就可以了。
stream.assignTimestampsAndWatermarks(
WatermarkStrategy.<Event>forMonotonousTimestamps()
.withTimestampAssigner(
new SerializableTimestampAssigner<Event>(){
@Override
public long extractTimestamp(Event element, long recordTimestamp){
return element.timestamp;
}
})
);
2
3
4
5
6
7
8
9
10
上面代码中我们调用.withTimestampAssigner()方法,将数据中的 timestamp 字段提取出来,作为时间戳分配给数据元素;然后用内置的有序流水位线生成器构造出了生成策略。这样,提取出的数据时间戳,就是我们处理计算的事件时间。
这里需要注意的是,时间戳和水位线的单位,必须都是毫秒。
乱序流
由于乱序流中需要等待迟到数据到齐,所以必须设置一个固定量的延迟时间(FixedAmount of Lateness)。这时生成水位线的时间戳,就是当前数据流中最大的时间戳减去延迟的结果,相当于把表调慢,当前时钟会滞后于数据的最大时间戳。调用 WatermarkStrategy.forBoundedOutOfOrderness()方法就可以实现。这个方法需要传入一个 maxOutOfOrderness 参数,表示“最大乱序程度”,它表示数据流中乱序数据时间戳的最大差值;如果我们能确定乱序程度,那么设置对应时间长度的延迟,就可以等到所有的乱序数据了。
public class Demo_01_Watermark_Test {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
env.addSource(new Demo_03_Source_Customer.ClickSource())
// 插入水位线的逻辑
.assignTimestampsAndWatermarks(
// 针对乱序流插入水位线,延迟时间设置为 5s
WatermarkStrategy.<Event>forBoundedOutOfOrderness(Duration.ofSeconds(5))
.withTimestampAssigner(new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event event, long recordTimestamp) {
return event.timestamp;
}
})
).print();
env.execute();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
上面代码中,我们同样提取了 timestamp 字段作为时间戳,并且以 5 秒的延迟时间创建了处理乱序流的水位线生成器。
事实上,有序流的水位线生成器本质上和乱序流是一样的,相当于延迟设为 0 的乱序流水位线生成器,两者完全等同:
WatermarkStrategy.forMonotonousTimestamps()
WatermarkStrategy.forBoundedOutOfOrderness(Duration.ofSeconds(0))
2
这里需要注意的是,乱序流中生成的水位线真正的时间戳,其实是 当前最大时间戳 – 延迟时间 – 1,这里的单位是毫秒。为什么要减 1 毫秒呢?我们可以回想一下水位线的特点:时间戳为 t 的水位线,表示时间戳≤t 的数据全部到齐,不会再来了。如果考虑有序流,也就是延迟时间为 0 的情况,那么时间戳为 7 秒的数据到来时,之后其实是还有可能继续来 7 秒的数据的;所以生成的水位线不是 7 秒,而是 6 秒 999 毫秒,7 秒的数据还可以继续来。这一点可以BoundedOutOfOrdernessWatermarks 的源码中明显地看到:
public void onPeriodicEmit(WatermarkOutput output) {
output.emitWatermark(new Watermark(maxTimestamp - outOfOrdernessMillis - 1));
}
2
3
# 自定义水位线策略
一般来说,Flink 内置的水位线生成器就可以满足应用需求了。不过有时我们的业务逻辑可能非常复杂,这时对水位线生成的逻辑也有更高的要求,我们就必须自定义实现水位线策略WatermarkStrategy 了。
在 WatermarkStrategy 中,时间戳分配器 TimestampAssigner 都是大同小异的,指定字段提取时间戳就可以了;而不同策略的关键就在于 WatermarkGenerator 的实现。整体说来,Flink有两种不同的生成水位线的方式:一种是周期性的(Periodic),另一种是断点式的(Punctuated)。
还记得 WatermarkGenerator 接口中的两个方法吗?——onEvent()和 onPeriodicEmit(),前者是在每个事件到来时调用,而后者由框架周期性调用。周期性调用的方法中发出水位线,自然就是周期性生成水位线;而在事件触发的方法中发出水位线,自然就是断点式生成了。两种方式的不同就集中体现在这两个方法的实现上。
周期性水位线生成器(Periodic Generator)
周期性生成器一般是通过 onEvent()观察判断输入的事件,而在 onPeriodicEmit()里发出水位线。
下面是一段自定义周期性生成水位线的代码:
public class Demo_02_Watermark_Customer {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
env.addSource(new Demo_03_Source_Customer.ClickSource())
// 插入水位线的逻辑
.assignTimestampsAndWatermarks(new CustomWatermarkStrategy())
.print();
env.execute();
}
public static class CustomWatermarkStrategy implements WatermarkStrategy<Event> {
@Override
public TimestampAssigner<Event> createTimestampAssigner(TimestampAssignerSupplier.Context context) {
return new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event event, long l) {
return event.timestamp; // 告诉程序数据源里的时间戳是哪一个字段
}
};
}
@Override
public WatermarkGenerator<Event> createWatermarkGenerator(WatermarkGeneratorSupplier.Context context) {
return new CustomPeriodicGenerator();
}
}
public static class CustomPeriodicGenerator implements WatermarkGenerator<Event> {
private Long delayTime = 5000L; // 延迟时间
private Long maxTs = Long.MIN_VALUE + delayTime + 1L; // 观察到的最大时间戳
@Override
public void onEvent(Event event, long l, WatermarkOutput watermarkOutput) {
// 每来一条数据就调用一次
maxTs = Math.max(event.timestamp, maxTs); // 更新最大时间戳
}
@Override
public void onPeriodicEmit(WatermarkOutput output) {
// 发射水位线,默认 200ms 调用一次
output.emitWatermark(new Watermark(maxTs - delayTime - 1L));
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
我们在 onPeriodicEmit()里调用 output.emitWatermark(),就可以发出水位线了;这个方法由系统框架周期性地调用,默认 200ms 一次。所以水位线的时间戳是依赖当前已有数据的最大时间戳的(这里的实现与内置生成器类似,也是减去延迟时间再减 1),但具体什么时候生成与数据无关。
断点式水位线生成器(Punctuated Generator)
断点式生成器会不停地检测 onEvent()中的事件,当发现带有水位线信息的特殊事件时,就立即发出水位线。一般来说,断点式生成器不会通过 onPeriodicEmit()发出水位线。自定义的断点式水位线生成器代码如下:
public class CustomPunctuatedGenerator implements WatermarkGenerator<Event> {
@Override
public void onEvent(Event r, long eventTimestamp, WatermarkOutput output) {
// 只有在遇到特定的 itemId 时,才发出水位线
if (r.user.equals("Mary")) {
output.emitWatermark(new Watermark(r.timestamp - 1));
}
@Override
public void onPeriodicEmit(WatermarkOutput output) {
// 不需要做任何事情,因为我们在 onEvent 方法中发射了水位线
}
}
2
3
4
5
6
7
8
9
10
11
12
我们在 onEvent()中判断当前事件的 user 字段,只有遇到“Mary”这个特殊的值时,才调用output.emitWatermark()发出水位线。这个过程是完全依靠事件来触发的,所以水位线的生成一定在某个数据到来之后。
# 在自定义数据源中发送水位线
我们也可以在自定义的数据源中抽取事件时间,然后发送水位线。这里要注意的是,在自定义数据源中发送了水位线以后,就不能再在程序中使用 assignTimestampsAndWatermarks 方法 来 生 成 水 位 线 了 。 在 自 定 义 数 据 源 中 生 成 水 位 线 和 在 程 序 中 使 用assignTimestampsAndWatermarks 方法生成水位线二者只能取其一。示例程序如下:
public class Demo_03_Watermark_Customer_Source {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
env.addSource(new ClickSourceWithWatermark()).print();
env.execute();
}
// 泛型是数据源中的类型
public static class ClickSourceWithWatermark implements SourceFunction<Event> {
private boolean running = true;
@Override
public void run(SourceContext<Event> sourceContext) throws Exception {
Random random = new Random();
String[] userArr = {"Mary", "Bob", "Alice"};
String[] urlArr = {"./home", "./cart", "./prod?id=1"};
while (running) {
long currTs = Calendar.getInstance().getTimeInMillis(); // 毫秒时间戳
String username = userArr[random.nextInt(userArr.length)];
String url = urlArr[random.nextInt(urlArr.length)];
Event event = new Event(username, url, currTs);
// 使用 collectWithTimestamp 方法将数据发送出去,并指明数据中的时间戳的字段
sourceContext.collectWithTimestamp(event, event.timestamp);
// 发送水位线
sourceContext.emitWatermark(new Watermark(event.timestamp - 1L));
Thread.sleep(1000L);
}
}
@Override
public void cancel() {
running = false;
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
在自定义水位线中生成水位线相比 assignTimestampsAndWatermarks 方法更加灵活,可以任意的产生周期性的、非周期性的水位线,以及水位线的大小也完全由我们自定义。所以非常适合用来编写 Flink 的测试程序,测试 Flink 的各种各样的特性。
# 水位线的传递
我们知道水位线是数据流中插入的一个标记,用来表示事件时间的进展,它会随着数据一起在任务间传递。如果只是直通式(forward)的传输,那很简单,数据和水位线都是按照本身的顺序依次传递、依次处理的;一旦水位线到达了算子任务, 那么这个任务就会将它内部的时钟设为这个水位线的时间戳。
在这里,“任务的时钟”其实仍然是各自为政的,并没有统一的时钟。实际应用中往往上下游都有多个并行子任务,为了统一推进事件时间的进展,我们要求上游任务处理完水位线、时钟改变之后,要把当前的水位线再次发出,广播给所有的下游子任务。这样,后续任务就不需要依赖原始数据中的时间戳(经过转化处理后,数据可能已经改变了),也可以知道当前事件时间了。
可是还有另外一个问题,那就是在“重分区”(redistributing)的传输模式下,一个任务有可能会收到来自不同分区上游子任务的数据。而不同分区的子任务时钟并不同步,所以同一时刻发给下游任务的水位线可能并不相同。这时下游任务又该听谁的呢?
这就要回到水位线定义的本质了:它表示的是“当前时间之前的数据,都已经到齐了”。这是一种保证,告诉下游任务“只要你接到这个水位线,就代表之后我不会再给你发更早的数据了,你可以放心做统计计算而不会遗漏数据”。所以如果一个任务收到了来自上游并行任务的不同的水位线,说明上游各个分区处理得有快有慢,进度各不相同比如上游有两个并行子任务都发来了水位线,一个是 5 秒,一个是 7 秒;这代表第一个并行任务已经处理完 5 秒之前的所有数据,而第二个并行任务处理到了 7 秒。那这时自己的时钟怎么确定呢?当然也要以“这之前的数据全部到齐”为标准。如果我们以较大的水位线 7 秒作为当前时间,那就表示“7 秒 前的数据都已经处理完”,这显然不是事实——第一个上游分区才处理到 5 秒,5~7 秒的数据还会不停地发来;而如果以最小的水位线 5 秒作为当前时钟就不会有这个问题了,因为确实所有上游分区都已经处理完,不会再发 5 秒前的数据了。这让我们想到“木桶原理”:所有的上游并行任务就像围成木桶的一块块木板,它们中最短的那一块,决定了我们桶中的水位。

我们可以用一个具体的例子,将水位线在任务间传递的过程完整梳理一遍。如图 6-12 所示,当前任务的上游,有四个并行子任务,所以会接收到来自四个分区的水位线;而下游有三个并行子任务,所以会向三个分区发出水位线。具体过程如下:
- 上游并行子任务发来不同的水位线,当前任务会为每一个分区设置一个“分区水位线”(Partition Watermark),这是一个分区时钟;而当前任务自己的时钟,就是所有分区时钟里最小的那个。
- 当有一个新的水位线(第一分区的 4)从上游传来时,当前任务会首先更新对应的分区时钟;然后再次判断所有分区时钟中的最小值,如果比之前大,说明事件时间有了进展,当前任务的时钟也就可以更新了。这里要注意,更新后的任务时钟,并不一定是新来的那个分区水位线,比如这里改变的是第一分区的时钟,但最小的分区时钟是第三分区的 3,于是当前任务时钟就推进到了 3。当时钟有进展时,当前任务就会将自己的时钟以水位线的形式,广播给下游所有子任务。
- 再次收到新的水位线(第二分区的 7)后,执行同样的处理流程。首先将第二个分区时钟更新为 7,然后比较所有分区时钟;发现最小值没有变化,那么当前任务的时钟也不变,也不会向下游任务发出水位线
- 同样道理,当又一次收到新的水位线(第三分区的 6)之后,第三个分区时钟更新为6,同时所有分区时钟最小值变成了第一分区的 4,所以当前任务的时钟推进到 4,并发出时间戳为 4 的水位线,广播到下游各个分区任务。
- 水位线在上下游任务之间的传递,非常巧妙地避免了分布式系统中没有统一时钟的问题,每个任务都以“处理完之前所有数据”为标准来确定自己的时钟,就可以保证窗口处理的结果总是正确的。对于有多条流合并之后进行处理的场景,水位线传递的规则是类似的。关于 Flink中的多流转换,我们会在后续章节中介绍。
# 窗口(Window)
我们已经了解了 Flink 中事件时间和水位线的概念,那它们有什么具体应用呢?当然是做基于时间的处理计算了。其中最常见的场景,就是窗口聚合计算。
之前我们已经了解了 Flink 中基本的聚合操作。在流处理中,我们往往需要面对的是连续不断、无休无止的无界流,不可能等到所有所有数据都到齐了才开始处理。所以聚合计算其实只能针对当前已有的数据——之后再有数据到来,就需要继续叠加、再次输出结果。这样似乎很“实时”,但现实中大量数据一般会同时到来,需要并行处理,这样频繁地更新结果就会给系统带来很大负担了。
更加高效的做法是,把无界流进行切分,每一段数据分别进行聚合,结果只输出一次。这就相当于将无界流的聚合转化为了有界数据集的聚合,这就是所谓的“窗口”(Window)聚合操作。窗口聚合其实是对实时性和处理效率的一个权衡。在实际应用中,我们往往更关心一段时间内数据的统计结果,比如在过去的 1 分钟内有多少用户点击了网页。在这种情况下,我们就可以定义一个窗口,收集最近一分钟内的所有用户点击数据,然后进行聚合统计,最终输出一个结果就可以了。
在 Flink 中,提供了非常丰富的窗口操作,下面我们就来详细介绍。
# 窗口的概念
Flink 是一种流式计算引擎,主要是来处理无界数据流的,数据源源不断、无穷无尽。想要更加方便高效地处理无界流,一种方式就是将无限数据切割成有限的“数据块”进行处理,这就是所谓的“窗口”(Window)。
在 Flink 中, 窗口就是用来处理无界流的核心。我们很容易把窗口想象成一个固定位置的“框”,数据源源不断地流过来,到某个时间点窗口该关闭了,就停止收集据、触发计算并输出结果。例如,我们定义一个时间窗口,每 10 秒统计一次数据,那么就相当于把窗口放在那里,从 0 秒开始收集数据;到 10 秒时,处理当前窗口内所有数据,输出一个结果,然后清空窗口继续收集数据;到 20 秒时,再对窗口内所有数据进行计算处理,输出结果;依次类推,如图 6-13 所示。

这里注意为了明确数据划分到哪一个窗口,定义窗口都是包含起始时间、不包含结束时间的,用数学符号表示就是一个左闭右开的区间,例如 0~10 秒的窗口可以表示为[0, 10),这里单位为秒。
对于处理时间下的窗口而言,这样理解似乎没什么问题。因为窗口的关闭是基于系统时间的,赶不上这班车的数据,就只能坐下一班车了——正如上图中,0~10 秒的窗口关闭后,可能还有时间戳为 9 的数据会来,它就只能进入 10~20 秒的窗口了。这样会造成窗口处理结果的不准确。
然而如果我们采用事件时间语义,就会有些费解了。由于有乱序数据,我们需要设置一个延迟时间来等所有数据到齐。比如上面的例子中,我们可以设置延迟时间为 2 秒,如图 6-14所示,这样 0~10 秒的窗口会在时间戳为 12 的数据到来之后,才真正关闭计算输出结果,这样就可以正常包含迟到的 9 秒数据了。
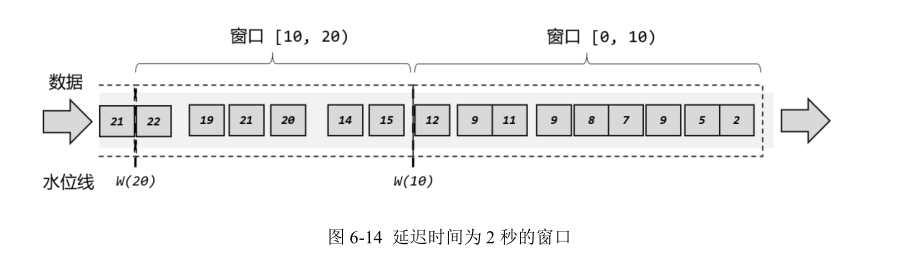
但是这样一来,0~10 秒的窗口不光包含了迟到的 9 秒数据,连 11 秒和 12 秒的数据也包含进去了。我们为了正确处理迟到数据,结果把早到的数据划分到了错误的窗口——最终结果都是错误的。
所以在 Flink 中,窗口其实并不是一个“框”,流进来的数据被框住了就只能进这一个窗口。相比之下,我们应该把窗口理解成一个“桶”,如图 6-15 所示。在 Flink 中,窗口可以把流切割成有限大小的多个“存储桶”(bucket);每个数据都会分发到对应的桶中,当到达窗口结束时间时,就对每个桶中收集的数据进行计算处理。

我们可以梳理一下事件时间语义下,之前例子中窗口的处理过程:
- 第一个数据时间戳为 2,判断之后创建第一个窗口[0, 10),并将 2 秒数据保存进去;
- 后续数据依次到来,时间戳均在 [0, 10)范围内,所以全部保存进第一个窗口;
- 11 秒数据到来,判断它不属于[0, 10)窗口,所以创建第二个窗口[10, 20),并将 11秒的数据保存进去。由于水位线设置延迟时间为 2 秒,所以现在的时钟是 9 秒,第一个窗口也没有到关闭时间;
- 之后又有 9 秒数据到来,同样进入[0, 10)窗口中;
- 12 秒数据到来,判断属于[10, 20)窗口,保存进去。这时产生的水位线推进到了 10秒,所以 [0, 10)窗口应该关闭了。第一个窗口收集到了所有的 7 个数据,进行处理计算后输出结果,并将窗口关闭销毁;
- 同样的,之后的数据依次进入第二个窗口,遇到 20 秒的数据时会创建第三个窗口[20,30)并将数据保存进去;遇到 22 秒数据时,水位线达到了 20 秒,第二个窗口触发计算,输出结果并关闭。
这里需要注意的是,Flink 中窗口并不是静态准备好的,而是动态创建——当有落在这个窗口区间范围的数据达到时,才创建对应的窗口。另外,这里我们认为到达窗口结束时间时,窗口就触发计算并关闭,事实上“触发计算”和“窗口关闭”两个行为也可以分开,这部分内容我们会在后面详述。
# 窗口的分类
# 按照驱动类型分类
窗口本身是截取有界数据的一种方式,所以窗口一个非常重要的信息其实就是“怎样截取数据”。换句话说,就是以什么标准来开始和结束数据的截取,我们把它叫作窗口的“驱动类型”。
我们最容易想到的就是按照时间段去截取数据,这种窗口就叫作“时间窗口”(TimeWindow)。这在实际应用中最常见,之前所举的例子也都是时间窗口。除了由时间驱动之外,窗口其实也可以由数据驱动,也就是说按照固定的个数,来截取一段数据集,这种窗口叫作“计数窗口”(Count Window),如图 6-16 所示。
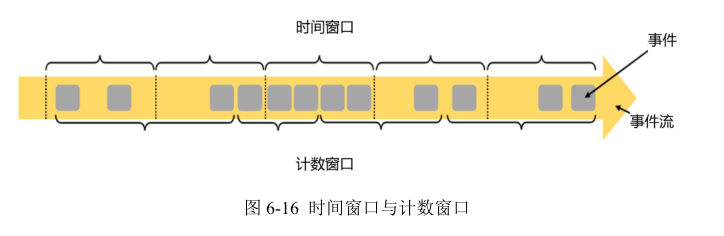
时间窗口(Time Window )
时间窗口以时间点来定义窗口的开始(start)和结束(end),所以截取出的就是某一时间段的数据。到达结束时间时,窗口不再收集数据,触发计算输出结果,并将窗口关闭销毁。所以可以说基本思路就是“定点发车”。
用结束时间减去开始时间,得到这段时间的长度,就是窗口的大小(window size)。这里的时间可以是不同的语义,所以我们可以定义处理时间窗口和事件时间窗口。
Flink 中有一个专门的类来表示时间窗口,名称就叫作 TimeWindow。这个类只有两个私有属性:start 和 end,表示窗口的开始和结束的时间戳,单位为毫秒。
private final long start;
private final long end;
2
我们可以调用公有的 getStart()和 getEnd()方法直接获取这两个时间戳。另外,TimeWindow还提供了一个 maxTimestamp()方法,用来获取窗口中能够包含数据的最大时间戳。
public long maxTimestamp() {
return end - 1;
}
2
3
很明显,窗口中的数据,最大允许的时间戳就是 end - 1,这也就代表了我们定义的窗口时间范围都是左闭右开的区间[start,end)。
或许有较真的读者会问,为什么不把窗口区间定义成左开右闭、包含上结束时间呢?这样maxTimestamp 跟 end 一致,不就可以省去一个方法的定义吗?
这主要是为了方便判断窗口什么时候关闭。对于事件时间语义,窗口的关闭需要水位线推进到窗口的结束时间;而我们知道,水位线 Watermark(t)代表的含义是“时间戳小于等于 t 的数据都已到齐,不会再来了”。为了简化分析,我们先不考虑乱序流设置的延迟时间。那么当新到一个时间戳为 t 的数据时,当前水位线的时间推进到了 t – 1(还记得乱序流里生成水位线的减一操作吗?)。所以当时间戳为 end 的数据到来时,水位线推进到了 end - 1;如果我们把窗口定义为不包含 end,那么当前的水位线刚好就是 maxTimestamp,表示窗口能够包含的数据都已经到齐,我们就可以直接关闭窗口了。所以有了这样的定义,我们就不需要再去考虑那烦人的“减一”了,直接看到时间戳为 end 的数据,就关闭对应的窗口。如果为乱序流设置了水位线延迟时间 delay,也只需要等到时间戳为 end + delay 的数据,就可以关窗了。
为了更容易理解,本书中我们对水位线的分析,统一不再考虑“减一”的问题。
计数窗口(Count Window )
计数窗口基于元素的个数来截取数据,到达固定的个数时就触发计算并关闭窗口。这相当于座位有限、“人满就发车”,是否发车与时间无关。每个窗口截取数据的个数,就是窗口的大小。
计数窗口相比时间窗口就更加简单,我们只需指定窗口大小,就可以把数据分配到对应的窗口中了。在 Flink 内部也并没有对应的类来表示计数窗口,底层是通过“全局窗口”(Global Window)来实现的。关于全局窗口,我们稍后讲解。
# 按照窗口分配数据的规则分类
时间窗口和计数窗口,只是对窗口的一个大致划分;在具体应用时,还需要定义更加精细的规则,来控制数据应该划分到哪个窗口中去。不同的分配数据的方式,就可以有不同的功能
根据分配数据的规则,窗口的具体实现可以分为 4 类:滚动窗口(Tumbling Window)、滑动窗口(Sliding Window)、会话窗口(Session Window),以及全局窗口(Global Window)。下面我们来做具体介绍。
滚动窗口(Tumbling Windows)
滚动窗口有固定的大小,是一种对数据进行“均匀切片”的划分方式。窗口之间没有重叠,也不会有间隔,是“首尾相接”的状态。如果我们把多个窗口的创建,看作一个窗口的运动,那就好像它在不停地向前“翻滚”一样。这是最简单的窗口形式,我们之前所举的例子都是滚动窗口。也正是因为滚动窗口是“无缝衔接”,所以每个数据都会被分配到一个窗口,而且只会属于一个窗口。
滚动窗口可以基于时间定义,也可以基于数据个数定义;需要的参数只有一个,就是窗口的大小(window size)。比如我们可以定义一个长度为 1 小时的滚动时间窗口,那么每个小时就会进行一次统计;或者定义一个长度为 10 的滚动计数窗口,就会每 10 个数进行一次统计。
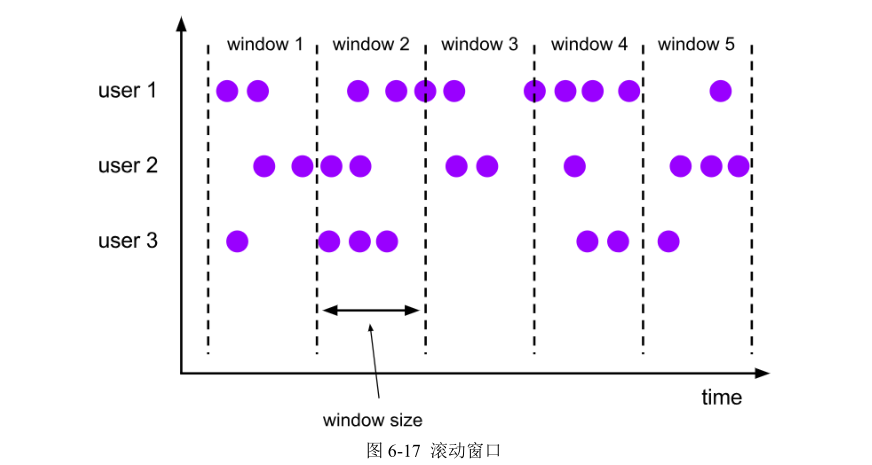
如图 6-17 所示,小圆点表示流中的数据,我们对数据按照 userId 做了分区。当固定了窗口大小之后,所有分区的窗口划分都是一致的;窗口没有重叠,每个数据只属于一个窗口。
滚动窗口应用非常广泛,它可以对每个时间段做聚合统计,很多 BI 分析指标都可以用它来实现。
滑动窗口(Sliding Windows )
与滚动窗口类似,滑动窗口的大小也是固定的。区别在于,窗口之间并不是首尾相接的,而是可以“错开”一定的位置。如果看作一个窗口的运动,那么就像是向前小步“滑动”一样。
既然是向前滑动,那么每一步滑多远,就也是可以控制的。所以定义滑动窗口的参数有两个:除去窗口大小(window size)之外,还有一个“滑动步长”(window slide),它其实就代表了窗口计算的频率。滑动的距离代表了下个窗口开始的时间间隔,而窗口大小是固定的,所以也就是两个窗口结束时间的间隔;窗口在结束时间触发计算输出结果,那么滑动步长就代表了计算频率。例如,我们定义一个长度为 1 小时、滑动步长为 5 分钟的滑动窗口,那么就会统 计 1 小时内的数据,每 5 分钟统计一次。同样,滑动窗口可以基于时间定义,也可以基于数据个数定义。

我们可以看到,当滑动步长小于窗口大小时,滑动窗口就会出现重叠,这时数据也可能会被同时分配到多个窗口中。而具体的个数,就由窗口大小和滑动步长的比值(size/slide)来决定。如图 6-18 所示,滑动步长刚好是窗口大小的一半,那么每个数据都会被分配到 2 个窗口里。比如我们定义的窗口长度为 1 小时、滑动步长为 30 分钟,那么对于 8 点 55 分的数据,应该同时属于[8 点, 9 点)和[8 点半, 9 点半)两个窗口;而对于 8 点 10 分的数据,则同时属于[8点, 9 点)和[7 点半, 8 点半)两个窗口。
所以,滑动窗口其实是固定大小窗口的更广义的一种形式;换句话说,滚动窗口也可以看作是一种特殊的滑动窗口——窗口大小等于滑动步长(size = slide)。当然,我们也可以定义滑动步长大于窗口大小,这样的话就会出现窗口不重叠、但会有间隔的情况;这时有些数据不属于任何一个窗口,就会出现遗漏统计。所以一般情况下,我们会让滑动步长小于窗口大小,并尽量设置为整数倍的关系。
在一些场景中,可能需要统计最近一段时间内的指标,而结果的输出频率要求又很高,甚至要求实时更新,比如股票价格的 24 小时涨跌幅统计,或者基于一段时间内行为检测的异常报警。这时滑动窗口无疑就是很好的实现方式。
会话窗口(Session Windows)
会话窗口顾名思义,是基于“会话”(session)来来对数据进行分组的。这里的会话类似Web 应用中 session 的概念,不过并不表示两端的通讯过程,而是借用会话超时失效的机制来描述窗口。简单来说,就是数据来了之后就开启一个会话窗口,如果接下来还有数据陆续到来,那么就一直保持会话;如果一段时间一直没收到数据,那就认为会话超时失效,窗口自动关闭。这就好像我们打电话一样,如果时不时总能说点什么,那说明还没聊完;如果陷入了尴尬的沉默,半天都没话说,那自然就可以挂电话了。
与滑动窗口和滚动窗口不同,会话窗口只能基于时间来定义,而没有“会话计数窗口”的概念。这很好理解,“会话”终止的标志就是“隔一段时间没有数据来”,如果不依赖时间而改成个数,就成了“隔几个数据没有数据来”,这完全是自相矛盾的说法。
而同样是基于这个判断标准,这“一段时间”到底是多少就很重要了,必须明确指定。对于会话窗口而言,最重要的参数就是这段时间的长度(size),它表示会话的超时时间,也就是两个会话窗口之间的最小距离。如果相邻两个数据到来的时间间隔(Gap)小于指定的大小(size),那说明还在保持会话,它们就属于同一个窗口;如果 gap 大于 size,那么新来的数据就应该属于新的会话窗口,而前一个窗口就应该关闭了。在具体实现上,我们可以设置静态固定的大小(size),也可以通过一个自定义的提取器(gap extractor)动态提取最小间隔 gap 的值。
考虑到事件时间语义下的乱序流,这里又会有一些麻烦。相邻两个数据的时间间隔 gap大于指定的 size,我们认为它们属于两个会话窗口,前一个窗口就关闭;可在数据乱序的情况下,可能会有迟到数据,它的时间戳刚好是在之前的两个数据之间的。这样一来,之前我们判断的间隔中就不是“一直没有数据”,而缩小后的间隔有可能会比 size 还要小——这代表三个数据本来应该属于同一个会话窗口。
所以在 Flink 底层,对会话窗口的处理会比较特殊:每来一个新的数据,都会创建一个新的会话窗口;然后判断已有窗口之间的距离,如果小于给定的 size,就对它们进行合并(merge)操作。在 Window 算子中,对会话窗口会有单独的处理逻辑。
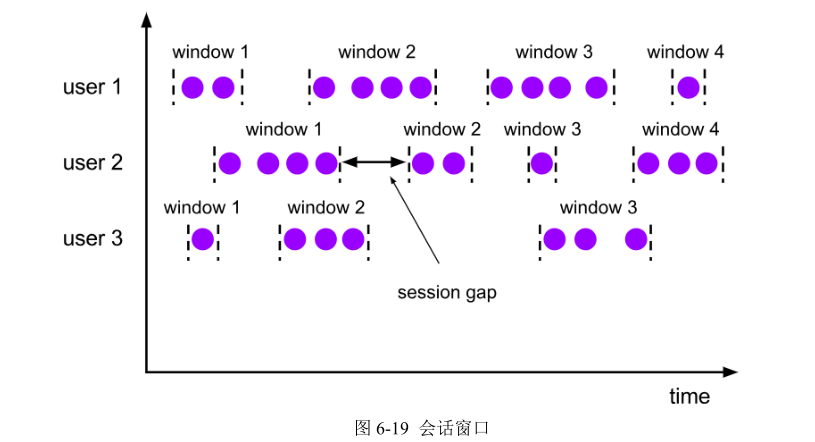
我们可以看到,与前两种窗口不同,会话窗口的长度不固定,起始和结束时间也是不确定的,各个分区之间窗口没有任何关联。如图 6-19 所示,会话窗口之间一定是不会重叠的,而且会留有至少为 size 的间隔(session gap)。
在一些类似保持会话的场景下,往往可以使用会话窗口来进行数据的处理统计。
全局窗口(Global Windows)
还有一类比较通用的窗口,就是“全局窗口”。这种窗口全局有效,会把相同 key 的所有数据都分配到同一个窗口中;说直白一点,就跟没分窗口一样。无界流的数据永无止尽,所以这种窗口也没有结束的时候,默认是不会做触发计算的。如果希望它能对数据进行计算处理,还需要自定义“触发器”(Trigger)。关于触发器,我们会在后面的 6.3.6 小节进行讲解。
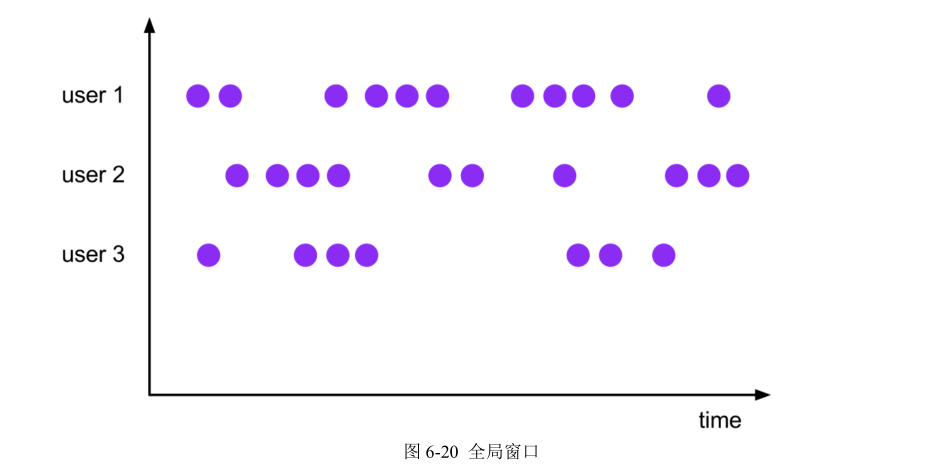
如图 6-20 所示,可以看到,全局窗口没有结束的时间点,所以一般在希望做更加灵活的窗口处理时自定义使用。Flink 中的计数窗口(Count Window),底层就是用全局窗口实现的。
# 窗口 API 概览
# 按键分区(Keyed)和非按键分区(Non-Keyed)
在定义窗口操作之前,首先需要确定,到底是基于按键分区(Keyed)的数据流 KeyedStream来开窗,还是直接在没有按键分区的 DataStream 上开窗。也就是说,在调用窗口算子之前,是否有 keyBy 操作。
按键分区窗口(Keyed Windows)
经过按键分区 keyBy 操作后,数据流会按照 key 被分为多条逻辑流(logical streams),这就是 KeyedStream。基于 KeyedStream 进行窗口操作时, 窗口计算会在多个并行子任务上同时执行。相同 key 的数据会被发送到同一个并行子任务,而窗口操作会基于每个 key 进行单独的处理。所以可以认为,每个 key 上都定义了一组窗口,各自独立地进行统计计算。
在代码实现上,我们需要先对 DataStream 调用.keyBy()进行按键分区,然后再调用.window()定义窗口。
stream.keyBy(...) .window(...)1
2非按键分区(Non-Keyed Windows)
如果没有进行 keyBy,那么原始的 DataStream 就不会分成多条逻辑流。这时窗口逻辑只能在一个任务(task)上执行,就相当于并行度变成了 1。所以在实际应用中一般不推荐使用这种方式。
在代码中,直接基于 DataStream 调用.windowAll()定义窗口。
stream.windowAll(...)1这里需要注意的是,对于非按键分区的窗口操作,手动调大窗口算子的并行度也是无效的,windowAll 本身就是一个非并行的操作。
# 代码中窗口 API 的调用
有了前置的基础,接下来我们就可以真正在代码中实现一个窗口操作了。简单来说,窗口操作主要有两个部分:窗口分配器(Window Assigners)和窗口函数(Window Functions)。
stream.keyBy(<key selector>)
.window(<window assigner>)
.aggregate(<window function>)
2
3
其中.window()方法需要传入一个窗口分配器,它指明了窗口的类型;而后面的.aggregate()方法传入一个窗口函数作为参数,它用来定义窗口具体的处理逻辑。窗口分配器有各种形式,而窗口函数的调用方法也不只.aggregate()一种,我们接下来就详细展开讲解。
另外,在实际应用中,一般都需要并行执行任务,非按键分区很少用到,所以我们之后都以按键分区窗口为例;如果想要实现非按键分区窗口,只要前面不做 keyBy,后面调用.window()时直接换成.windowAll()就可以了
# 窗口分配器(Window Assigners)
定义窗口分配器(Window Assigners)是构建窗口算子的第一步,它的作用就是定义数据应该被“分配”到哪个窗口。从 6.3.2 节的介绍中我们知道,窗口分配数据的规则,其实就对应着不同的窗口类型。所以可以说,窗口分配器其实就是在指定窗口的类型。
窗口分配器最通用的定义方式,就是调用.window()方法。这个方法需要传入一个WindowAssigner 作为参数,返回 WindowedStream。如果是非按键分区窗口,那么直接调用.windowAll()方法,同样传入一个 WindowAssigner,返回的是 AllWindowedStream。
窗口按照驱动类型可以分成时间窗口和计数窗口,而按照具体的分配规则,又有滚动窗口、滑动窗口、会话窗口、全局窗口四种。除去需要自定义的全局窗口外,其他常用的类型 Flink中都给出了内置的分配器实现,我们可以方便地调用实现各种需求。
# 时间窗口
时间窗口是最常用的窗口类型,又可以细分为滚动、滑动和会话三种。
在较早的版本中,可以直接调用.timeWindow()来定义时间窗口;这种方式非常简洁,但使用事件时间语义时需要另外声明,程序员往往因为忘记这点而导致运行结果错误。所以在1.12 版本之后,这种方式已经被弃用了,标准的声明方式就是直接调用.window(),在里面传入对应时间语义下的窗口分配器。这样一来,我们不需要专门定义时间语义,默认就是事件时间;如果想用处理时间,那么在这里传入处理时间的窗口分配器就可以了。
下面我们列出了每种情况的代码实现。
滚动处理时间窗口
窗口分配器由类 TumblingProcessingTimeWindows 提供,需要调用它的静态方法.of()
stream.keyBy(...)
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.aggregate(...)
2
3
这里.of()方法需要传入一个 Time 类型的参数 size,表示滚动窗口的大小,我们这里创建了一个长度为 5 秒的滚动窗口
另外,.of()还有一个重载方法,可以传入两个 Time 类型的参数:size 和 offset。第一个参数当然还是窗口大小,第二个参数则表示窗口起始点的偏移量。这里需要多做一些解释:对于我们之前的定义,滚动窗口其实只有一个 size 是不能唯一确定的。比如我们定义 1 天的滚动窗口,从每天的 0 点开始计时是可以的,统计的就是一个自然日的所有数据;而如果从每天的凌晨 2 点开始计时其实也完全没问题,只不过统计的数据变成了每天 2 点到第二天 2 点。这个起始点的选取,其实对窗口本身的类型没有影响;而为了方便应用,默认的起始点时间戳是窗口大小的整倍数。也就是说,如果我们定义 1 天的窗口,默认就从 0 点开始;如果定义 1 小时的窗口,默认就从整点开始。而如果我们非要不从这个默认值开始,那就可以通过设置偏移量offset 来调整。
这里读者可能会觉得奇怪:这个功能好像没什么用,非要弄个偏移量不是给自己找别扭吗?这其实是有实际用途的。我们知道,不同国家分布在不同的时区。标准时间戳其实就是1970 年 1 月 1 日 0 时 0 分 0 秒 0 毫秒开始计算的一个毫秒数,而这个时间是以 UTC 时间,也就是 0 时区(伦敦时间)为标准的。我们所在的时区是东八区,也就是 UTC+8,跟 UTC 有 8小时的时差。我们定义 1 天滚动窗口时,如果用默认的起始点,那么得到就是伦敦时间每天 0点开启窗口,这时是北京时间早上 8 点。那怎样得到北京时间每天 0 点开启的滚动窗口呢?只要设置-8 小时的偏移量就可以了:
.window(TumblingProcessingTimeWindows.of(Time.days(1), Time.hours(-8)))
滑动处理时间窗口
窗口分配器由类 SlidingProcessingTimeWindows 提供,同样需要调用它的静态方法.of()。
stream.keyBy(...)
.window(SlidingProcessingTimeWindows.of(Time.seconds(10), Time.seconds(5)))
.aggregate(...)
2
3
这里.of()方法需要传入两个 Time 类型的参数:size 和 slide,前者表示滑动窗口的大小,后者表示滑动窗口的滑动步长。我们这里创建了一个长度为 10 秒、滑动步长为 5 秒的滑动窗口。
滑动窗口同样可以追加第三个参数,用于指定窗口起始点的偏移量,用法与滚动窗口完全一致。
处理时间会话窗口
窗口分配器由类 ProcessingTimeSessionWindows 提供,需要调用它的静态方法.withGap()或者.withDynamicGap()。
stream.keyBy(...)
.window(ProcessingTimeSessionWindows.withGap(Time.seconds(10)))
.aggregate(...)
2
3
这里.withGap()方法需要传入一个 Time 类型的参数 size,表示会话的超时时间,也就是最小间隔 session gap。我们这里创建了静态会话超时时间为 10 秒的会话窗口。
.window(ProcessingTimeSessionWindows.withDynamicGap(new
SessionWindowTimeGapExtractor<Tuple2<String, Long>>() {
@Override
public long extract(Tuple2<String, Long> element) {
// 提取 session gap 值返回, 单位毫秒
return element.f0.length() * 1000;
}
}))
2
3
4
5
6
7
8
这里.withDynamicGap()方法需要传入一个 SessionWindowTimeGapExtractor 作为参数,用来定义 session gap 的动态提取逻辑。在这里,我们提取了数据元素的第一个字段,用它的长度乘以 1000 作为会话超时的间隔。
滚动事件时间窗口
窗口分配器由类 TumblingEventTimeWindows 提供,用法与滚动处理事件窗口完全一致。
stream.keyBy(...)
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.aggregate(...)
2
3
这里.of()方法也可以传入第二个参数 offset,用于设置窗口起始点的偏移量。
滑动事件时间窗口
窗口分配器由类 SlidingEventTimeWindows 提供,用法与滑动处理事件窗口完全一致。
stream.keyBy(...)
.window(SlidingEventTimeWindows.of(Time.seconds(10), Time.seconds(5)))
.aggregate(...)
2
3
事件时间会话窗口
窗口分配器由类 EventTimeSessionWindows 提供,用法与处理事件会话窗口完全一致。
stream.keyBy(...)
.window(EventTimeSessionWindows.withGap(Time.seconds(10)))
.aggregate(...)
2
3
# 计数窗口
计数窗口概念非常简单,本身底层是基于全局窗口(Global Window)实现的。Flink 为我们提供了非常方便的接口:直接调用.countWindow()方法。根据分配规则的不同,又可以分为滚动计数窗口和滑动计数窗口两类,下面我们就来看它们的具体实现。
滚动计数窗口
滚动计数窗口只需要传入一个长整型的参数 size,表示窗口的大小。
stream.keyBy(...)
.countWindow(10)
2
我们定义了一个长度为 10 的滚动计数窗口,当窗口中元素数量达到 10 的时候,就会触发计算执行并关闭窗口。
滑动计数窗口
与滚动计数窗口类似,不过需要在.countWindow()调用时传入两个参数:size 和 slide,前者表示窗口大小,后者表示滑动步长。
stream.keyBy(...)
.countWindow(10,3)
2
我们定义了一个长度为 10、滑动步长为 3 的滑动计数窗口。每个窗口统计 10 个数据,每隔 3 个数据就统计输出一次结果
# 全局窗口
全局窗口是计数窗口的底层实现,一般在需要自定义窗口时使用。它的定义同样是直接调用.window(),分配器由 GlobalWindows 类提供。
stream.keyBy(...)
.window(GlobalWindows.create());
2
需要注意使用全局窗口,必须自行定义触发器才能实现窗口计算,否则起不到任何作用。
# 窗口函数(Window Functions)
定义了窗口分配器,我们只是知道了数据属于哪个窗口,可以将数据收集起来了;至于收集起来到底要做什么,其实还完全没有头绪。所以在窗口分配器之后,必须再接上一个定义窗口如何进行计算的操作,这就是所谓的“窗口函数”(window functions)。
经窗口分配器处理之后,数据可以分配到对应的窗口中,而数据流经过转换得到的数据类型是 WindowedStream。这个类型并不是 DataStream,所以并不能直接进行其他转换,而必须进一步调用窗口函数,对收集到的数据进行处理计算之后,才能最终再次得到 DataStream,如图 6-21 所示。
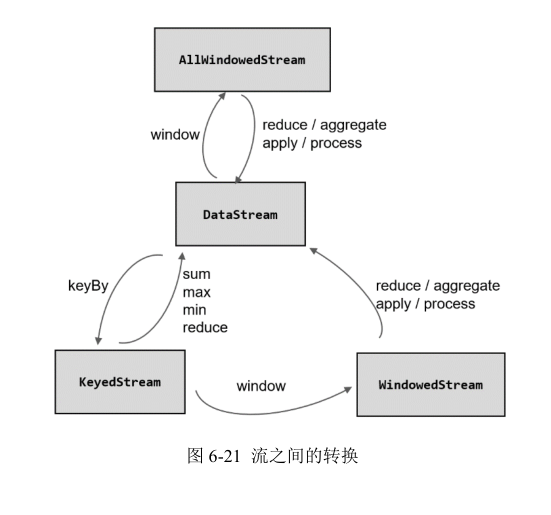
窗口函数定义了要对窗口中收集的数据做的计算操作,根据处理的方式可以分为两类:增量聚合函数和全窗口函数。下面我们来进行分别讲解。
# 增量聚合函数(incremental aggregation functions)
窗口将数据收集起来,最基本的处理操作当然就是进行聚合。窗口对无限流的切分,可以看作得到了一个有界数据集。如果我们等到所有数据都收集齐,在窗口到了结束时间要输出结果的一瞬间再去进行聚合,显然就不够高效了——这相当于真的在用批处理的思路来做实时流处理。
为了提高实时性,我们可以再次将流处理的思路发扬光大:就像 DataStream 的简单聚合一样,每来一条数据就立即进行计算,中间只要保持一个简单的聚合状态就可以了;区别只是在于不立即输出结果,而是要等到窗口结束时间。等到窗口到了结束时间需要输出计算结果的时候,我们只需要拿出之前聚合的状态直接输出,这无疑就大大提高了程序运行的效率和实时性。
典型的增量聚合函数有两个:ReduceFunction 和 AggregateFunction。
归约函数(ReduceFunction )
最基本的聚合方式就是归约(reduce)。我们在基本转换的聚合算子中介绍过 reduce 的用法,窗口的归约聚合也非常类似,就是将窗口中收集到的数据两两进行归约。当我们进行流处理时,就是要保存一个状态;每来一个新的数据,就和之前的聚合状态做归约,这样就实现了增量式的聚合。
窗口函数中也提供了 ReduceFunction:只要基于 WindowedStream 调用.reduce()方法,然后传入 ReduceFunction 作为参数,就可以指定以归约两个元素的方式去对窗口中数据进行聚合了。这里的 ReduceFunction 其实与简单聚合时用到的 ReduceFunction 是同一个函数类接口,所以使用方式也是完全一样的。
我们回忆一下,ReduceFunction 中需要重写一个 reduce 方法,它的两个参数代表输入的两个元素,而归约最终输出结果的数据类型,与输入的数据类型必须保持一致。也就是说,中间聚合的状态和输出的结果,都和输入的数据类型是一样的。
public class Demo_01_Window_Reduce {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 从自定义数据源读取数据,并提取时间戳、生成水位线
SingleOutputStreamOperator<Event> stream = env.addSource(new Demo_03_Source_Customer.ClickSource())
.assignTimestampsAndWatermarks(
WatermarkStrategy.<Event>forBoundedOutOfOrderness(Duration.ZERO)
.withTimestampAssigner(new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event element, long recordTimestamp)
{
return element.timestamp;
}
}));
stream.map(new MapFunction<Event, Tuple2<String, Long>>() {
@Override
public Tuple2<String, Long> map(Event value) throws Exception {
// 将数据转换成二元组,方便计算
System.out.println(value);
return Tuple2.of(value.user, 1L);
}
})
.keyBy(r -> r.f0)
// 设置滚动事件时间窗口
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.reduce(new ReduceFunction<Tuple2<String, Long>>() {
@Override
public Tuple2<String, Long> reduce(Tuple2<String, Long> value1, Tuple2<String, Long> value2) throws Exception {
// 定义累加规则,窗口闭合时,向下游发送累加结果
return Tuple2.of(value1.f0, value1.f1 + value2.f1);
}
}).print();
env.execute();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
聚合函数(AggregateFunction)
ReduceFunction 可以解决大多数归约聚合的问题,但是这个接口有一个限制,就是聚合状态的类型、输出结果的类型都必须和输入数据类型一样。这就迫使我们必须在聚合前,先将数据转换(map)成预期结果类型;而在有些情况下,还需要对状态进行进一步处理才能得到输出结果,这时它们的类型可能不同,使用 ReduceFunction 就会非常麻烦。
例如,如果我们希望计算一组数据的平均值,应该怎样做聚合呢?很明显,这时我们需要计算两个状态量:数据的总和(sum),以及数据的个数(count),而最终输出结果是两者的商(sum/count)。如果用 ReduceFunction,那么我们应该先把数据转换成二元组(sum, count)的形式,然后进行归约聚合,最后再将元组的两个元素相除转换得到最后的平均值。本来应该只是一个任务,可我们却需要 map-reduce-map 三步操作,这显然不够高效。
于是自然可以想到,如果取消类型一致的限制,让输入数据、中间状态、输出结果三者类型都可以不同,不就可以一步直接搞定了吗?
Flink 的 Window API 中的 aggregate 就提供了这样的操作。直接基于 WindowedStream 调用.aggregate()方法,就可以定义更加灵活的窗口聚合操作。这个方法需要传入一个AggregateFunction 的实现类作为参数。AggregateFunction 在源码中的定义如下:
public interface AggregateFunction<IN, ACC, OUT> extends Function, Serializable{
ACC createAccumulator();
ACC add(IN value, ACC accumulator);
OUT getResult(ACC accumulator);
ACC merge(ACC a, ACC b);
}
2
3
4
5
6
AggregateFunction 可以看作是 ReduceFunction 的通用版本,这里有三种类型:输入类型(IN)、累加器类型(ACC)和输出类型(OUT)。输入类型 IN 就是输入流中元素的数据类型;累加器类型 ACC 则是我们进行聚合的中间状态类型;而输出类型当然就是最终计算结果的类型了。
接口中有四个方法:
- createAccumulator():创建一个累加器,这就是为聚合创建了一个初始状态,每个聚合任务只会调用一次。
- add():将输入的元素添加到累加器中。这就是基于聚合状态,对新来的数据进行进一步聚合的过程。方法传入两个参数:当前新到的数据 value,和当前的累加器accumulator;返回一个新的累加器值,也就是对聚合状态进行更新。每条数据到来之后都会调用这个方法。
- getResult():从累加器中提取聚合的输出结果。也就是说,我们可以定义多个状态,然后再基于这些聚合的状态计算出一个结果进行输出。比如之前我们提到的计算平均值,就可以把 sum 和 count 作为状态放入累加器,而在调用这个方法时相除得到最终结果。这个方法只在窗口要输出结果时调用。
- merge():合并两个累加器,并将合并后的状态作为一个累加器返回。这个方法只在需要合并窗口的场景下才会被调用;最常见的合并窗口(Merging Window)的场景就是会话窗口(Session Windows)。
所以可以看到,AggregateFunction 的工作原理是:首先调用 createAccumulator()为任务初始化一个状态(累加器);而后每来一个数据就调用一次 add()方法,对数据进行聚合,得到的结果保存在状态中;等到了窗口需要输出时,再调用 getResult()方法得到计算结果。很明显,与 ReduceFunction 相同,AggregateFunction 也是增量式的聚合;而由于输入、中间状态、输出的类型可以不同,使得应用更加灵活方便。
下面来看一个具体例子。我们知道,在电商网站中,PV(页面浏览量)和 UV(独立访客数)是非常重要的两个流量指标。一般来说,PV 统计的是所有的点击量;而对用户 id 进行去重之后,得到的就是 UV。所以有时我们会用 PV/UV 这个比值,来表示“人均重复访问量”,也就是平均每个用户会访问多少次页面,这在一定程度上代表了用户的粘度。
public class Demo_02_Window_Aggregate {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 从自定义数据源读取数据,并提取时间戳、生成水位线
SingleOutputStreamOperator<Event> stream = env.addSource(new Demo_03_Source_Customer.ClickSource())
.assignTimestampsAndWatermarks(
WatermarkStrategy.<Event>forBoundedOutOfOrderness(Duration.ZERO)
.withTimestampAssigner(new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event element, long recordTimestamp)
{
return element.timestamp;
}
}));
stream
// 所有数据设置相同的 key,发送到同一个分区统计 PV 和 UV,再相除
.keyBy(r -> true)
// 设置滚动事件时间窗口
.window(SlidingEventTimeWindows.of(Time.seconds(10), Time.seconds(2)))
.aggregate(new AvgPv())
.print();
env.execute();
}
public static class AvgPv implements AggregateFunction<Event, Tuple2<HashSet<String>, Long>, Double> {
@Override
public Tuple2<HashSet<String>, Long> createAccumulator() {
// 创建累加器
return Tuple2.of(new HashSet<String>(), 0L);
}
@Override
public Tuple2<HashSet<String>, Long> add(Event value, Tuple2<HashSet<String>, Long> accumulator) {
// 属于本窗口的数据来一条累加一次,并返回累加器
accumulator.f0.add(value.user);
return Tuple2.of(accumulator.f0, accumulator.f1 + 1L);
}
@Override
public Double getResult(Tuple2<HashSet<String>, Long> accumulator) {
// 窗口闭合时,增量聚合结束,将计算结果发送到下游
return (double) accumulator.f1 / accumulator.f0.size();
}
@Override
public Tuple2<HashSet<String>, Long> merge(Tuple2<HashSet<String>, Long> a, Tuple2<HashSet<String>, Long> b) {
return null;
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
# 全窗口函数(full window functions)
窗口操作中的另一大类就是全窗口函数。与增量聚合函数不同,全窗口函数需要先收集窗口中的数据,并在内部缓存起来,等到窗口要输出结果的时候再取出数据进行计算。
很明显,这就是典型的批处理思路了——先攒数据,等一批都到齐了再正式启动处理流程。这样做毫无疑问是低效的:因为窗口全部的计算任务都积压在了要输出结果的那一瞬间,而在之前收集数据的漫长过程中却无所事事。这就好比平时不用功,到考试之前通宵抱佛脚,肯定不如把工夫花在日常积累上。
那为什么还需要有全窗口函数呢?这是因为有些场景下,我们要做的计算必须基于全部的数据才有效,这时做增量聚合就没什么意义了;另外,输出的结果有可能要包含上下文中的一些信息(比如窗口的起始时间),这是增量聚合函数做不到的。所以,我们还需要有更丰富的窗口计算方式,这就可以用全窗口函数来实现。
在 Flink 中,全窗口函数也有两种:WindowFunction 和 ProcessWindowFunction。
窗口函数(WindowFunction)
WindowFunction 字面上就是“窗口函数”,它其实是老版本的通用窗口函数接口。我们可以基于 WindowedStream 调用.apply()方法,传入一个 WindowFunction 的实现类。
stream
.keyBy(<key selector>)
.window(<window assigner>)
.apply(new MyWindowFunction());
2
3
4
这个类中可以获取到包含窗口所有数据的可迭代集合(Iterable),还可以拿到窗口(Window)本身的信息。WindowFunction 接口在源码中实现如下:
public interface WindowFunction<IN, OUT, KEY, W extends Window> extends Function,Serializable {
void apply(KEY key, W window, Iterable<IN> input, Collector<OUT> out) throws Exception;
}
2
3
当窗口到达结束时间需要触发计算时,就会调用这里的 apply 方法。我们可以从 input 集合中取出窗口收集的数据,结合 key 和 window 信息,通过收集器(Collector)输出结果。这里 Collector 的用法,与 FlatMapFunction 中相同。
不过我们也看到了,WindowFunction 能提供的上下文信息较少,也没有更高级的功能。事实上,它的作用可以被 ProcessWindowFunction 全覆盖,所以之后可能会逐渐弃用。一般在实际应用,直接使用 ProcessWindowFunction 就可以了。
处理窗口函数(ProcessWindowFunction)
ProcessWindowFunction 是 Window API 中最底层的通用窗口函数接口。之所以说它“最底层”,是因为除了可以拿到窗口中的所有数据之外ProcessWindowFunction 还可以获取到一个上下文对象”(Context)。这个上下文对象非常强大,不仅能够获取窗口信息,还可以访问当前的时间和状态信息。这里的时间就包括了处理时间(processing time)和事件时间水位线(eventtime watermark)。这就使得 ProcessWindowFunction 更加灵活、功能更加丰富。事实上,ProcessWindowFunction 是 Flink 底层 API——处理函数(process function)中的一员,关于处理函数我们会在后续章节展开讲解。
当 然 , 这 些 好 处 是 以 牺 牲 性 能 和 资 源 为 代 价 的 。 作 为 一 个 全 窗 口 函 数 ,ProcessWindowFunction 同样需要将所有数据缓存下来、等到窗口触发计算时才使用。它其实就是一个增强版的 WindowFunction。
具体使用跟 WindowFunction 非常类似,我们可以基于 WindowedStream 调用.process()方法,传入一个 ProcessWindowFunction 的实现类。下面是一个电商网站统计每小时 UV 的例子:
public class Demo_03_Window_Full {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 从自定义数据源读取数据,并提取时间戳、生成水位线
SingleOutputStreamOperator<Event> stream = env.addSource(new Demo_03_Source_Customer.ClickSource())
.assignTimestampsAndWatermarks(
WatermarkStrategy.<Event>forBoundedOutOfOrderness(Duration.ZERO)
.withTimestampAssigner(new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event element, long recordTimestamp)
{
return element.timestamp;
}
}));
// 将数据全部发往同一分区,按窗口统计 UV
stream.keyBy(data -> true)
.window(TumblingEventTimeWindows.of(Time.seconds(10)))
.process(new UvCountByWindow())
.print();
env.execute();
}
// 自定义窗口处理函数
public static class UvCountByWindow extends ProcessWindowFunction<Event, String, Boolean, TimeWindow> {
@Override
public void process(Boolean aBoolean, Context context, Iterable<Event> elements, Collector<String> out) throws Exception {
HashSet<String> userSet = new HashSet<>();
// 遍历所有数据,放到 Set 里去重
for (Event event : elements) {
userSet.add(event.user);
}
// 结合窗口信息,包装输出内容
Long start = context.window().getStart();
Long end = context.window().getEnd();
out.collect(" 窗 口 : " + new Timestamp(start) + " ~ " + new Timestamp(end) + " 的独立访客数量是:" + userSet.size());
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
这里我们使用的是事件时间语义。定义 10 秒钟的滚动事件窗口后,直接使用ProcessWindowFunction 来定义处理的逻辑。我们可以创建一个 HashSet,将窗口所有数据的userId 写入实现去重,最终得到 HashSet 的元素个数就是 UV 值。当 然 , 这 里 我 们 并 没 有 用 到 上 下 文 中 其 他 信 息 , 所 以 其 实 没 有 必 要 使 用ProcessWindowFunction。全窗口函数因为运行效率较低,很少直接单独使用,往往会和增量聚合函数结合在一起,共同实现窗口的处理计算。
# 增量聚合和全窗口函数的结合使用
我们已经了解了 Window API 中两类窗口函数的用法,下面我们先来做个简单的总结。
增量聚合函数处理计算会更高效。举一个最简单的例子,对一组数据求和。大量的数据连续不断到来,全窗口函数只是把它们收集缓存起来,并没有处理;到了窗口要关闭、输出结果的时候,再遍历所有数据依次叠加,得到最终结果。而如果我们采用增量聚合的方式,那么只需要保存一个当前和的状态,每个数据到来时就会做一次加法,更新状态;到了要输出结果的时候,只要将当前状态直接拿出来就可以了。增量聚合相当于把计算量“均摊”到了窗口收集数据的过程中,自然就会比全窗口聚合更加高效、输出更加实时。
而全窗口函数的优势在于提供了更多的信息,可以认为是更加“通用”的窗口操作。它只负责收集数据、提供上下文相关信息,把所有的原材料都准备好,至于拿来做什么我们完全可以任意发挥。这就使得窗口计算更加灵活,功能更加强大。
所以在实际应用中,我们往往希望兼具这两者的优点,把它们结合在一起使用。Flink 的Window API 就给我们实现了这样的用法。
我们之前在调用 WindowedStream 的.reduce()和.aggregate()方法时,只是简单地直接传入了一个 ReduceFunction 或 AggregateFunction 进行增量聚合。除此之外,其实还可以传入第二个参数:一个全窗口函数,可以是 WindowFunction 或者 ProcessWindowFunction。
// ReduceFunction 与 WindowFunction 结合
public <R> SingleOutputStreamOperator<R> reduce(ReduceFunction<T> reduceFunction, WindowFunction<T, R, K, W> function)
// ReduceFunction 与 ProcessWindowFunction 结合
public <R> SingleOutputStreamOperator<R> reduce(ReduceFunction<T> reduceFunction, ProcessWindowFunction<T, R, K, W> function)
// AggregateFunction 与 WindowFunction 结合
public <ACC, V, R> SingleOutputStreamOperator<R> aggregate(AggregateFunction<T, ACC, V> aggFunction, WindowFunction<V, R, K, W>
windowFunction)
// AggregateFunction 与 ProcessWindowFunction 结合
public <ACC, V, R> SingleOutputStreamOperator<R> aggregate(AggregateFunction<T, ACC, V> aggFunction,ProcessWindowFunction<V, R, K, W> windowFunction)
2
3
4
5
6
7
8
9
这样调用的处理机制是:基于第一个参数(增量聚合函数)来处理窗口数据,每来一个数据就做一次聚合;等到窗口需要触发计算时,则调用第二个参数(全窗口函数)的处理逻辑输出结果。需要注意的是,这里的全窗口函数就不再缓存所有数据了,而是直接将增量聚合函数的结果拿来当作了 Iterable 类型的输入。一般情况下,这时的可迭代集合中就只有一个元素了。
下面我们举一个具体的实例来说明。在网站的各种统计指标中,一个很重要的统计指标就是热门的链接;想要得到热门的 url,前提是得到每个链接的“热门度”。一般情况下,可以用url 的浏览量(点击量)表示热门度。我们这里统计 10 秒钟的 url 浏览量,每 5 秒钟更新一次;另外为了更加清晰地展示,还应该把窗口的起始结束时间一起输出。我们可以定义滑动窗口,并结合增量聚合函数和全窗口函数来得到统计结果。
public class Demo_04_Window_Demo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 从自定义数据源读取数据,并提取时间戳、生成水位线
SingleOutputStreamOperator<Event> stream = env.addSource(new Demo_03_Source_Customer.ClickSource())
.assignTimestampsAndWatermarks(
WatermarkStrategy.<Event>forBoundedOutOfOrderness(Duration.ZERO)
.withTimestampAssigner(new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event element, long recordTimestamp)
{
return element.timestamp;
}
}));
// 需要按照 url 分组,开滑动窗口统计
stream.keyBy(data -> data.url)
.window(SlidingEventTimeWindows.of(Time.seconds(10), Time.seconds(5)))
// 同时传入增量聚合函数和全窗口函数
.aggregate(new UrlViewCountAgg(), new UrlViewCountResult())
.print();
}
// 自定义增量聚合函数,来一条数据就加一
public static class UrlViewCountAgg implements AggregateFunction<Event, Long, Long> {
@Override
public Long createAccumulator() {
return 0L;
}
@Override
public Long add(Event value, Long accumulator) {
return accumulator + 1;
}
@Override
public Long getResult(Long accumulator) {
return accumulator;
}
@Override
public Long merge(Long a, Long b) {
return null;
}
}
// 自定义窗口处理函数,只需要包装窗口信息
public static class UrlViewCountResult extends ProcessWindowFunction<Long, UrlViewCount, String, TimeWindow> {
@Override
public void process(String url, Context context, Iterable<Long> elements, Collector<UrlViewCount> out) throws Exception {
// 结合窗口信息,包装输出内容
Long start = context.window().getStart();
Long end = context.window().getEnd();
// 迭代器中只有一个元素,就是增量聚合函数的计算结果
out.collect(new UrlViewCount(url, elements.iterator().next(), start, end));
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
代码中用一个 AggregateFunction 来实现增量聚合,每来一个数据就计数加一;得到的结果交给 ProcessWindowFunction,结合窗口信息包装成我们想要的 UrlViewCount,最终输出统计结果。
注:ProcessWindowFunction 是处理函数中的一种,后面我们会详细讲解。这里只用它来将增量聚合函数的输出结果包裹一层窗口信息。窗口处理的主体还是增量聚合,而引入全窗口函数又可以获取到更多的信息包装输出,这样的结合兼具了两种窗口函数的优势,在保证处理性能和实时性的同时支持了更加丰富的应用场景。
# 测试水位线和窗口的使用
之前讲过,当水位线到达窗口结束时间时,窗口就会闭合不再接收迟到的数据,因为根据水位线的定义,所有小于等于水位线的数据都已经到达,所以显然 Flink 会认为窗口中的数据都到达了(尽管可能存在迟到数据,也就是时间戳小于当前水位线的数据)。我们可以在之前生成水位线代码 WatermarkTest 的基础上,增加窗口应用做一下测试:
public class Demo_05_Window_Watermark_Test {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 将数据源改为 socket 文本流,并转换成 Event 类型
env.socketTextStream("ha01", 7777)
.map(new MapFunction<String, Event>() {
@Override
public Event map(String value) throws Exception {
String[] fields = value.split(",");
return new Event(fields[0].trim(), fields[1].trim(), Long.valueOf(fields[2].trim()));
}
})
// 插入水位线的逻辑
.assignTimestampsAndWatermarks(
// 针对乱序流插入水位线,延迟时间设置为 5s
WatermarkStrategy.<Event>forBoundedOutOfOrderness(Duration.ofSeconds(5))
.withTimestampAssigner(
new SerializableTimestampAssigner<Event>() {
// 抽取时间戳的逻辑
@Override
public long extractTimestamp(Event element, long recordTimestamp) {
return element.timestamp;
}
})
)
// 根据 user 分组,开窗统计
.keyBy(data -> data.user)
.window(TumblingEventTimeWindows.of(Time.seconds(10)))
.process(new WatermarkTestResult())
.print();
env.execute();
}
// 自定义处理窗口函数,输出当前的水位线和窗口信息
public static class WatermarkTestResult extends ProcessWindowFunction<Event, String, String, TimeWindow>{
@Override
public void process(String s, Context context, Iterable<Event> elements,
Collector<String> out) throws Exception {
Long start = context.window().getStart();
Long end = context.window().getEnd();
Long currentWatermark = context.currentWatermark();
Long count = elements.spliterator().getExactSizeIfKnown();
out.collect("窗口" + start + " ~ " + end + "中共有" + count + "个元素, 窗口闭合计算时,水位线处于:" + currentWatermark);
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
我们就会发现,当最后输入[Alice, ./prod?id=300, 15000]时,流中会周期性地(默认 200毫秒)插入一个时间戳为 15000L – 5 * 1000L – 1L = 9999 毫秒的水位线,已经到达了窗口[0,10000)的结束时间,所以会触发窗口的闭合计算。而后面再输入一条[Alice, ./prod?id=200,9000]时,将不会有任何结果;因为这是一条迟到数据,它所属于的窗口已经触发计算然后销毁了(窗口默认被销毁),所以无法再进入到窗口中,自然也就无法更新计算结果了。窗口中的迟到数据默认会被丢弃,这会导致计算结果不够准确。Flink 提供了有效处理迟到数据的手段,我们会在稍后的 6.4 节详细介绍。
# 其他 API
对于一个窗口算子而言,窗口分配器和窗口函数是必不可少的。除此之外,Flink 还提供了其他一些可选的 API,让我们可以更加灵活地控制窗口行为。
# 触发器(Trigger)
触发器主要是用来控制窗口什么时候触发计算。所谓的“触发计算”,本质上就是执行窗口函数,所以可以认为是计算得到结果并输出的过程。
stream.keyBy(...)
.window(...)
.trigger(new MyTrigger())
2
3
Trigger 是窗口算子的内部属性,每个窗口分配器(WindowAssigner)都会对应一个默认的触发器;对于 Flink 内置的窗口类型,它们的触发器都已经做了实现。例如,所有事件时间窗口,默认的触发器都是 EventTimeTrigger;类似还有 ProcessingTimeTrigger 和 CountTrigger。所以一般情况下是不需要自定义触发器的,不过我们依然有必要了解它的原理。Trigger 是一个抽象类,自定义时必须实现下面四个抽象方法:
- onElement():窗口中每到来一个元素,都会调用这个方法。
- onEventTime():当注册的事件时间定时器触发时,将调用这个方法。
- nProcessingTime ():当注册的处理时间定时器触发时,将调用这个方法。
- clear():当窗口关闭销毁时,调用这个方法。一般用来清除自定义的状态。
可以看到,除了 clear()比较像生命周期方法,其他三个方法其实都是对某种事件的响应。onElement()是对流中数据元素到来的响应;而另两个则是对时间的响应。这几个方法的参数中都有一个“触发器上下文”(TriggerContext)对象,可以用来注册定时器回调(callback)。这里提到的“定时器”(Timer),其实就是我们设定的一个“闹钟”,代表未来某个时间点会执行的事件;当时间进展到设定的值时,就会执行定义好的操作。很明显,对于时间窗口(TimeWindow)而言,就应该是在窗口的结束时间设定了一个定时器,这样到时间就可以触发窗口的计算输出了。关于定时器的内容,我们在后面讲解处理函数(process function)时还会提到。
上面的前三个方法可以响应事件,那它们又是怎样跟窗口操作联系起来的呢?这就需要了解一下它们的返回值。这三个方法返回类型都是 TriggerResult,这是一个枚举类型(enum),其中定义了对窗口进行操作的四种类型。
- CONTINUE(继续):什么都不做
- FIRE(触发):触发计算,输出结果
- PURGE(清除):清空窗口中的所有数据,销毁窗口
- FIRE_AND_PURGE(触发并清除):触发计算输出结果,并清除窗口
我们可以看到,Trigger 除了可以控制触发计算,还可以定义窗口什么时候关闭(销毁)。上面的四种类型,其实也就是这两个操作交叉配对产生的结果。一般我们会认为,到了窗口的结束时间,那么就会触发计算输出结果,然后关闭窗口——似乎这两个操作应该是同时发生的;但 TriggerResult 的定义告诉我们,两者可以分开。稍后我们就会看到它们分开操作的场景。
下面我们举一个例子。在日常业务场景中,我们经常会开比较大的窗口来计算每个窗口的pv 或者 uv 等数据。但窗口开的太大,会使我们看到计算结果的时间间隔变长。所以我们可以使用触发器,来隔一段时间触发一次窗口计算。我们在代码中计算了每个 url 在 10 秒滚动窗口的 pv 指标,然后设置了触发器,每隔 1 秒钟触发一次窗口的计算。
public class Demo_06_Trigger {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
env.addSource(new Demo_03_Source_Customer.ClickSource())
.assignTimestampsAndWatermarks(
WatermarkStrategy.<Event>forMonotonousTimestamps()
.withTimestampAssigner(
new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event event, long l) {
return event.timestamp;
}
})
)
.keyBy(r -> r.url)
.window(TumblingEventTimeWindows.of(Time.seconds(10)))
.trigger(new MyTrigger())
.process(new WindowResult())
.print();
env.execute();
}
public static class WindowResult extends ProcessWindowFunction<Event, UrlViewCount, String, TimeWindow> {
@Override
public void process(String s, Context context, Iterable<Event> iterable, Collector<UrlViewCount> collector) throws Exception {
collector.collect(
new UrlViewCount(s,
// 获取迭代器中的元素个数
iterable.spliterator().getExactSizeIfKnown(),
context.window().getStart(),
context.window().getEnd()
)
);
}
}
public static class MyTrigger extends Trigger<Event, TimeWindow> {
@Override
public TriggerResult onElement(Event event, long l, TimeWindow timeWindow,
TriggerContext triggerContext) throws Exception {
ValueState<Boolean> isFirstEvent = triggerContext.getPartitionedState(
new ValueStateDescriptor<Boolean>("first-event", Types.BOOLEAN)
);
if (isFirstEvent.value() == null) {
for (long i = timeWindow.getStart(); i < timeWindow.getEnd(); i =
i + 1000L) {
triggerContext.registerEventTimeTimer(i);
}
isFirstEvent.update(true);
}
return TriggerResult.CONTINUE;
}
@Override
public TriggerResult onEventTime(long l, TimeWindow timeWindow,
TriggerContext triggerContext) throws Exception {
return TriggerResult.FIRE;
}
@Override
public TriggerResult onProcessingTime(long l, TimeWindow timeWindow,
TriggerContext triggerContext) throws Exception {
return TriggerResult.CONTINUE;
}
@Override
public void clear(TimeWindow timeWindow, TriggerContext triggerContext)
throws Exception {
ValueState<Boolean> isFirstEvent =
triggerContext.getPartitionedState(
new ValueStateDescriptor<Boolean>("first-event",
Types.BOOLEAN)
);
isFirstEvent.clear();
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
# 移除器(Evictor)
移除器主要用来定义移除某些数据的逻辑。基于 WindowedStream 调用.evictor()方法,就可以传入一个自定义的移除器(Evictor)。Evictor 是一个接口,不同的窗口类型都有各自预实现的移除器。
stream.keyBy(...)
.window(...)
.evictor(new MyEvictor())
2
3
Evictor 接口定义了两个方法:
- evictBefore():定义执行窗口函数之前的移除数据操作
- evictAfter():定义执行窗口函数之后的以处数据操作
默认情况下,预实现的移除器都是在执行窗口函数(window fucntions)之前移除数据的。
# 允许延迟(Allowed Lateness)
在事件时间语义下,窗口中可能会出现数据迟到的情况。这是因为在乱序流中,水位线(watermark)并不一定能保证时间戳更早的所有数据不会再来。当水位线已经到达窗口结束时间时,窗口会触发计算并输出结果,这时一般也就要销毁窗口了;如果窗口关闭之后,又有本属于窗口内的数据姗姗来迟,默认情况下就会被丢弃。这也很好理解:窗口触发计算就像发车,如果要赶的车已经开走了,又不能坐其他的车(保证分配窗口的正确性),那就只好放弃坐班车了。
不过在多数情况下,直接丢弃数据也会导致统计结果不准确,我们还是希望该上车的人都能上来。为了解决迟到数据的问题,Flink 提供了一个特殊的接口,可以为窗口算子设置一个“允许的最大延迟”(Allowed Lateness)。也就是说,我们可以设定允许延迟一段时间,在这段时间内,窗口不会销毁,继续到来的数据依然可以进入窗口中并触发计算。直到水位线推进到了 窗口结束时间 + 延迟时间,才真正将窗口的内容清空,正式关闭窗口。
基于 WindowedStream 调用.allowedLateness()方法,传入一个 Time 类型的延迟时间,就可以表示允许这段时间内的延迟数据。
stream.keyBy(...)
.window(TumblingEventTimeWindows.of(Time.hours(1)))
.allowedLateness(Time.minutes(1))
2
3
比如上面的代码中,我们定义了 1 小时的滚动窗口,并设置了允许 1 分钟的延迟数据。也就是说,在不考虑水位线延迟的情况下,对于 8 点~9 点的窗口,本来应该是水位线到达 9 点整就触发计算并关闭窗口;现在允许延迟 1 分钟,那么 9 点整就只是触发一次计算并输出结果,并不会关窗。后续到达的数据,只要属于 8 点~9 点窗口,依然可以在之前统计的基础上继续叠加,并且再次输出一个更新后的结果。直到水位线到达了 9 点零 1 分,这时就真正清空状态、关闭窗口,之后再来的迟到数据就会被丢弃了。
从这里我们就可以看到,窗口的触发计算(Fire)和清除(Purge)操作确实可以分开。不过在默认情况下,允许的延迟是 0,这样一旦水位线到达了窗口结束时间就会触发计算并清除窗口,两个操作看起来就是同时发生了。当窗口被清除(关闭)之后,再来的数据就会被丢弃。
# 将迟到的数据放入侧输出流
我们自然会想到,即使可以设置窗口的延迟时间,终归还是有限的,后续的数据还是会被丢弃。如果不想丢弃任何一个数据,又该怎么做呢?
Flink 还提供了另外一种方式处理迟到数据。我们可以将未收入窗口的迟到数据,放入“侧输出流”(side output)进行另外的处理。所谓的侧输出流,相当于是数据流的一个“分支”,这个流中单独放置那些错过了该上的车、本该被丢弃的数据。
基于 WindowedStream 调用.sideOutputLateData() 方法,就可以实现这个功能。方法需要传入一个“输出标签”(OutputTag),用来标记分支的迟到数据流。因为保存的就是流中的原始数据,所以 OutputTag 的类型与流中数据类型相同。
DataStream<Event> stream = env.addSource(...);
OutputTag<Event> outputTag = new OutputTag<Event>("late") {};
stream.keyBy(...)
.window(TumblingEventTimeWindows.of(Time.hours(1)))
.sideOutputLateData(outputTag)
2
3
4
5
将迟到数据放入侧输出流之后,还应该可以将它提取出来。基于窗口处理完成之后的DataStream,调用.getSideOutput()方法,传入对应的输出标签,就可以获取到迟到数据所在的流了。
SingleOutputStreamOperator<AggResult> winAggStream = stream.keyBy(...)
.window(TumblingEventTimeWindows.of(Time.hours(1)))
.sideOutputLateData(outputTag)
.aggregate(new MyAggregateFunction())
DataStream<Event> lateStream = winAggStream.getSideOutput(outputTag);
2
3
4
5
这里注意,getSideOutput()是 SingleOutputStreamOperator 的方法,获取到的侧输出流数据类型应该和 OutputTag 指定的类型一致,与窗口聚合之后流中的数据类型可以不同。
# 窗口的生命周期
窗口的创建
窗口的类型和基本信息由窗口分配器(window assigners)指定,但窗口不会预先创建好,而是由数据驱动创建。当第一个应该属于这个窗口的数据元素到达时,就会创建对应的窗口。
窗口计算的触发
除了窗口分配器,每个窗口还会有自己的窗口函数(window functions)和触发器(trigger)。窗口函数可以分为增量聚合函数和全窗口函数,主要定义了窗口中计算的逻辑;而触发器则是指定调用窗口函数的条件。
对于不同的窗口类型,触发计算的条件也会不同。例如,一个滚动事件时间窗口,应该在水位线到达窗口结束时间的时候触发计算,属于“定点发车”;而一个计数窗口,会在窗口中元素数量达到定义大小时触发计算,属于“人满就发车”。所以 Flink 预定义的窗口类型都有对应内置的触发器。
对于事件时间窗口而言,除去到达结束时间的“定点发车”,还有另一种情形。当我们设置了允许延迟,那么如果水位线超过了窗口结束时间、但还没有到达设定的最大延迟时间,这期间内到达的迟到数据也会触发窗口计算。这类似于没有准时赶上班车的人又追上了车,这时车要再次停靠、开门,将新的数据整合统计进来
窗口的销毁
一般情况下,当时间达到了结束点,就会直接触发计算输出结果、进而清除状态销毁窗口。这时窗口的销毁可以认为和触发计算是同一时刻。这里需要注意,Flink 中只对时间窗口(TimeWindow)有销毁机制;由于计数窗口(CountWindow)是基于全局窗口(GlobalWindw)实现的,而全局窗口不会清除状态,所以就不会被销毁。
在特殊的场景下,窗口的销毁和触发计算会有所不同。事件时间语义下,如果设置了允许延迟,那么在水位线到达窗口结束时间时,仍然不会销毁窗口;窗口真正被完全删除的时间点,是窗口的结束时间加上用户指定的允许延迟时间。
窗口 API 调用总结
到目前为止,我们已经彻底明白了 Flink 中窗口的概念和 Window API 的调用,我们再用一张图做一个完整总结,如图 6-22 所示。

Window API 首先按照时候按键分区分成两类。keyBy 之后的 KeyedStream,可以调用.window()方法声明按键分区窗口(Keyed Windows);而如果不做 keyBy,DataStream 也可以直接调用.windowAll()声明非按键分区窗口。之后的方法调用就完全一样了。
接下来首先是通过.window()/.windowAll()方法定义窗口分配器,得到 WindowedStream;然 后 通 过 各 种 转 换 方 法 ( reduce/aggregate/apply/process ) 给 出 窗 口 函 数(ReduceFunction/AggregateFunction/ProcessWindowFunction),定义窗口的具体计算处理逻辑,转换之后重新得到 DataStream。这两者必不可少,是窗口算子(WindowOperator)最重要的组成部分。
此外,在这两者之间,还可以基于 WindowedStream 调用.trigger()自定义触发器、调用.evictor()定义移除器、调用.allowedLateness()指定允许延迟时间、调用.sideOutputLateData()将迟到数据写入侧输出流,这些都是可选的 API,一般不需要实现。而如果定义了侧输出流,可以基于窗口聚合之后的 DataStream 调用.getSideOutput()获取侧输出流。
# 迟到数据的处理
有了事件时间、水位线和窗口的相关知识,现在就可以系统性地讨论一下怎样处理迟到数据了。我们知道,所谓的“迟到数据”(late data),是指某个水位线之后到来的数据,它的时间戳其实是在水位线之前的。所以只有在事件时间语义下,讨论迟到数据的处理才是有意义的。
事件时间里用来表示时钟进展的就是水位线(watermark)。对于乱序流,水位线本身就可以设置一个延迟时间;而做窗口计算时,我们又可以设置窗口的允许延迟时间;另外窗口还有将迟到数据输出到测输出流的用法。所有的这些方法,它们之间有什么关系,我们又该怎样合理利用呢?这一节我们就来讨论这个问题。
# 设置水位线延迟时间
水位线是事件时间的进展,它是我们整个应用的全局逻辑时钟。水位线生成之后,会随着数据在任务间流动,从而给每个任务指明当前的事件时间。所以从这个意义上讲,水位线是一个覆盖万物的存在,它并不只针对事件时间窗口有效。
之前我们讲到触发器时曾提到过“定时器”,时间窗口的操作底层就是靠定时器来控制触发的。既然是底层机制,定时器自然就不可能是窗口的专利了;事实上它是 Flink 底层 API——处理函数(process function)的重要部分。
所以水位线其实是所有事件时间定时器触发的判断标准。那么水位线的延迟,当然也就是全局时钟的滞后,相当于是上帝拨动了琴弦,所有人的表都变慢了。
既然水位线这么重要,那一般情况就不应该把它的延迟设置得太大,否则流处理的实时性就会大大降低。因为水位线的延迟主要是用来对付分布式网络传输导致的数据乱序,而网络传输的乱序程度一般并不会很大,大多集中在几毫秒至几百毫秒。所以实际应用中,我们往往会给水位线设置一个“能够处理大多数乱序数据的小延迟”,视需求一般设在毫秒~秒级。
当我们设置了水位线延迟时间后,所有定时器就都会按照延迟后的水位线来触发。如果一个数据所包含的时间戳,小于当前的水位线,那么它就是所谓的“迟到数据”。
# 允许窗口处理迟到数据
水位线延迟设置的比较小,那之后如果仍有数据迟到该怎么办?对于窗口计算而言,如果水位线已经到了窗口结束时间,默认窗口就会关闭,那么之后再来的数据就要被丢弃了。
自然想到,Flink 的窗口也是可以设置延迟时间,允许继续处理迟到数据的。
这种情况下,由于大部分乱序数据已经被水位线的延迟等到了,所以往往迟到的数据不会太多。这样,我们会在水位线到达窗口结束时间时,先快速地输出一个近似正确的计算结果;然后保持窗口继续等到延迟数据,每来一条数据,窗口就会再次计算,并将更新后的结果输出。这样就可以逐步修正计算结果,最终得到准确的统计值了。
类比班车的例子,我们可以这样理解:大多数人是在发车时刻前后到达的,所以我们只要把表调慢,稍微等一会儿,绝大部分人就都上车了,这个把表调慢的时间就是水位线的延迟;到点之后,班车就准时出发了,不过可能还有该来的人没赶上。于是我们就先慢慢往前开,这段时间内,如果迟到的人抓点紧还是可以追上的;如果有人追上来了,就停车开门让他上来,然后车继续向前开。当然我们的车不能一直慢慢开,需要有一个时间限制,这就是窗口的允许延迟时间。一旦超过了这个时间,班车就不再停留,开上高速疾驰而去了。
所以我们将水位线的延迟和窗口的允许延迟数据结合起来,最后的效果就是先快速实时地输出一个近似的结果,而后再不断调整,最终得到正确的计算结果。回想流处理的发展过程,这不就是著名的 Lambda 架构吗?原先需要两套独立的系统来同时保证实时性和结果的最终正确性,如今 Flink 一套系统就全部搞定了。
# 将迟到数据放入窗口侧输出流
即使我们有了前面的双重保证,可窗口不能一直等下去,最后总要真正关闭。窗口一旦关闭,后续的数据就都要被丢弃了。那如果真的还有漏网之鱼又该怎么办呢?
那就要用到最后一招了:用窗口的侧输出流来收集关窗以后的迟到数据。这种方式是最后“兜底”的方法,只能保证数据不丢失;因为窗口已经真正关闭,所以是无法基于之前窗口的结果直接做更新的。我们只能将之前的窗口计算结果保存下来,然后获取侧输出流中的迟到数据,判断数据所属的窗口,手动对结果进行合并更新。尽管有些烦琐,实时性也不够强,但能够保证最终结果一定是正确的。
如果还用赶班车来类比,那就是车已经上高速开走了,这班车是肯定赶不上了。不过我们还留下了行进路线和联系方式,迟到的人如果想办法辗转到了目的地,还是可以和大部队会合的。最终,所有该到的人都会在目的地出现。
所以总结起来,Flink 处理迟到数据,对于结果的正确性有三重保障:水位线的延迟,窗口允许迟到数据,以及将迟到数据放入窗口侧输出流。我们可以回忆一下之前 6.3.5 小节统计每个 url 浏览次数的代码 UrlViewCountExample,稍作改进,增加处理迟到数据的功能。具体代码如下。
public class Demo_07_ProcessLateDataExample {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 读取 socket 文本流
SingleOutputStreamOperator<Event> stream =
env.socketTextStream("ha01", 7777)
.map(new MapFunction<String, Event>() {
@Override
public Event map(String value) throws Exception {
String[] fields = value.split(" ");
return new Event(fields[0].trim(), fields[1].trim(),
Long.valueOf(fields[2].trim()));
}
})
// 方式一:设置 watermark 延迟时间,2 秒钟
.assignTimestampsAndWatermarks(WatermarkStrategy.<Event>forBoundedOutOfOrderness(Duration.ofSeconds(2))
.withTimestampAssigner(new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event element, long
recordTimestamp) {
return element.timestamp;
}
}));
// 定义侧输出流标签
OutputTag<Event> outputTag = new OutputTag<Event>("late"){};
SingleOutputStreamOperator<UrlViewCount> result = stream.keyBy(data ->
data.url)
.window(TumblingEventTimeWindows.of(Time.seconds(10)))
// 方式二:允许窗口处理迟到数据,设置 1 分钟的等待时间
.allowedLateness(Time.minutes(1))
// 方式三:将最后的迟到数据输出到侧输出流
.sideOutputLateData(outputTag)
.aggregate(new UrlViewCountAgg(), new UrlViewCountResult());
result.print("result");
result.getSideOutput(outputTag).print("late");
// 为方便观察,可以将原始数据也输出
stream.print("input");
genv.execute();
}
public static class UrlViewCountAgg implements AggregateFunction<Event, Long,
Long> {
@Override
public Long createAccumulator() {
return 0L;
}
@Override
public Long add(Event value, Long accumulator) {
return accumulator + 1;
}
@Override
public Long getResult(Long accumulator) {
return accumulator;
}
@Override
public Long merge(Long a, Long b) {
return null;
}
}
public static class UrlViewCountResult extends ProcessWindowFunction<Long,
UrlViewCount, String, TimeWindow> {
@Override
public void process(String url, Context context, Iterable<Long> elements,
Collector<UrlViewCount> out) throws Exception {
// 结合窗口信息,包装输出内容
Long start = context.window().getStart();
Long end = context.window().getEnd();
out.collect(new UrlViewCount(url, elements.iterator().next(), start,
end));
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
# 本章总结
在流处理中,由于对实时性的要求非常高,同时又要求能够保证窗口操作结果的正确,所以必须引入水位线来描述事件时间。而窗口正是时间相关的最佳应用场景,所以 Flink 为我们提供了丰富的窗口类型和处理操作;与此同时,在实际应用中很难对乱序流给出一个最佳延迟时间,单独依赖水位线去保证结果正确性是不够的,所以需要结合窗口(Window)处理迟到数据的相关 API。本章我们详细了解了 Flink 中时间语义和水位线的概念、窗口 API 的用法以及处理迟到数据的相关知识,这些内容对于实时流处理来说非常重要。
Flink 的时间语义和窗口,主要就是为了处理大规模的乱序数据流时,同时保证低延迟、高吞吐和结果的正确性。这部分设计基本上是对谷歌(Google)著名论文《数据流模型:一种在大规模、无界、无序数据处理中平衡正确性、延迟和性能的实用方法》(The Dataflow Model:A Practical Approach to Balancing Correctness, Latency, and Cost in Massive-Scale, Unbounded,Out-of-Order Data Processing)的具体实现,如果读者有兴趣可以读一下原始论文,会对流处 理有更加深刻的理解。
# 处理函数
之前所介绍的流处理 API,无论是基本的转换、聚合,还是更为复杂的窗口操作,其实都是基于 DataStream 进行转换的;所以可以统称为 DataStream API,这也是 Flink 编程的核心。而我们知道,为了让代码有更强大的表现力和易用性,Flink 本身提供了多层 API,DataStreamAPI 只是中间的一环,如图 7-1 所示:
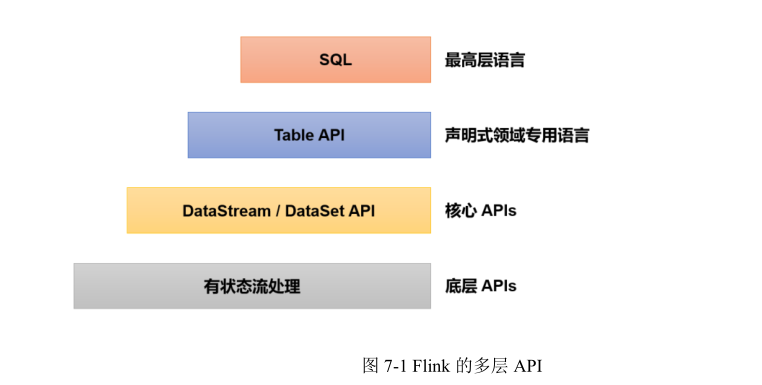
在更底层,我们可以不定义任何具体的算子(比如 map,filter,或者 window),而只是提炼出一个统一的“处理”(process)操作——它是所有转换算子的一个概括性的表达,可以自定义处理逻辑,所以这一层接口就被叫作“处理函数”(process function)。
在处理函数中,我们直面的就是数据流中最基本的元素:数据事件(event)、状态(state)以及时间(time)。这就相当于对流有了完全的控制权。处理函数比较抽象,没有具体的操作,所以对于一些常见的简单应用(比如求和、开窗口)会显得有些麻烦;不过正是因为它不限定具体做什么,所以理论上我们可以做任何事情,实现所有需求。所以可以说,处理函数是我们进行 Flink 编程的“大招”,轻易不用,一旦放出来必然会扫平一切。
# 基本处理函数(ProcessFunction)
处理函数主要是定义数据流的转换操作,所以也可以把它归到转换算子中。我们知道在Flink 中几乎所有转换算子都提供了对应的函数类接口,处理函数也不例外;它所对应的函数类,就叫作 ProcessFunction。
# 处理函数的功能和使用
我们之前学习的转换算子,一般只是针对某种具体操作来定义的,能够拿到的信息比较有限。比如 map 算子,我们实现的 MapFunction 中,只能获取到当前的数据,定义它转换之后的形式;而像窗口聚合这样的复杂操作,AggregateFunction 中除数据外,还可以获取到当前的状态(以累加器 Accumulator 形式出现)。另外我们还介绍过富函数类,比如 RichMapFunction,它提供了获取运行时上下文的方法 getRuntimeContext(),可以拿到状态,还有并行度、任务名 称之类的运行时信息。
但是无论那种算子,如果我们想要访问事件的时间戳,或者当前的水位线信息,都是完全做不到的。在定义生成规则之后,水位线会源源不断地产生,像数据一样在任务间流动,可我们却不能像数据一样去处理它;跟时间相关的操作,目前我们只会用窗口来处理。而在很多应用需求中,要求我们对时间有更精细的控制,需要能够获取水位线,甚至要“把控时间”、定义什么时候做什么事,这就不是基本的时间窗口能够实现的了。
于是必须祭出大招——处理函数(ProcessFunction)了。处理函数提供了一个“定时服务”(TimerService),我们可以通过它访问流中的事件(event)、时间戳(timestamp)、水位线(watermark),甚至可以注册“定时事件”。而且处理函数继承了 AbstractRichFunction 抽象类,所以拥有富函数类的所有特性,同样可以访问状态(state)和其他运行时信息。此外,处理函数还可以直接将数据输出到侧输出流(side output)中。所以,处理函数是最为灵活的处理方法,可以实现各种自定义的业务逻辑;同时也是整个 DataStream API 的底层基础。
处理函数的使用与基本的转换操作类似,只需要直接基于 DataStream 调用.process()方法就可以了。方法需要传入一个 ProcessFunction 作为参数,用来定义处理逻辑。
stream.process(new MyProcessFunction())
这里 ProcessFunction 不是接口,而是一个抽象类,继承了 AbstractRichFunction;MyProcessFunction 是它的一个具体实现。所以所有的处理函数,都是富函数(RichFunction),富函数可以调用的东西这里同样都可以调用。
下面是一个具体的应用示例:
public class Demo_01_ProcessFunction_Example {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 从自定义数据源读取数据,并提取时间戳、生成水位线
SingleOutputStreamOperator<Event> stream = env.addSource(new Demo_03_Source_Customer.ClickSource())
.assignTimestampsAndWatermarks(
WatermarkStrategy.<Event>forBoundedOutOfOrderness(Duration.ZERO)
.withTimestampAssigner(new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event element, long recordTimestamp)
{
return element.timestamp;
}
}));
stream.process(new ProcessFunction<Event, String>() {
@Override
public void processElement(Event event, ProcessFunction<Event, String>.Context context, Collector<String> out) throws Exception {
if (event.user.equals("Mary")) {
out.collect(event.user);
} else if (event.user.equals("Bob")) {
out.collect(event.user);
out.collect(event.user);
}
System.out.println(context.timerService().currentWatermark());
}
}).print();
env.execute();
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
这里我们在 ProcessFunction 中重写了.processElement()方法,自定义了一种处理逻辑:当数据的 user 为“Mary”时,将其输出一次;而如果为“Bob”时,将 user 输出两次。这里的输 出 , 是 通 过 调 用 out.collect() 来 实 现 的 。 另 外 我 们 还 可 以 调 用ctx.timerService().currentWatermark()来获取当前的水位线打印输出。 所以可以看到,ProcessFunction 函数有点像 FlatMapFunction 的升级版。可以实现 Map、Filter、FlatMap 的所有功能。很明显,处理函数非常强大,能够做很多之前做不到的事情。
接下来我们就深入 ProcessFunction 内部来进行详细了解。
# ProcessFunction 解析
在源码中我们可以看到,抽象类 ProcessFunction 继承了 AbstractRichFunction,有两个泛型类型参数:I 表示 Input,也就是输入的数据类型;O 表示 Output,也就是处理完成之后输出的数据类型。
内部单独定义了两个方法:一个是必须要实现的抽象方法.processElement();另一个是非抽象方法.onTimer()。
public abstract class ProcessFunction<I, O> extends AbstractRichFunction {
...
public abstract void processElement(I value, Context ctx, Collector<O> out) throws Exception;
public void onTimer(long timestamp, OnTimerContext ctx, Collector<O> out) throws Exception {}
...
}
2
3
4
5
6
抽象方法.processElement()
用于“处理元素”,定义了处理的核心逻辑。这个方法对于流中的每个元素都会调用一次,参数包括三个:输入数据值 value,上下文 ctx,以及“收集器”(Collector)out。方法没有返回值,处理之后的输出数据是通过收集器 out 来定义的。
value:当前流中的输入元素,也就是正在处理的数据,类型与流中数据类型一致。
ctx:类型是 ProcessFunction 中定义的内部抽象类 Context,表示当前运行的上下文,可以获取到当前的时间戳,并提供了用于查询时间和注册定时器的“定时服务”(TimerService),以及可以将数据发送到“侧输出流” (side output)的方法.output()。
Context 抽象类定义如下:
public abstract class Context { public abstract Long timestamp(); public abstract TimerService timerService(); public abstract <X> void output(OutputTag<X> outputTag, X value); }1
2
3
4
5out:“收集器”(类型为 Collector),用于返回输出数据。使用方式与 flatMap算子中的收集器完全一样,直接调用 out.collect()方法就可以向下游发出一个数据。这个方法可以多次调用,也可以不调用。
通过几个参数的分析不难发现,ProcessFunction 可以轻松实现 flatMap 这样的基本转换功能(当然 map、filter 更不在话下);而通过富函数提供的获取上下文方法.getRuntimeContext(),也可以自定义状态(state)进行处理,这也就能实现聚合操作的功能了。关于自定义状态的具体实现,我们会在后续“状态管理”一章中详细介绍。
非抽象方法.onTimer()
用于定义定时触发的操作,这是一个非常强大、也非常有趣的功能。这个方法只有在注册好的定时器触发的时候才会调用,而定时器是通过“定时服务”TimerService 来注册的。打个比方,注册定时器(timer)就是设了一个闹钟,到了设定时间就会响;而.onTimer()中定义的,就是闹钟响的时候要做的事。所以它本质上是一个基于时间的“回调”(callback)方法,通过时间的进展来触发;在事件时间语义下就是由水位线(watermark)来触发了。
与.processElement()类似,定时方法.onTimer()也有三个参数:时间戳(timestamp),上下文(ctx),以及收集器(out)。这里的 timestamp 是指设定好的触发时间,事件时间语义下当然就是水位线了。另外这里同样有上下文和收集器,所以也可以调用定时服务(TimerService),以及任意输出处理之后的数据
既然有.onTimer()方法做定时触发,我们用 ProcessFunction 也可以自定义数据按照时间分组、定时触发计算输出结果;这其实就实现了窗口(window)的功能。所以说 ProcessFunction是真正意义上的终极奥义,用它可以实现一切功能。
我们也可以看到,处理函数都是基于事件触发的。水位线就如同插入流中的一条数据一样;只不过处理真正的数据事件调用的是.processElement()方法,而处理水位线事件调用的是.onTimer()。
这里需要注意的是,上面的.onTimer()方法只是定时器触发时的操作,而定时器(timer)真正的设置需要用到上下文 ctx 中的定时服务。在 Flink 中,只有“按键分区流”KeyedStream才支持设置定时器的操作,所以之前的代码中我们并没有使用定时器。所以基于不同类型的流,可以使用不同的处理函数,它们之间还是有一些微小的区别的。接下来我们就介绍一下处理函数的分类。
# 处理函数的分类
Flink 中的处理函数其实是一个大家族,ProcessFunction 只是其中一员
我们知道,DataStream 在调用一些转换方法之后,有可能生成新的流类型;例如调用.keyBy()之后得到 KeyedStream,进而再调用.window()之后得到 WindowedStream。对于不同类型的流,其实都可以直接调用.process()方法进行自定义处理,这时传入的参数就都叫作处理函数。当然,它们尽管本质相同,都是可以访问状态和时间信息的底层 API,可彼此之间也会有所差异。
Flink 提供了 8 个不同的处理函数:
ProcessFunction
最基本的处理函数,基于 DataStream 直接调用.process()时作为参数传入。
KeyedProcessFunction
对流按键分区后的处理函数,基于 KeyedStream 调用.process()时作为参数传入。要想使用定时器,比如基于 KeyedStream。
ProcessWindowFunction
开窗之后的处理函数,也是全窗口函数的代表。基于 WindowedStream 调用.process()时作为参数传入。
ProcessAllWindowFunction
同样是开窗之后的处理函数,基于 AllWindowedStream 调用.process()时作为参数传入。
CoProcessFunction
合并(connect)两条流之后的处理函数,基于 ConnectedStreams 调用.process()时作为参数传入。关于流的连接合并操作,我们会在后续章节详细介绍。
ProcessJoinFunction
间隔连接(interval join)两条流之后的处理函数,基于 IntervalJoined 调用.process()时作为参数传入。
BroadcastProcessFunction
广播连接流处理函数,基于 BroadcastConnectedStream 调用.process()时作为参数传入。这里的“广播连接流”BroadcastConnectedStream,是一个未 keyBy 的普通 DataStream 与一个广播流(BroadcastStream)做连接(conncet)之后的产物。关于广播流的相关操作,我们会在后续章节详细介绍。
KeyedBroadcastProcessFunction
按键分区的广播连接流处理函数,同样是基于 BroadcastConnectedStream 调用.process()时作为参数传入。与 BroadcastProcessFunction 不同的是,这时的广播连接流,是一个 KeyedStream与广播流(BroadcastStream)做连接之后的产物。
# 按键分区处理函数(KeyedProcessFunction)
在 Flink 程序中,为了实现数据的聚合统计,或者开窗计算之类的功能,我们一般都要先用 keyBy 算子对数据流进行“按键分区”,得到一个 KeyedStream。也就是指定一个键(key),按照它的哈希值(hash code)将数据分成不同的“组”,然后分配到不同的并行子任务上执行计算;这相当于做了一个逻辑分流的操作,从而可以充分利用并行计算的优势实时处理海量数据。
另外我们在上节中也提到,只有在 KeyedStream 中才支持使用 TimerService 设置定时器的操作。所以一般情况下,我们都是先做了 keyBy 分区之后,再去定义处理操作;代码中更加常见的处理函数是 KeyedProcessFunction,最基本的 ProcessFunction 反而出镜率没那么高。
接下来我们就先从定时服务(TimerService)入手,详细讲解 KeyedProcessFunction 的用法
# 定时器(Timer)和定时服务(TimerService)
KeyedProcessFunction 的一个特色,就是可以灵活地使用定时器
定时器(timers)是处理函数中进行时间相关操作的主要机制。在.onTimer()方法中可以实现定时处理的逻辑,而它能触发的前提,就是之前曾经注册过定时器、并且现在已经到了触发时间。注册定时器的功能,是通过上下文中提供的“定时服务”(TimerService)来实现的。
定时服务与当前运行的环境有关。前面已经介绍过,ProcessFunction 的上下文(Context)中提供了.timerService()方法,可以直接返回一个 TimerService 对象:
public abstract TimerService timerService();
TimerService 是 Flink 关于时间和定时器的基础服务接口,包含以下六个方法:
// 获取当前的处理时间
long currentProcessingTime();
// 获取当前的水位线(事件时间)
long currentWatermark();
// 注册处理时间定时器,当处理时间超过 time 时触发
void registerProcessingTimeTimer(long time);
// 注册事件时间定时器,当水位线超过 time 时触发
void registerEventTimeTimer(long time);
// 删除触发时间为 time 的处理时间定时器
void deleteProcessingTimeTimer(long time);
// 删除触发时间为 time 的处理时间定时器
void deleteEventTimeTimer(long time);
2
3
4
5
6
7
8
9
10
11
12
六个方法可以分成两大类:基于处理时间和基于事件时间。而对应的操作主要有三个:获取当前时间,注册定时器,以及删除定时器。需要注意,尽管处理函数中都可以直接访问TimerService,不过只有基于 KeyedStream 的处理函数,才能去调用注册和删除定时器的方法;未作按键分区的 DataStream 不支持定时器操作,只能获取当前时间。
对于处理时间和事件时间这两种类型的定时器,TimerService 内部会用一个优先队列将它们的时间戳(timestamp)保存起来,排队等待执行。可以认为,定时器其实是 KeyedStream上处理算子的一个状态,它以时间戳作为区分。所以 TimerService 会以键(key)和时间戳为标准,对定时器进行去重;也就是说对于每个 key 和时间戳,最多只有一个定时器,如果注册了多次,onTimer()方法也将只被调用一次。这样一来,我们在代码中就方便了很多,可以肆无忌惮地对一个 key 注册定时器,而不用担心重复定义——因为一个时间戳上的定时器只会触发一次。
基于 KeyedStream 注册定时器时,会传入一个定时器触发的时间戳,这个时间戳的定时器对于每个 key 都是有效的。这样,我们的代码并不需要做额外的处理,底层就可以直接对不同key 进行独立的处理操作了。
利用这个特性,有时我们可以故意降低时间戳的精度,来减少定时器的数量,从而提高处理性能。比如我们可以在设置定时器时只保留整秒数,那么定时器的触发频率就是最多 1 秒一次。
long coalescedTime = time / 1000 * 1000;
ctx.timerService().registerProcessingTimeTimer(coalescedTime);
2
这里注意定时器的时间戳必须是毫秒数,所以我们得到整秒之后还要乘以 1000。定时器默认的区分精度是毫秒。
另外 Flink 对.onTimer()和.processElement()方法是同步调用的(synchronous),所以也不会出现状态的并发修改。
Flink 的定时器同样具有容错性,它和状态一起都会被保存到一致性检查点(checkpoint)中。当发生故障时,Flink 会重启并读取检查点中的状态,恢复定时器。如果是处理时间的定时器,有可能会出现已经“过期”的情况,这时它们会在重启时被立刻触发。关于 Flink 的检查点和容错机制,我们会在后续章节详细讲解。
# KeyedProcessFunction 的使用
KeyedProcessFunction 可以说是处理函数中的“嫡系部队”,可以认为是 ProcessFunction 的一个扩展。我们只要基于 keyBy 之后的 KeyedStream,直接调用.process()方法,这时需要传入的参数就是 KeyedProcessFunction 的实现类。
stream.keyBy( t -> t.f0 )
.process(new MyKeyedProcessFunction())
2
类似地,KeyedProcessFunction 也是继承自 AbstractRichFunction 的一个抽象类,源码中定义如下:
public abstract class KeyedProcessFunction<K, I, O> extends AbstractRichFunction{
...
public abstract void processElement(I value, Context ctx, Collector<O> out)
throws Exception;
public void onTimer(long timestamp, OnTimerContext ctx, Collector<O> out)
throws Exception {}
public abstract class Context {...}
...
}
2
3
4
5
6
7
8
9
可以看到与 ProcessFunction 的定义几乎完全一样,区别只是在于类型参数多了一个 K,这是当前按键分区的 key 的类型。同样地,我们必须实现个.processElement()抽象方法,用来处理流中的每一个数据;另外还有一个非抽象方法.onTimer(),用来定义定时器触发时的回调操作。由于定时器只能在 KeyedStream 上使用,所以到了 KeyedProcessFunction 这里,我们才真正对时间有了精细的控制,定时方法.onTimer()才真正派上了用场。
public class Demo_03_Source_Customer {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<Event> stream = env.addSource(new ClickSource());
stream.print();
env.execute();
}
public static class ClickSource implements SourceFunction<Event> {
// 声明一个布尔变量,作为控制数据生成的标识位
private Boolean running = true;
@Override
public void run(SourceContext<Event> ctx) throws Exception {
Random random = new Random(); // 在指定的数据集中随机选取数据
String[] users = {"Mary", "Alice", "Bob", "Cary"};
String[] urls = {"./home", "./cart", "./fav", "./prod?id=1", "./prod?id=2"};
while (running) {
Event event = new Event(
users[random.nextInt(users.length)],
urls[random.nextInt(urls.length)],
Calendar.getInstance().getTimeInMillis());
System.out.println("生成数据:" + event);
ctx.collect(event);
// 隔 2 秒生成一个点击事件,方便观测
Thread.sleep(2000);
}
}
@Override
public void cancel() {
running = false;
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
在上面的代码中,由于定时器只能在 KeyedStream 上使用,所以先要进行 keyBy;这里的.keyBy(data -> true)是将所有数据的 key 都指定为了 true,其实就是所有数据拥有相同的 key,会分配到同一个分区。
之后我们自定义了一个 KeyedProcessFunction,其中.processElement()方法是每来一个数据都会调用一次,主要是定义了一个 10 秒之后的定时器;而.onTimer()方法则会在定时器触发时调用。所以我们会看到,程序运行后先在控制台输出“数据到达”的信息,等待 10 秒之后,又会输出“定时器触发”的信息,打印出的时间间隔正是 10 秒。
当然,上面的例子是处理时间的定时器,所以我们是真的需要等待 10 秒才会看到结果。事件时间语义下,又会有什么不同呢?我们可以对上面的代码略作修改,做一个测试:
public class Demo_03_KeyProcessFunction_EventTime {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 从自定义数据源读取数据,并提取时间戳、生成水位线
SingleOutputStreamOperator<Event> stream = env.addSource(new CustomSource())
.assignTimestampsAndWatermarks(WatermarkStrategy.<Event>forMonotonousTimestamps()
.withTimestampAssigner(
new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event element, long recordTimestamp) {
return element.timestamp;
}
}));
// 要用定时器,必须基于 KeyedStream
stream.keyBy(data -> true)
.process(new KeyedProcessFunction<Boolean, Event, String>() {
@Override
public void processElement(Event event, KeyedProcessFunction<Boolean, Event, String>.Context ctx, Collector<String> out) throws Exception {
out.collect("数据到达,时间戳为:" + ctx.timestamp());
out.collect(" 数 据 到 达 , 水 位 线 为 : " + ctx.timerService().currentWatermark() + "\n -------分割线-------");
// 注册一个 10 秒后的定时器
ctx.timerService().registerEventTimeTimer(ctx.timestamp() + 10 * 1000L);
}
@Override
public void onTimer(long timestamp, KeyedProcessFunction<Boolean, Event, String>.OnTimerContext ctx, Collector<String> out) throws Exception {
out.collect("定时器触发,触发时间:" + new Timestamp(timestamp));
}
}).print();
env.execute();
}
// 自定义测试数据源
public static class CustomSource implements SourceFunction<Event> {
@Override
public void run(SourceContext<Event> ctx) throws Exception {
// 直接发出测试数据
ctx.collect(new Event("Mary", "./home", 1000L));
// 为了更加明显,中间停顿 5 秒钟
Thread.sleep(5000L);
// 发出 10 秒后的数据
ctx.collect(new Event("Mary", "./home", 11000L));
Thread.sleep(5000L);
// 发出 10 秒+1ms 后的数据
ctx.collect(new Event("Alice", "./cart", 11001L));
Thread.sleep(5000L);
}
@Override
public void cancel() { }
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
由于是事件时间语义,所以我们必须从数据中提取出数据产生的时间戳。这里为了更清楚地看到程序行为,我们自定义了一个数据源,发出三条测试数据,时间戳分别为 1000、11000和 11001,并且发出数据后都会停顿 5 秒。
在代码中,我们依然将所有数据分到同一分区,然后在自定义的 KeyedProcessFunction 中使用定时器。同样地,每来一条数据,我们就将当前的数据时间戳和水位线信息输出,并注册一个 10 秒后(以当前数据时间戳为基准)的事件时间定时器。执行程序结果如下:
数据到达,时间戳为:1000
数据到达,水位线为:-9223372036854775808
-------分割线-------
数据到达,时间戳为:11000
数据到达,水位线为:999
-------分割线-------
数据到达,时间戳为:11001
数据到达,水位线为:10999
-------分割线-------
定时器触发,触发时间:11000
定时器触发,触发时间:21000
定时器触发,触发时间:21001
2
3
4
5
6
7
8
9
10
11
12
每来一条数据,都会输出两行“数据到达”的信息,并以分割线隔开;两条数据到达的时间间隔为 5 秒。当第三条数据到达后,随后立即输出一条定时器触发的信息;再过 5 秒之后,剩余两条定时器信息输出,程序运行结束。
我们可以发现,数据到来之后,当前的水位线与时间戳并不是一致的。当第一条数据到来,时间戳为 1000,可水位线的生成是周期性的(默认 200ms 一次),不会立即发生改变,所以依然是最小值 Long.MIN_VALUE;随后只要到了水位线生成的时间点(200ms 到了),就会依据当前的最大时间戳 1000 来生成水位线了。这里我们没有设置水位线延迟,默认需要减去 1 毫秒,所以水位线推进到了 999。而当时间戳为 11000 的第二条数据到来之后,水位线同样没有立即改变,仍然是 999,就好像总是“滞后”数据一样。
这样程序的行为就可以得到合理解释了。事件时间语义下,定时器触发的条件就是水位线推进到设定的时间。第一条数据到来后,设定的定时器时间为 1000 + 10 * 1000 = 11000;而当时间戳为 11000 的第二条数据到来,水位线还处在 999 的位置,当然不会立即触发定时器;而之后水位线会推进到 10999,同样是无法触发定时器的。必须等到第三条数据到来,将水位线真正推进到 11000,就可以触发第一个定时器了。第三条数据发出后再过 5 秒,没有更多的数据生成了,整个程序运行结束将要退出,此时 Flink 会自动将水位线推进到长整型的最大值(Long.MAX_VALUE)。于是所有尚未触发的定时器这时就统一触发了,我们就在控制台看到了后两个定时器的触发信息。
# 窗口处理函数
除 了 KeyedProcessFunction , 另 外 一 大 类 常 用 的 处 理 函 数 , 就 是 基 于 窗 口 的ProcessWindowFunction 和 ProcessAllWindowFunction 了。如果看了前面的章节,会发现我们之前已经简单地使用过窗口处理函数了。
# 窗口处理函数的使用
进行窗口计算,我们可以直接调用现成的简单聚合方法(sum/max/min),也可以通过调用.reduce()或.aggregate()来自定义一般的增量聚合函数(ReduceFunction/AggregateFucntion);而对于更加复杂、需要窗口信息和额外状态的一些场景,我们还可以直接使用全窗口函数、把数据全部收集保存在窗口内,等到触发窗口计算时再统一处理。窗口处理函数就是一种典型的全窗口函数。
窗口处理函数 ProcessWindowFunction 的使用与其他窗口函数类似,也是基于WindowedStream 直接调用方法就可以,只不过这时调用的是.process()。
stream.keyBy( t -> t.f0 )
.window( TumblingEventTimeWindows.of(Time.seconds(10)) )
.process(new MyProcessWindowFunction())
2
3
# ProcessWindowFunction 解析
ProcessWindowFunction 既是处理函数又是全窗口函数。从名字上也可以推测出,它的本质似乎更倾向于“窗口函数”一些。事实上它的用法也确实跟其他处理函数有很大不同。我们可以从源码中的定义看到这一点:
public abstract class ProcessWindowFunction<IN, OUT, KEY, W extends Window> extends AbstractRichFunction {
...
public abstract void process(KEY key, Context context, Iterable<IN> elements, Collector<OUT> out) throws Exception;
public void clear(Context context) throws Exception {}
public abstract class Context implements java.io.Serializable {...}
}
2
3
4
5
6
ProcessWindowFunction 依然是一个继承了 AbstractRichFunction 的抽象类,它有四个类型参数:
- IN:input,数据流中窗口任务的输入数据类型。
- OUT:output,窗口任务进行计算之后的输出数据类型。
- KEY:数据中键 key 的类型。
- W:窗口的类型,是 Window 的子类型。一般情况下我们定义时间窗口,W就是 TimeWindow。
而内部定义的方法,跟我们之前熟悉的处理函数就有所区别了。因为全窗口函数不是逐个处理元素的,所以处理数据的方法在这里并不是.processElement(),而是改成了.process()。方法包含四个参数。
- key:窗口做统计计算基于的键,也就是之前 keyBy 用来分区的字段。
- context:当前窗口进行计算的上下文,它的类型就是 ProcessWindowFunction内部定义的抽象类 Context。
- elements:窗口收集到用来计算的所有数据,这是一个可迭代的集合类型。
- out:用来发送数据输出计算结果的收集器,类型为 Collector。
可以明显看出,这里的参数不再是一个输入数据,而是窗口中所有数据的集合。而上下文context 所包含的内容也跟其他处理函数有所差别:
public abstract class Context implements java.io.Serializable {
public abstract W window();
public abstract long currentProcessingTime();
public abstract long currentWatermark();
public abstract KeyedStateStore windowState();
public abstract KeyedStateStore globalState();
public abstract <X> void output(OutputTag<X> outputTag, X value);
}
2
3
4
5
6
7
8
除了可以通过.output()方法定义侧输出流不变外,其他部分都有所变化。这里不再持有TimerService 对象,只能通过 currentProcessingTime()和currentWatermark()来获取当前时间,所以失去了设置定时器的功能;另外由于当前不是只处理一个数据,所以也不再提供.timestamp()方法。与此同时,也增加了一些获取其他信息的方法:比如可以通过.window()直接获取到当前的窗口对象,也可以通过.windowState()和.globalState()获取到当前自定义的窗口状态和全局状态。注意这里的“窗口状态”是自定义的,不包括窗口本身已经有的状态,针对当前 key、当前窗口有效;而“全局状态”同样是自定义的状态,针对当前 key 的所有窗口有效。
所以我们会发现,ProcessWindowFunction 中除了.process()方法外,并没有.onTimer()方法,而是多出了一个.clear()方法。从名字就可以看出,这主要是方便我们进行窗口的清理工作。如果我们自定义了窗口状态,那么必须在.clear()方法中进行显式地清除,避免内存溢出。
这里有一个问题:没有了定时器,那窗口处理函数就失去了一个最给力的武器,如果我们希望有一些定时操作又该怎么做呢?其实仔细思考会发现,对于窗口而言,它本身的定义就包含了一个触发计算的时间点,其实一般情况下是没有必要再去做定时操作的。如果非要这么干,Flink也提供了另外的途径——使用窗口触发器(Trigger)。在触发器中也有一个TriggerContext,它可以起到类似 TimerService 的作用:获取当前时间、注册和删除定时器,另外还可以获取当前的状态。这样设计无疑会让处理流程更加清晰——定时操作也是一种“触发”,所以我们就让所有的触发操作归触发器管,而所有处理数据的操作则归窗口函数管。
至于另一种窗口处理函数 ProcessAllWindowFunction,它的用法非常类似。区别在于它基于的是 AllWindowedStream,相当于对没有 keyBy 的数据流直接开窗并调用.process()方法:
stream.windowAll( TumblingEventTimeWindows.of(Time.seconds(10)) )
.process(new MyProcessAllWindowFunction())
2
# 应用案例——Top N
窗口的计算处理,在实际应用中非常常见。对于一些比较复杂的需求,如果增量聚合函数无法满足,我们就需要考虑使用窗口处理函数这样的“大招”了。
网站中一个非常经典的例子,就是实时统计一段时间内的热门 url。例如,需要统计最近10 秒钟内最热门的两个 url 链接,并且每 5 秒钟更新一次。我们知道,这可以用一个滑动窗口来实现,而“热门度”一般可以直接用访问量来表示。于是就需要开滑动窗口收集 url 的访问数据,按照不同的 url 进行统计,而后汇总排序并最终输出前两名。这其实就是著名的“Top N”问题。
很显然,简单的增量聚合可以得到 url 链接的访问量,但是后续的排序输出 Top N 就很难实现了。所以接下来我们用窗口处理函数进行实现。
# 使用 ProcessAllWindowFunction
一种最简单的想法是,我们干脆不区分 url 链接,而是将所有访问数据都收集起来,统一进行统计计算。所以可以不做 keyBy,直接基于 DataStream 开窗,然后使用全窗口函数ProcessAllWindowFunction 来进行处理。
在窗口中可以用一个 HashMap 来保存每个 url 的访问次数,只要遍历窗口中的所有数据,自然就能得到所有 url 的热门度。最后把 HashMap 转成一个列表 ArrayList,然后进行排序、取出前两名输出就可以了。
public class Demo_04_TopN_ProcessAllWindowFunction {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 从自定义数据源读取数据,并提取时间戳、生成水位线
SingleOutputStreamOperator<Event> stream = env.addSource(new Demo_03_Source_Customer.ClickSource())
.assignTimestampsAndWatermarks(WatermarkStrategy.<Event>forMonotonousTimestamps()
.withTimestampAssigner(
new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event element, long recordTimestamp) {
return element.timestamp;
}
}));
// 转换数据格式
stream
.map(event -> event.url)
.windowAll(SlidingEventTimeWindows.of(Time.seconds(10), Time.seconds(5)))
.process(new ProcessAllWindowFunction<String, List<Tuple2<String,Integer>>, TimeWindow>() {
@Override
public void process(ProcessAllWindowFunction<String, List<Tuple2<String, Integer>>, TimeWindow>.Context context, Iterable<String> iterable, Collector<List<Tuple2<String, Integer>>> out) throws Exception {
Map<String,Integer> res = new LinkedHashMap<>();
for (String url : iterable) {
res.put(url,res.getOrDefault(url,0) + 1);
}
List<Tuple2<String,Integer>> list = new ArrayList();
//排序
for (String url : res.keySet()) {
list.add(Tuple2.of(url,res.get(url)));
}
list.sort((e1,e2) -> e2.f1 - e1.f1);
out.collect(Arrays.asList(list.get(0),list.get(1)));
}
}).print();
env.execute();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
# 使用 KeyedProcessFunction
在上一小节的实现过程中,我们没有进行按键分区,直接将所有数据放在一个分区上进行了开窗操作。这相当于将并行度强行设置为 1,在实际应用中是要尽量避免的,所以 Flink 官方也并不推荐使用 AllWindowedStream 进行处理。另外,我们在全窗口函数中定义了 HashMap来统计 url 链接的浏览量,计算过程是要先收集齐所有数据、然后再逐一遍历更新 HashMap,这显然不够高效。如果我们可以利用增量聚合函数的特性,每来一条数据就更新一次对应 url的浏览量,那么到窗口触发计算时只需要做排序输出就可以了
基于这样的想法,我们可以从两个方面去做优化:一是对数据进行按键分区,分别统计浏览量;二是进行增量聚合,得到结果最后再做排序输出。所以,我们可以使用增量聚合函数AggregateFunction进行浏览量的统计,然后结合ProcessWindowFunction排序输出来实现Top N的需求。
具体实现思路就是,先按照 url 对数据进行 keyBy 分区,然后开窗进行增量聚合。这里就会发现一个问题:我们进行按键分区之后,窗口的计算就会只针对当前 key 有效了;也就是说,每个窗口的统计结果中,只会有一个 url 的浏览量,这是无法直接用 ProcessWindowFunction进行排序的。所以我们只能分成两步:先对每个 url 链接统计出浏览量,然后再将统计结果收集起来,排序输出最终结果。因为最后的排序还是基于每个时间窗口的,所以为了让输出的统计结果中包含窗口信息,我们可以借用第六章中定义的 POJO 类 UrlViewCount 来表示,它包含了 url、浏览量(count)以及窗口的起始结束时间。之后对 UrlViewCount 的处理,可以先按窗口分区,然后用 KeyedProcessFunction 来实现。
总结处理流程如下:
- 读取数据源;
- 筛选浏览行为(pv);
- 提取时间戳并生成水位线;
- 按照 url 进行 keyBy 分区操作;
- 开长度为 1 小时、步长为 5 分钟的事件时间滑动窗口;
- 使用增量聚合函数 AggregateFunction,并结合全窗口函数 WindowFunction 进行窗口聚合,得到每个 url、在每个统计窗口内的浏览量,包装成 UrlViewCount;
- 按照窗口进行 keyBy 分区操作;
- 对同一窗口的统计结果数据,使用 KeyedProcessFunction 进行收集并排序输出。
没有这么简单。因为数据流中的元素是逐个到来的,所以即使理论上我们应该“同时”收到很多 url 的浏览量统计结果,实际也是有先后的、只能一条一条处理。下游任务(就是我们定义的 KeyedProcessFunction)看到一个 url 的统计结果,并不能保证这个时间段的统计数据不会再来了,所以也不能贸然进行排序输出。解决的办法,自然就是要等所有数据到齐了——这很容易让我们联想起水位线设置延迟时间的方法。这里我们也可以“多等一会儿”,等到水位线真正超过了窗口结束时间,要统计的数据就肯定到齐了。
具体实现上,可以采用一个延迟触发的事件时间定时器。基于窗口的结束时间来设定延迟,其实并不需要等太久——因为我们是靠水位线的推进来触发定时器,而水位线的含义就是“之前的数据都到齐了”。所以我们只需要设置 1 毫秒的延迟,就一定可以保证这一点。
而在等待过程中,之前已经到达的数据应该缓存起来,我们这里用一个自定义的“列表状态”(ListState)来进行存储,如图 7-2 所示。这个状态需要使用富函数类的 getRuntimeContext()方法获取运行时上下文来定义,我们一般把它放在 open()生命周期方法中。之后每来一个UrlViewCount,就把它添加到当前的列表状态中,并注册一个触发时间为窗口结束时间加 1毫秒(windowEnd + 1)的定时器。待到水位线到达这个时间,定时器触发,我们可以保证当前窗口所有 url 的统计结果 UrlViewCount 都到齐了;于是从状态中取出进行排序输出。
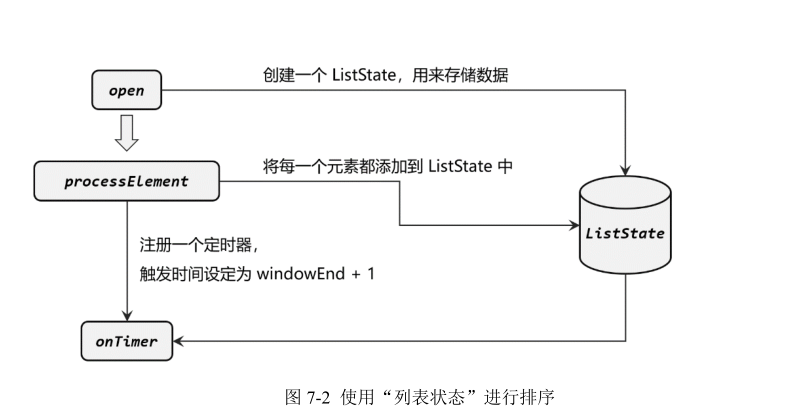
public class Demo_05_TopN_KeyProcessFunction {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 从自定义数据源读取数据,并提取时间戳、生成水位线
SingleOutputStreamOperator<Event> stream = env.addSource(new Demo_03_Source_Customer.ClickSource())
.assignTimestampsAndWatermarks(WatermarkStrategy.<Event>forMonotonousTimestamps()
.withTimestampAssigner(
new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event element, long recordTimestamp) {
return element.timestamp;
}
}));
// 转换数据格式
stream
.map(event -> event.url)
.keyBy(url -> url)
.window(SlidingEventTimeWindows.of(Time.seconds(10), Time.seconds(5)))
.aggregate(
new AggregateFunction<String, Long, Long>() {
@Override
public Long createAccumulator() {
return 0L;
}
@Override
public Long add(String s, Long aLong) {
return aLong + 1L;
}
@Override
public Long getResult(Long aLong) {
return aLong;
}
@Override
public Long merge(Long aLong, Long acc1) {
return null;
}
},
new ProcessWindowFunction<Long,UrlViewCount,String, TimeWindow>() {
@Override
public void process(String key, ProcessWindowFunction<Long, UrlViewCount, String, TimeWindow>.Context context, Iterable<Long> iterable, Collector<UrlViewCount> collector) throws Exception {
UrlViewCount urlViewCount = new UrlViewCount();
urlViewCount.url = key;
urlViewCount.count = iterable.iterator().next();
urlViewCount.windowStart = context.window().getStart();
urlViewCount.windowEnd = context.window().getEnd();
collector.collect(urlViewCount);
}
})
.keyBy(data -> data.windowEnd)
.process(
new KeyedProcessFunction<Long, UrlViewCount, String>() {
// 定义一个列表状态
private ListState<UrlViewCount> urlViewCountListState;
@Override
public void open(Configuration parameters) throws Exception {
// 从环境中获取列表状态句柄
urlViewCountListState = getRuntimeContext().getListState(
new ListStateDescriptor<UrlViewCount>("url-view-count-list", Types.POJO(UrlViewCount.class)));
}
@Override
public void processElement(UrlViewCount urlViewCount, KeyedProcessFunction<Long, UrlViewCount, String>.Context ctx, Collector<String> collector) throws Exception {
// 将 count 数据添加到列表状态中,保存起来
urlViewCountListState.add(urlViewCount);
// 注册 window end + 1ms 后的定时器,等待所有数据到齐开始排序
ctx.timerService().registerEventTimeTimer(ctx.getCurrentKey() + 1);
}
@Override
public void onTimer(long timestamp, OnTimerContext ctx, Collector<String>
out) throws Exception {
// 将数据从列表状态变量中取出,放入 ArrayList,方便排序
ArrayList<UrlViewCount> urlViewCountArrayList = new ArrayList<>();
for (UrlViewCount urlViewCount : urlViewCountListState.get()) {
urlViewCountArrayList.add(urlViewCount);
}
// 清空状态,释放资源
urlViewCountListState.clear();
// 排序
urlViewCountArrayList.sort(new Comparator<UrlViewCount>() {
@Override
public int compare(UrlViewCount o1, UrlViewCount o2) {
return o2.count.intValue() - o1.count.intValue();
}
});
// 取前两名,构建输出结果
StringBuilder result = new StringBuilder();
result.append("========================================\n");
result.append("窗口结束时间:" + new Timestamp(timestamp - 1) + "\n");
int len = urlViewCountArrayList.size() > 2 ? 2 : urlViewCountArrayList.size();
for (int i = 0; i < len; i++) {
UrlViewCount UrlViewCount = urlViewCountArrayList.get(i);
String info = "No." + (i + 1) + " "
+ "url:" + UrlViewCount.url + " "
+ "浏览量:" + UrlViewCount.count + "\n";
result.append(info);
}
result.append("========================================\n");
out.collect(result.toString());
}
}).print("result:")
;
// .windowAll(SlidingEventTimeWindows.of(Time.seconds(10), Time.seconds(5)))
// .process(new ProcessAllWindowFunction<String, List<Tuple2<String,Integer>>, TimeWindow>() {
//
// @Override
// public void process(ProcessAllWindowFunction<String, List<Tuple2<String, Integer>>, TimeWindow>.Context context, Iterable<String> iterable, Collector<List<Tuple2<String, Integer>>> out) throws Exception {
// Map<String,Integer> res = new LinkedHashMap<>();
// for (String url : iterable) {
// res.put(url,res.getOrDefault(url,0) + 1);
// }
// List<Tuple2<String,Integer>> list = new ArrayList();
// //排序
// for (String url : res.keySet()) {
// list.add(Tuple2.of(url,res.get(url)));
// }
// list.sort((e1,e2) -> e2.f1 - e1.f1);
// out.collect(Arrays.asList(list.get(0),list.get(1)));
// }
// }).print();
env.execute();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
代码中,我们还利用了定时器的特性:针对同一 key、同一时间戳会进行去重。所以对于同一个窗口而言,我们接到统计结果数据后设定的 windowEnd + 1 的定时器都是一样的,最终只会触发一次计算。而对于不同的 key(这里 key 是 windowEnd),定时器和状态都是独立的,所以我们也不用担心不同窗口间数据的干扰。
我们在上面的代码中使用了后面要讲解的 ListState。这里可以先简单说明一下。我们先声明一个列表状态变量:
private ListState<Event> UrlViewCountListState;
然后在 open 方法中初始化了列表状态变量,我们初始化的时候使用了 ListStateDescriptor描述符,这个描述符用来告诉 Flink 列表状态变量的名字和类型。列表状态变量是单例,也就是说只会被实例化一次。这个列表状态变量的作用域是当前 key 所对应的逻辑分区。我们使用add 方法向列表状态变量中添加数据,使用 get 方法读取列表状态变量中的所有元素。
另外,根据水位线的定义,我们这里的延迟时间设为 0 事实上也是可以保证数据都到齐的。感兴趣的读者可以自行修改代码进行测试。
# 侧输出流(Side Output)
处理函数还有另外一个特有功能,就是将自定义的数据放入“侧输出流”(side output)输出。这个概念我们并不陌生,之前在讲到窗口处理迟到数据时,最后一招就是输出到侧输出流。而这种处理方式的本质,其实就是处理函数的侧输出流功能。
我们之前讲到的绝大多数转换算子,输出的都是单一流,流里的数据类型只能有一种。而侧输出流可以认为是“主流”上分叉出的“支流”,所以可以由一条流产生出多条流,而且这些流中的数据类型还可以不一样。利用这个功能可以很容易地实现“分流”操作。
具体应用时,只要在处理函数的.processElement()或者.onTimer()方法中,调用上下文的.output()方法就可以了。
DataStream<Integer> stream = env.addSource(...);
SingleOutputStreamOperator<Long> longStream = stream.process(new ProcessFunction<Integer, Long>() {
@Override
public void processElement( Integer value, Context ctx, Collector<Integer> out) throws Exception {
// 转换成 Long,输出到主流中
out.collect(Long.valueOf(value));
// 转换成 String,输出到侧输出流中
ctx.output(outputTag, "side-output: " + String.valueOf(value));
}
});
2
3
4
5
6
7
8
9
10
这里 output()方法需要传入两个参数,第一个是一个“输出标签”OutputTag,用来标识侧输出流,一般会在外部统一声明;第二个就是要输出的数据。
我们可以在外部先将 OutputTag 声明出来:
OutputTag<String> outputTag = new OutputTag<String>("side-output") {};
如果想要获取这个侧输出流,可以基于处理之后的 DataStream 直接调用.getSideOutput()方法,传入对应的 OutputTag,这个方式与窗口 API 中获取侧输出流是完全一样的。
DataStream<String> stringStream = longStream.getSideOutput(outputTag);
# 本章总结
Flink 拥有非常丰富的多层 API,而底层的处理函数可以说是最为强大、最为灵活的一种。广义上来讲,处理函数也可以认为是 DataStream API 中的一部分,它的调用方式与其他转换算子完全一致。处理函数可以访问时间、状态,定义定时操作,它可以直接触及流处理最为本质的组成部分。所以处理函数不仅是我们处理复杂需求时兜底的“大招”,更是理解流处理本质的重要一环。
在本章中,我们详细介绍了处理函数的功能和底层的结构,重点讲解了最为常用的KeyedProcessFunction 和 ProcessWindowFunction,并实现了电商应用中Top N 的经典案例,另外还介绍了侧输出流的用法。而关于合并两条流之后的处理函数,以及广播连接流(BroadcastConnectedStream)的处理操作,调用方法和原理都非常类似,我们会在后续章节继续展开。
# 多流转换
无论是基本的简单转换和聚合,还是基于窗口的计算,我们都是针对一条流上的数据进行处理的。而在实际应用中,可能需要将不同来源的数据连接合并在一起处理,也有可能需要将一条流拆分开,所以经常会有对多条流进行处理的场景。本章我们就来讨论 Flink 中对多条流进行转换的操作
简单划分的话,多流转换可以分为“分流”和“合流”两大类。目前分流的操作一般是通过侧输出流(side output)来实现,而合流的算子比较丰富,根据不同的需求可以调用 union、connect、join 以及 coGroup 等接口进行连接合并操作。下面我们就进行具体的讲解。
# 分流
所谓“分流”,就是将一条数据流拆分成完全独立的两条、甚至多条流。也就是基于一个DataStream,得到完全平等的多个子 DataStream,如图 8-1 所示。一般来说,我们会定义一些筛选条件,将符合条件的数据拣选出来放到对应的流里。
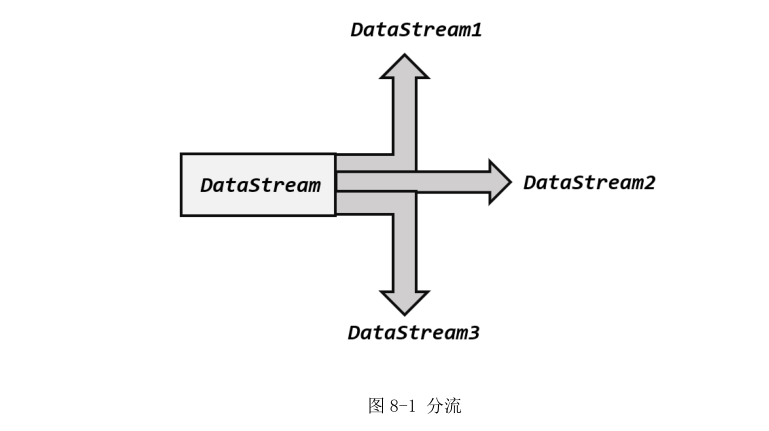
# 简单实现
其实根据条件筛选数据的需求,本身非常容易实现:只要针对同一条流多次独立调用.filter()方法进行筛选,就可以得到拆分之后的流了。
在 Flink 1.13 版本中,已经弃用了.split()方法,取而代之的是直接用处理函数(processfunction)的侧输出流(side output)。
我们知道,处理函数本身可以认为是一个转换算子,它的输出类型是单一的,处理之后得到的仍然是一个 DataStream;而侧输出流则不受限制,可以任意自定义输出数据,它们就像从“主流”上分叉出的“支流”。尽管看起来主流和支流有所区别,不过实际上它们都是某种类型的 DataStream,所以本质上还是平等的。利用侧输出流就可以很方便地实现分流操作,而且得到的多条 DataStream 类型可以不同,这就给我们的应用带来了极大的便利。
关于处理函数中侧输出流的用法,我们已经在 7.5 节做了详细介绍。简单来说,只需要调用上下文 ctx 的.output()方法,就可以输出任意类型的数据了。而侧输出流的标记和提取,都离不开一个“输出标签”(OutputTag),它就相当于 split()分流时的“戳”,指定了侧输出流的id 和类型。
public class Demo_01_SplitStream {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 从自定义数据源读取数据,并提取时间戳、生成水位线
SingleOutputStreamOperator<Event> stream = env.addSource(new Demo_03_Source_Customer.ClickSource());
OutputTag<String> mary = new OutputTag<String>("mary"){};
OutputTag<String> bolb = new OutputTag<String>("bob"){};
SingleOutputStreamOperator<String> processStream = stream.process(new ProcessFunction<Event, String>() {
@Override
public void processElement(Event event, ProcessFunction<Event, String>.Context context, Collector<String> collector) throws Exception {
String user = event.user;
if (user.equals("Mary")) {
context.output(mary, event.toString());
} else if (user.equals("Bob")) {
context.output(bolb, event.toString());
} else {
collector.collect(event.toString());
}
}
});
processStream.getSideOutput(mary).print("mary");
processStream.getSideOutput(bolb).print("bolb");
processStream.print("other");
env.execute();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
这里我们定义了两个侧输出流,分别拣选 Mary 的浏览事件和 Bob 的浏览事件;由于类型已经确定,我们可以只保留(用户 id, url, 时间戳)这样一个三元组。而剩余的事件则直接输出到主流,类型依然保留 Event,就相当于之前的 elseStream。这样的实现方式显然更简洁,也更加灵活。
# 基本合流操作
既然一条流可以分开,自然多条流就可以合并。在实际应用中,我们经常会遇到来源不同的多条流,需要将它们的数据进行联合处理。所以 Flink 中合流的操作会更加普遍,对应的API 也更加丰富。
# 联合(Union)
最简单的合流操作,就是直接将多条流合在一起,叫作流的“联合”(union),如图 8-2所示。联合操作要求必须流中的数据类型必须相同,合并之后的新流会包括所有流中的元素,数据类型不变。这种合流方式非常简单粗暴,就像公路上多个车道汇在一起一样。
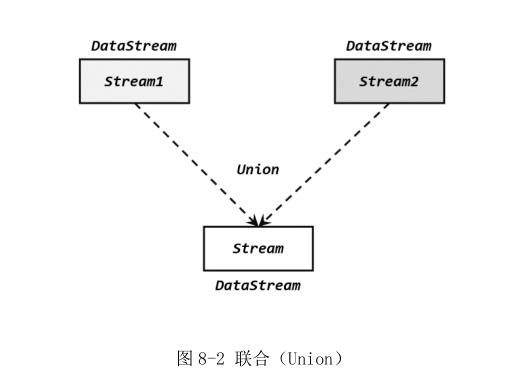
在代码中,我们只要基于 DataStream 直接调用.union()方法,传入其他 DataStream 作为参数,就可以实现流的联合了;得到的依然是一个 DataStream:
stream1.union(stream2, stream3, ...)
注意:union()的参数可以是多个 DataStream,所以联合操作可以实现多条流的合并。
这里需要考虑一个问题。在事件时间语义下,水位线是时间的进度标志;不同的流中可能水位线的进展快慢完全不同,如果它们合并在一起,水位线又该以哪个为准呢?
还以要考虑水位线的本质含义,是“之前的所有数据已经到齐了”;所以对于合流之后的水位线,也是要以最小的那个为准,这样才可以保证所有流都不会再传来之前的数据。换句话说,多流合并时处理的时效性是以最慢的那个流为准的。我们自然可以想到,这与之前介绍的并行任务水位线传递的规则是完全一致的;多条流的合并,某种意义上也可以看作是多个并行任务向同一个下游任务汇合的过程。
public class Demo_02_Union {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
SingleOutputStreamOperator<Event> stream1 = env.socketTextStream("ha01", 7777)
.map(data -> {
String[] field = data.split(",");
return new Event(field[0].trim(), field[1].trim(), Long.valueOf(field[2].trim()));
})
.assignTimestampsAndWatermarks(WatermarkStrategy.<Event>forBoundedOutOfOrderness(Duration.ofSeconds(2))
.withTimestampAssigner(
new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event element, long recordTimestamp) {
return element.timestamp;
}
})
);
stream1.print("stream1");
SingleOutputStreamOperator<Event> stream2 =
env.socketTextStream("ha02", 7777)
.map(data -> {
String[] field = data.split(",");
return new Event(field[0].trim(), field[1].trim(), Long.valueOf(field[2].trim()));
})
.assignTimestampsAndWatermarks(WatermarkStrategy.<Event>forBoundedOutOfOrderness(Duration.ofSeconds(5))
.withTimestampAssigner(
new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event element, long
recordTimestamp) {
return element.timestamp;
}
})
);
stream2.print("stream2");
// 合并两条流
stream1.union(stream2)
.process(new ProcessFunction<Event, String>() {
@Override
public void processElement(Event value, Context ctx, Collector<String> out) throws Exception {
out.collect(" 水 位 线 : " + ctx.timerService().currentWatermark());
}
})
.print();
env.execute();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
这里为了更清晰地看到水位线的进展,我们创建了两条流来读取 socket 文本数据,并从数据中提取时间戳作为生成水位线的依据。用 union 将两条流合并后,用一个 ProcessFunction来进行处理,获取当前的水位线进行输出。我们会发现两条流中每输入一个数据,合并之后的流中都会有数据出现;而水位线只有在两条流中水位线最小值增大的时候,才会真正向前推进。
我们可以来分析一下程序的运行:
在合流之后的 ProcessFunction 对应的算子任务中,逻辑时钟的初始状态如图 8-3 所示。

由于 Flink 会在流的开始处,插入一个负无穷大(Long.MIN_VALUE)的水位线,所以合流后的 ProcessFunction 对应的处理任务,会为合并的每条流保存一个“分区水位线”,初始值都是 Long.MIN_VALUE;而此时算子任务的水位线是所有分区水位线的最小值,因此也是Long.MIN_VALUE。
我们在第一条 socket 文本流输入数据[Alice, ./home, 1000] 时,水位线不会立即改变,只有到水位线生成周期的时间点(200ms 一次)才会推进到 1000 - 1 = 999 毫秒;这与我们在 7.3.2小节中对事件时间定时器的测试是一致的。不过即使第一条水位线推进到了 999,由于另一条流没有变化,所以合流之后的 Process 任务水位线仍然是初始值。如图 8-4 所示。
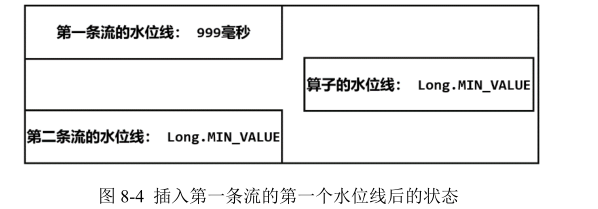
如果这时我们在第二条 socket 文本流输入数据[Alice, ./home, 2000],那么第二条流的水位线会随之推进到 2000 – 1 = 1999 毫秒,Process 任务所保存的第二条流分区水位线更新为 1999;这样两个分区水位线取最小值,Process 任务的水位线也就可以推进到 999 了。如图 8-5 所示。
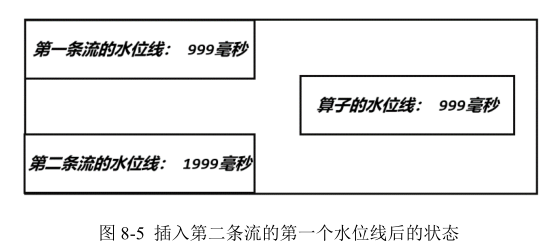
进而如果我们继续在第一条流中输入数据[Alice, ./home, 3000],Process 任务的第一条流分区水位线就会更新为 2999,同时将算子任务的时钟推进到 1999。状态如图 8-6 所示,和你推测的一样吗?
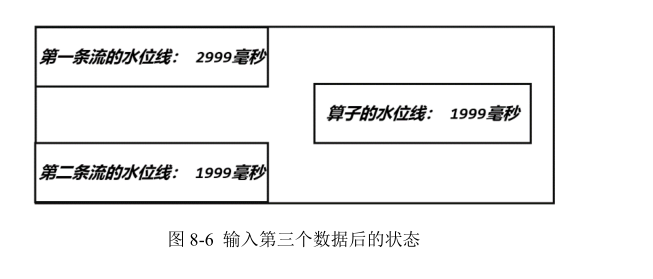
# 连接(Connect)
流的联合虽然简单,不过受限于数据类型不能改变,灵活性大打折扣,所以实际应用较少出现。除了联合(union),Flink 还提供了另外一种方便的合流操作——连接(connect)。顾名思义,这种操作就是直接把两条流像接线一样对接起来。
# 连接流(ConnectedStreams)
为了处理更加灵活,连接操作允许流的数据类型不同。但我们知道一个 DataStream 中的数据只能有唯一的类型,所以连接得到的并不是 DataStream,而是一个“连接流”(ConnectedStreams)。连接流可以看成是两条流形式上的“统一”,被放在了一个同一个流中;事实上内部仍保持各自的数据形式不变,彼此之间是相互独立的。要想得到新的 DataStream,还需要进一步定义一个“同处理”(co-process)转换操作,用来说明对于不同来源、不同类型的数据,怎样分别进行处理转换、得到统一的输出类型。所以整体上来,两条流的连接就像是“一国两制”,两条流可以保持各自的数据类型、处理方式也可以不同,不过最终还是会统一到 同一个 DataStream 中,如图 8-7 所示。

在代码实现上,需要分为两步:首先基于一条 DataStream 调用.connect()方法,传入另外一条 DataStream 作为参数,将两条流连接起来,得到一个 ConnectedStreams;然后再调用同处理方法得到 DataStream。这里可以的调用的同处理方法有.map()/.flatMap(),以及.process()方法。
public class Demo_03_CoMap {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DataStreamSource<Integer> intStream = env.fromElements(1, 2, 3);
DataStreamSource<Long> longStream = env.fromElements(1L, 2L, 3L);
ConnectedStreams<Integer, Long> connectedStreams = intStream.connect(longStream);
connectedStreams.map(new CoMapFunction<Integer, Long, String>() {
@Override
public String map1(Integer integer) throws Exception {
return integer + " : " + "Integer";
}
@Override
public String map2(Long aLong) throws Exception {
return aLong + " : " + "Long";
}
}).print();
env.execute();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
上面的代码中,ConnectedStreams 有两个类型参数,分别表示内部包含的两条流各自的数据类型;由于需要“一国两制”,因此调用.map()方法时传入的不再是一个简单的 MapFunction,而是一个 CoMapFunction,表示分别对两条流中的数据执行 map 操作。这个接口有三个类型参数,依次表示第一条流、第二条流,以及合并后的流中的数据类型。需要实现的方法也非常直白:.map1()就是对第一条流中数据的 map 操作,.map2()则是针对第二条流。这里我们将一条 Integer 流和一条 Long 流合并,转换成 String 输出。所以当遇到第一条流输入的整型值时,调用.map1();而遇到第二条流输入的长整型数据时,调用.map2():最终都转换为字符串输出,合并成了一条字符串流。
值得一提的是,ConnectedStreams 也可以直接调用.keyBy()进行按键分区的操作,得到的还是一个 ConnectedStreams:
connectedStreams.keyBy(keySelector1, keySelector2);
这里传入两个参数 keySelector1 和 keySelector2,是两条流中各自的键选择器;当然也可以直接传入键的位置值(keyPosition),或者键的字段名(field),这与普通的 keyBy 用法完全一致。ConnectedStreams 进行 keyBy 操作,其实就是把两条流中 key 相同的数据放到了一起,然后针对来源的流再做各自处理,这在一些场景下非常有用。另外,我们也可以在合并之前就将两条流分别进行 keyBy,得到的 KeyedStream 再进行连接(connect)操作,效果是一样的。要注意两条流定义的键的类型必须相同,否则会抛出异常。
两条流的连接(connect),与联合(union)操作相比,最大的优势就是可以处理不同类型的流的合并,使用更灵活、应用更广泛。当然它也有限制,就是合并流的数量只能是 2,而 union可以同时进行多条流的合并。这也非常容易理解:union 限制了类型不变,所以直接合并没有问题;而 connect 是“一国两制”,后续处理的接口只定义了两个转换方法,如果扩展需要重新定义接口,所以不能“一国多制”。
# CoProcessFunction
对于连接流 ConnectedStreams 的处理操作,需要分别定义对两条流的处理转换,因此接口中就会有两个相同的方法需要实现,用数字“1”“2”区分,在两条流中的数据到来时分别调用。我们把这种接口叫作“协同处理函数”(co-process function)。与 CoMapFunction 类似,如果是调用.flatMap()就需要传入一个 CoFlatMapFunction,需要实现 flatMap1()、flatMap2()两个方法;而调用.process()时,传入的则是一个 CoProcessFunction。
抽象类 CoProcessFunction 在源码中定义如下:
public abstract class CoProcessFunction<IN1, IN2, OUT> extends AbstractRichFunction {
...
public abstract void processElement1(IN1 value, Context ctx, Collector<OUT> out) throws Exception;
public abstract void processElement2(IN2 value, Context ctx, Collector<OUT> out) throws Exception;
public void onTimer(long timestamp, OnTimerContext ctx, Collector<OUT> out) throws Exception {}
public abstract class Context {...}
...
}
2
3
4
5
6
7
8
我们可以看到,很明显 CoProcessFunction 也是“处理函数”家族中的一员,用法非常相似。它需要实现的就是 processElement1()、processElement2()两个方法,在每个数据到来时,会根据来源的流调用其中的一个方法进行处理。CoProcessFunction 同样可以通过上下文 ctx 来访问 timestamp、水位线,并通过 TimerService 注册定时器;另外也提供了.onTimer()方法,用于定义定时触发的处理操作。
下面是 CoProcessFunction 的一个具体示例:我们可以实现一个实时对账的需求,也就是app 的支付操作和第三方的支付操作的一个双流 Join。App 的支付事件和第三方的支付事件将会互相等待 5 秒钟,如果等不来对应的支付事件,那么就输出报警信息。程序如下:
public class Demo_04_BillCheckExample {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
SingleOutputStreamOperator<Tuple3<String, String, Long>> appStream = env.fromElements(
Tuple3.of("order-1", "app", 1000L),
Tuple3.of("order-2", "app", 2000L)
).assignTimestampsAndWatermarks(
WatermarkStrategy.<Tuple3<String, String, Long>>forMonotonousTimestamps()
.withTimestampAssigner(new SerializableTimestampAssigner<Tuple3<String, String, Long>>() {
@Override
public long extractTimestamp(Tuple3<String, String, Long> element, long l) {
return element.f2;
}
})
);
SingleOutputStreamOperator<Tuple4<String, String, String, Long>> thirdpartStream = env.fromElements(
Tuple4.of("order-1", "third-party", "success", 3000L),
Tuple4.of("order-3", "third-party", "success", 4000L)
).assignTimestampsAndWatermarks(
WatermarkStrategy.<Tuple4<String, String, String, Long>>forMonotonousTimestamps()
.withTimestampAssigner(new SerializableTimestampAssigner<Tuple4<String, String, String, Long>>() {
@Override
public long extractTimestamp(Tuple4<String, String, String, Long> element, long l) {
return element.f3;
}
})
);
// 检测同一支付单在两条流中是否匹配,不匹配就报警
appStream.connect(thirdpartStream)
.keyBy(e1 -> e1.f0, e2 -> e2.f0)
.process(new CoProcessFunction<Tuple3<String, String, Long>, Tuple4<String, String, String, Long>, String>() {
private ValueState<Tuple3<String, String, Long>> appState;
private ValueState<Tuple4<String, String, String, Long>> thirdPartState;
@Override
public void open(Configuration parameters) throws Exception {
appState = getRuntimeContext().getState(new ValueStateDescriptor<Tuple3<String, String, Long>>("app-event", Types.TUPLE(Types.STRING, Types.STRING,Types.LONG)));
thirdPartState = getRuntimeContext().getState(new ValueStateDescriptor<Tuple4<String, String,String, Long>>("thirdParty-event", Types.TUPLE(Types.STRING, Types.STRING,Types.STRING,Types.LONG)));
}
@Override
public void processElement1(Tuple3<String, String, Long> value, CoProcessFunction<Tuple3<String, String, Long>, Tuple4<String, String, String, Long>, String>.Context context, Collector<String> out) throws Exception {
if(thirdPartState.value() == null) { // 第三方支付信息未到
// 更新状态
appState.update(value);
// 设置定时器
context.timerService().registerEventTimeTimer(value.f2 + 5000L);
}else{// 第三方支付信息已到
out.collect(" 对 账 成 功 : " + value + " " + thirdPartState.value());
// 清空状态
thirdPartState.clear();
}
}
@Override
public void processElement2(Tuple4<String, String, String, Long> value, CoProcessFunction<Tuple3<String, String, Long>, Tuple4<String, String, String, Long>, String>.Context context, Collector<String> out) throws Exception {
if(appState.value() == null) { // 第三方支付信息未到
// 更新状态
thirdPartState.update(value);
// 设置定时器
context.timerService().registerEventTimeTimer(value.f3 + 5000L);
}else{// 第三方支付信息已到
out.collect(" 对 账 成 功 : " + value + " " + appState.value());
// 清空状态
appState.clear();
}
}
@Override
public void onTimer(long timestamp, CoProcessFunction<Tuple3<String, String, Long>, Tuple4<String, String, String, Long>, String>.OnTimerContext ctx, Collector<String> out) throws Exception {
// 定时器触发,判断状态,如果某个状态不为空,说明另一条流中事件没来
if (appState.value() != null) {
out.collect("对账失败:" + appState.value() + " " + "第三方支付 平台信息未到");
}
if (thirdPartState.value() != null) {
out.collect("对账失败:" + thirdPartState.value() + " " + "app 信息未到");
}
appState.clear();
thirdPartState.clear();
}
}).print();
env.execute();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94

在程序中,我们声明了两个状态变量分别用来保存 App 的支付信息和第三方的支付信息。App 的支付信息到达以后,会检查对应的第三方支付信息是否已经先到达(先到达会保存在对应的状态变量中),如果已经到达了,那么对账成功,直接输出对账成功的信息,并将保存第三方支付消息的状态变量清空。如果 App 对应的第三方支付信息没有到来,那么我们会注册一个 5 秒钟之后的定时器,也就是说等待第三方支付事件 5 秒钟。当定时器触发时,检查保存app 支付信息的状态变量是否还在,如果还在,说明对应的第三方支付信息没有到来,所以输出报警信息。
# 广播连接流(BroadcastConnectedStream)
关于两条流的连接,还有一种比较特殊的用法:DataStream 调用.connect()方法时,传入的参数也可以不是一个 DataStream,而是一个“广播流”(BroadcastStream),这时合并两条流得到的就变成了一个“广播连接流”(BroadcastConnectedStream)
这种连接方式往往用在需要动态定义某些规则或配置的场景。因为规则是实时变动的,所以我们可以用一个单独的流来获取规则数据;而这些规则或配置是对整个应用全局有效的,所以不能只把这数据传递给一个下游并行子任务处理,而是要“广播”(broadcast)给所有的并行子任务。而下游子任务收到广播出来的规则,会把它保存成一个状态,这就是所谓的“广播状态”(broadcast state)。
广播状态底层是用一个“映射”(map)结构来保存的。在代码实现上,可以直接调用DataStream 的.broadcast()方法,传入一个“映射状态描述器”(MapStateDescriptor)说明状态的名称和类型,就可以得到规则数据的“广播流”(BroadcastStream):
MapStateDescriptor<String, Rule> ruleStateDescriptor = new
MapStateDescriptor<>(...);
BroadcastStream<Rule> ruleBroadcastStream = ruleStream.broadcast(ruleStateDescriptor);
2
3
接下来我们就可以将要处理的数据流,与这条广播流进行连接(connect),得到的就是所谓的“广播连接流” (BroadcastConnectedStream)。基于 BroadcastConnectedStream 调用.process()方法,就可以同时获取规则和数据,进行动态处理了。
这里既然调用了.process()方法,当然传入的参数也应该是处理函数大家族中一员——如果对数据流调用过 keyBy 进行了按键分区,那么要传入的就是 KeyedBroadcastProcessFunction;如果没有按键分区,就传入 BroadcastProcessFunction。
DataStream<String> output = stream
.connect(ruleBroadcastStream)
.process( new BroadcastProcessFunction<>() {...} );
2
3
BroadcastProcessFunction 与 CoProcessFunction 类似,同样是一个抽象类,需要实现两个方法,针对合并的两条流中元素分别定义处理操作。区别在于这里一条流是正常处理数据,而另一条流则是要用新规则来更新广播状态,所以对应的两个方法叫作.processElement()和.processBroadcastElement()。源码中定义如下:
public abstract class BroadcastProcessFunction<IN1, IN2, OUT> extends BaseBroadcastProcessFunction {
...
public abstract void processElement(IN1 value, ReadOnlyContext ctx,
Collector<OUT> out) throws Exception;
public abstract void processBroadcastElement(IN2 value, Context ctx,
Collector<OUT> out) throws Exception;
...
}
2
3
4
5
6
7
8
关于广播状态和广播连接流的用法和示例,我们会在第九章讲解 Flink 中的状态之后详细介绍。
# 基于时间的合流——双流联结(Join)
对于两条流的合并,很多情况我们并不是简单地将所有数据放在一起,而是希望根据某个字段的值将它们联结起来,“配对”去做处理。例如用传感器监控火情时,我们需要将大量温度传感器和烟雾传感器采集到的信息,按照传感器 ID 分组、再将两条流中数据合并起来,如果同时超过设定阈值就要报警。
我们发现,这种需求与关系型数据库中表的 join 操作非常相近。事实上,Flink 中两条流的 connect 操作,就可以通过 keyBy 指定键进行分组后合并,实现了类似于 SQL 中的 join 操作;另外 connect 支持处理函数,可以使用自定义状态和 TimerService 灵活实现各种需求,其实已经能够处理双流合并的大多数场景。
不过处理函数是底层接口,所以尽管 connect 能做的事情多,但在一些具体应用场景下还是显得太过抽象了。比如,如果我们希望统计固定时间内两条流数据的匹配情况,那就需要设置定时器、自定义触发逻辑来实现——其实这完全可以用窗口(window)来表示。为了更方便地实现基于时间的合流操作,Flink 的 DataStrema API 提供了两种内置的 join 算子,以及coGroup 算子。本节我们就来做一个详细的讲解。
注:SQL 中 join 一般会翻译为“连接”;我们这里为了区分不同的算子,一般的合流操作connect 翻译为“连接”,而把 join 翻译为“联结”。
# 窗口联结(Window Join)
基于时间的操作,最基本的当然就是时间窗口了。我们之前已经介绍过 Window API 的用法,主要是针对单一数据流在某些时间段内的处理计算。那如果我们希望将两条流的数据进行合并、且同样针对某段时间进行处理和统计,又该怎么做呢?
Flink 为这种场景专门提供了一个窗口联结(window join)算子,可以定义时间窗口,并将两条流中共享一个公共键(key)的数据放在窗口中进行配对处理。
# 窗口联结的调用
窗口联结在代码中的实现,首先需要调用 DataStream 的.join()方法来合并两条流,得到一个 JoinedStreams;接着通过.where()和.equalTo()方法指定两条流中联结的 key;然后通过.window()开窗口,并调用.apply()传入联结窗口函数进行处理计算。通用调用形式如下:
stream1.join(stream2)
.where(<KeySelector>)
.equalTo(<KeySelector>)
.window(<WindowAssigner>)
.apply(<JoinFunction>)
2
3
4
5
上面代码中.where()的参数是键选择器(KeySelector),用来指定第一条流中的 key;而.equalTo()传入的 KeySelector 则指定了第二条流中的 key。两者相同的元素,如果在同一窗口中,就可以匹配起来,并通过一个“联结函数”(JoinFunction)进行处理了。
这里.window()传入的就是窗口分配器,之前讲到的三种时间窗口都可以用在这里:滚动窗口(tumbling window)、滑动窗口(sliding window)和会话窗口(session window)。
而后面调用.apply()可以看作实现了一个特殊的窗口函数。注意这里只能调用.apply(),没有其他替代的方法。
传入的 JoinFunction 也是一个函数类接口,使用时需要实现内部的.join()方法。这个方法有两个参数,分别表示两条流中成对匹配的数据。JoinFunction 在源码中的定义如下:
public interface JoinFunction<IN1, IN2, OUT> extends Function, Serializable {
OUT join(IN1 first, IN2 second) throws Exception;
}
2
3
这里需要注意,JoinFunciton 并不是真正的“窗口函数”,它只是定义了窗口函数在调用时对匹配数据的具体处理逻辑。
当然,既然是窗口计算,在.window()和.apply()之间也可以调用可选 API 去做一些自定义,比如用.trigger()定义触发器,用.allowedLateness()定义允许延迟时间,等等。
# 窗口联结的处理流程
JoinFunction 中的两个参数,分别代表了两条流中的匹配的数据。这里就会有一个问题:什么时候就会匹配好数据,调用.join()方法呢?接下来我们就来介绍一下窗口 join 的具体处理流程。
两条流的数据到来之后,首先会按照 key 分组、进入对应的窗口中存储;当到达窗口结束时间时,算子会先统计出窗口内两条流的数据的所有组合,也就是对两条流中的数据做一个笛卡尔积(相当于表的交叉连接,cross join),然后进行遍历,把每一对匹配的数据,作为参数(first,second)传入 JoinFunction 的.join()方法进行计算处理,得到的结果直接输出如图 8-8 所示。所以窗口中每有一对数据成功联结匹配,JoinFunction 的.join()方法就会被调用一次,并输出一个结果。
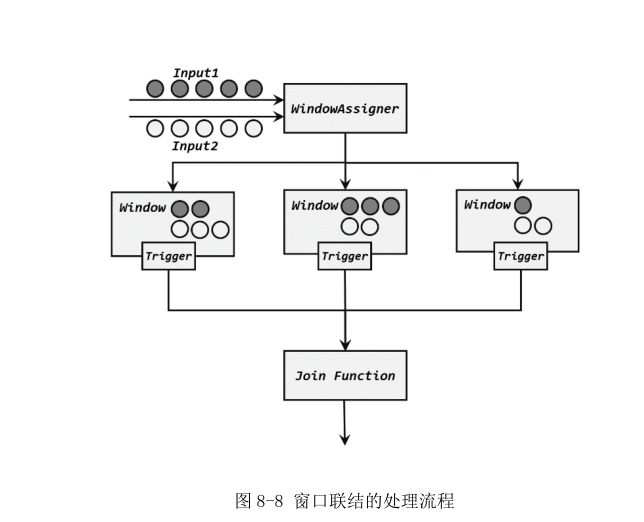
除了 JoinFunction,在.apply()方法中还可以传入 FlatJoinFunction,用法非常类似,只是内部需要实现的.join()方法没有返回值。结果的输出是通过收集器(Collector)来实现的,所以对于一对匹配数据可以输出任意条结果。
其实仔细观察可以发现,窗口 join 的调用语法和我们熟悉的 SQL 中表的 join 非常相似:
SELECT * FROM table1 t1, table2 t2 WHERE t1.id = t2.id;
这句 SQL 中 where 子句的表达,等价于 inner join ... on,所以本身表示的是两张表基于 id的“内连接”(inner join)。而 Flink 中的 window join,同样类似于 inner join。也就是说,最后处理输出的,只有两条流中数据按 key 配对成功的那些;如果某个窗口中一条流的数据没有任何另一条流的数据匹配,那么就不会调用 JoinFunction 的.join()方法,也就没有任何输出了。
# 窗口联结实例
在电商网站中,往往需要统计用户不同行为之间的转化,这就需要对不同的行为数据流,按照用户 ID 进行分组后再合并,以分析它们之间的关联。如果这些是以固定时间周期(比如1 小时)来统计的,那我们就可以使用窗口 join 来实现这样的需求。
public class Demo_05_WindowJoin {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
SingleOutputStreamOperator<Tuple2<String, Long>> stream1 = env.fromElements(
Tuple2.of("a", 1000L),
Tuple2.of("b", 1000L),
Tuple2.of("a", 2000L),
Tuple2.of("b", 2000L)
).assignTimestampsAndWatermarks(
WatermarkStrategy.<Tuple2<String, Long>>forMonotonousTimestamps()
.withTimestampAssigner(new SerializableTimestampAssigner<Tuple2<String, Long>>() {
@Override
public long extractTimestamp(Tuple2<String, Long> element, long l) {
return element.f1;
}
})
);
SingleOutputStreamOperator<Tuple2<String, Long>> stream2 = env.fromElements(
Tuple2.of("a", 3000L),
Tuple2.of("b", 3000L),
Tuple2.of("a", 4000L),
Tuple2.of("b", 4000L)
).assignTimestampsAndWatermarks(
WatermarkStrategy.<Tuple2<String, Long>>forMonotonousTimestamps()
.withTimestampAssigner(new SerializableTimestampAssigner<Tuple2<String, Long>>() {
@Override
public long extractTimestamp(Tuple2<String, Long> element, long l) {
return element.f1;
}
})
);
stream1.join(stream2)
.where(e1 -> e1.f0)
.equalTo(e2 -> e2.f0)
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.apply(new JoinFunction<Tuple2<String, Long>, Tuple2<String, Long>, String>() {
@Override
public String join(Tuple2<String, Long> left, Tuple2<String, Long> right) throws Exception {
return left + "=>" + right;
}
}).print();
env.execute();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
(a,1000)=>(a,3000)
(a,1000)=>(a,4000)
(a,2000)=>(a,3000)
(a,2000)=>(a,4000)
(b,1000)=>(b,3000)
(b,1000)=>(b,4000)
(b,2000)=>(b,3000)
(b,2000)=>(b,4000)
2
3
4
5
6
7
8
# 间隔联结(Interval Join)
在有些场景下,我们要处理的时间间隔可能并不是固定的。比如,在交易系统中,需要实时地对每一笔交易进行核验,保证两个账户转入转出数额相等,也就是所谓的“实时对账”。两次转账的数据可能写入了不同的日志流,它们的时间戳应该相差不大,所以我们可以考虑只统计一段时间内是否有出账入账的数据匹配。这时显然不应该用滚动窗口或滑动窗口来处理——因为匹配的两个数据有可能刚好“卡在”窗口边缘两侧,于是窗口内就都没有匹配了;会话窗口虽然时间不固定,但也明显不适合这个场景。 基于时间的窗口联结已经无能为力了。
为了应对这样的需求,Flink 提供了一种叫作“间隔联结”(interval join)的合流操作。顾名思义,间隔联结的思路就是针对一条流的每个数据,开辟出其时间戳前后的一段时间间隔,看这期间是否有来自另一条流的数据匹配。
# 间隔联结的原理
间隔联结具体的定义方式是,我们给定两个时间点,分别叫作间隔的“上界” (upperBound)和“下界”(lowerBound);于是对于一条流(不妨叫作 A)中的任意一个数据元素 a,就可以开辟一段时间间隔:[a.timestamp + lowerBound, a.timestamp + upperBound],即以 a 的时间戳为中心,下至下界点、上至上界点的一个闭区间:我们就把这段时间作为可以匹配另一条流数据的“窗口”范围。所以对于另一条流(不妨叫 B)中的数据元素 b,如果它的时间戳落在了这个区间范围内,a 和 b 就可以成功配对,进而进行计算输出结果。所以匹配的条件为:
a.timestamp + lowerBound <= b.timestamp <= a.timestamp + upperBound
这里需要注意,做间隔联结的两条流 A 和 B,也必须基于相同的 key;下界 lowerBound应该小于等于上界 upperBound,两者都可正可负;间隔联结目前只支持事件时间语义。如图 8-9 所示,我们可以清楚地看到间隔联结的方式:
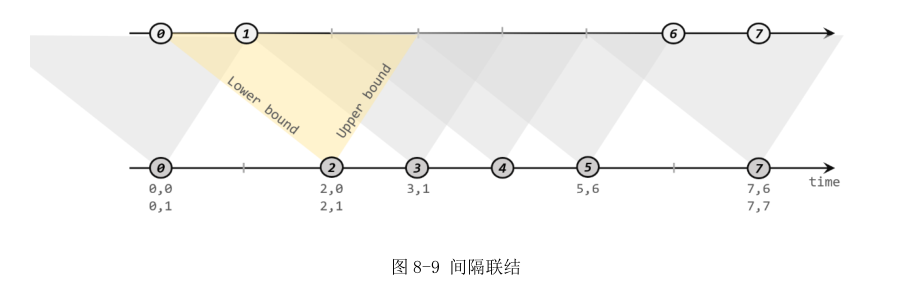
下方的流 A 去间隔联结上方的流 B,所以基于 A 的每个数据元素,都可以开辟一个间隔区间。我们这里设置下界为-2 毫秒,上界为 1 毫秒。于是对于时间戳为 2 的 A 中元素,它的可匹配区间就是[0, 3],流 B 中有时间戳为 0、1 的两个元素落在这个范围内,所以就可以得到匹配数据对(2, 0)和(2, 1)。同样地,A 中时间戳为 3 的元素,可匹配区间为[1, 4],B 中只有时间戳为 1 的一个数据可以匹配,于是得到匹配数据对(3, 1)。
所以我们可以看到,间隔联结同样是一种内连接(inner join)。与窗口联结不同的是,intervaljoin 做匹配的时间段是基于流中数据的,所以并不确定;而且流 B 中的数据可以不只在一个区间内被匹配。
# 间隔联结的调用
间隔联结在代码中,是基于 KeyedStream 的联结(join)操作。DataStream 在 keyBy 得到KeyedStream 之后,可以调用.intervalJoin()来合并两条流,传入的参数同样是一个 KeyedStream,两者的 key 类型应该一致;得到的是一个 IntervalJoin 类型。后续的操作同样是完全固定的:先通过.between()方法指定间隔的上下界,再调用.process()方法,定义对匹配数据对的处理操作。调用.process()需要传入一个处理函数,这是处理函数家族的最后一员:“处理联结函数”ProcessJoinFunction。
stream1
.keyBy(<KeySelector>)
.intervalJoin(stream2.keyBy(<KeySelector>))
.between(Time.milliseconds(-2), Time.milliseconds(1))
.process (new ProcessJoinFunction<Integer, Integer, String(){
@Override
public void processElement(Integer left, Integer right, Context ctx,
Collector<String> out) {
out.collect(left + "," + right);
}
});
2
3
4
5
6
7
8
9
10
11
可以看到,抽象类 ProcessJoinFunction 就像是 ProcessFunction 和 JoinFunction 的结合,内部同样有一个抽象方法.processElement()。与其他处理函数不同的是,它多了一个参数,这自然是因为有来自两条流的数据。参数中 left 指的就是第一条流中的数据,right 则是第二条流中与它匹配的数据。每当检测到一组匹配,就会调用这里的.processElement()方法,经处理转换之后输出结果。
# 间隔联结实例
在电商网站中,某些用户行为往往会有短时间内的强关联。我们这里举一个例子,我们有两条流,一条是下订单的流,一条是浏览数据的流。我们可以针对同一个用户,来做这样一个联结。也就是使用一个用户的下订单的事件和这个用户的最近十分钟的浏览数据进行一个联结查询。
public class Demo_06_IntervalJoin {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
SingleOutputStreamOperator<Tuple3<String, String, Long>> orderStream =
env.fromElements(
Tuple3.of("Mary", "order-1", 5000L),
Tuple3.of("Alice", "order-2", 5000L),
Tuple3.of("Bob", "order-3", 20000L),
Tuple3.of("Alice", "order-4", 20000L),
Tuple3.of("Cary", "order-5", 51000L)
).assignTimestampsAndWatermarks(WatermarkStrategy.<Tuple3<String, String, Long>>forMonotonousTimestamps()
.withTimestampAssigner(
new SerializableTimestampAssigner<Tuple3<String, String, Long>>() {
@Override
public long extractTimestamp(Tuple3<String, String, Long>
element, long recordTimestamp) {
return element.f2;
}
})
);
SingleOutputStreamOperator<Event> clickStream = env.fromElements(
new Event("Bob", "./cart", 2000L),
new Event("Alice", "./prod?id=100", 3000L),
new Event("Alice", "./prod?id=200", 3500L),
new Event("Bob", "./prod?id=2", 2500L),
new Event("Alice", "./prod?id=300", 36000L),
new Event("Bob", "./home", 30000L),
new Event("Bob", "./prod?id=1", 23000L),
new Event("Bob", "./prod?id=3", 33000L)
).assignTimestampsAndWatermarks(WatermarkStrategy.<Event>forMonotonousTimestamps()
.withTimestampAssigner(new SerializableTimestampAssigner<Event>()
{
@Override
public long extractTimestamp(Event element, long recordTimestamp)
{
return element.timestamp;
}
})
);
orderStream.keyBy(data -> data.f0)
.intervalJoin(clickStream.keyBy(event -> event.user))
.between(Time.seconds(-5), Time.seconds(10))
.process(new ProcessJoinFunction<Tuple3<String, String, Long>, Event, String>() {
@Override
public void processElement(Tuple3<String, String, Long> right, Event left, ProcessJoinFunction<Tuple3<String, String, Long>, Event, String>.Context context, Collector<String> out) throws Exception {
out.collect(right + " => " + left);
}
}).print();
env.execute();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
(Alice,order-2,5000) => Event{user='Alice', url='./prod?id=100', timestamp={SysUpTime = 0:0:30} {Timestamp = Thu Mar 24 14:46:40 CST 2022}}
(Alice,order-2,5000) => Event{user='Alice', url='./prod?id=200', timestamp={SysUpTime = 0:0:35} {Timestamp = Thu Mar 24 14:46:40 CST 2022}}
(Bob,order-3,20000) => Event{user='Bob', url='./home', timestamp={SysUpTime = 0:5:0} {Timestamp = Thu Mar 24 14:46:40 CST 2022}}
(Bob,order-3,20000) => Event{user='Bob', url='./prod?id=1', timestamp={SysUpTime = 0:3:50} {Timestamp = Thu Mar 24 14:46:40 CST 2022}}
2
3
4
# 窗口同组联结(Window CoGroup)
除窗口联结和间隔联结之外,Flink 还提供了一个“窗口同组联结”(window coGroup)操作。它的用法跟 window join 非常类似,也是将两条流合并之后开窗处理匹配的元素,调用时只需要将.join()换为.coGroup()就可以了。
stream1.coGroup(stream2)
.where(<KeySelector>)
.equalTo(<KeySelector>)
.window(TumblingEventTimeWindows.of(Time.hours(1)))
.apply(<CoGroupFunction>)
2
3
4
5
与 window join 的区别在于,调用.apply()方法定义具体操作时,传入的是一个CoGroupFunction。这也是一个函数类接口,源码中定义如下:
public interface CoGroupFunction<IN1, IN2, O> extends Function, Serializable {
void coGroup(Iterable<IN1> first, Iterable<IN2> second, Collector<O> out) throws Exception;
}
2
3
内部的.coGroup()方法,有些类似于 FlatJoinFunction 中.join()的形式,同样有三个参数,分别代表两条流中的数据以及用于输出的收集器(Collector)。不同的是,这里的前两个参数不再是单独的每一组“配对”数据了,而是传入了可遍历的数据集合。也就是说,现在不会再去计算窗口中两条流数据集的笛卡尔积,而是直接把收集到的所有数据一次性传入,至于要怎样配对完全是自定义的。这样.coGroup()方法只会被调用一次,而且即使一条流的数据没有任何另一条流的数据匹配,也可以出现在集合中、当然也可以定义输出结果了。
所以能够看出,coGroup 操作比窗口的 join 更加通用,不仅可以实现类似 SQL 中的“内连接”(inner join),也可以实现左外连接(left outer join)、右外连接(right outer join)和全外连接(full outer join)。事实上,窗口 join 的底层,也是通过 coGroup 来实现的。下面是一段 coGroup 的示例代码:
public class Demo_07_CoGroup {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
SingleOutputStreamOperator<Tuple2<String, Long>> stream1 = env.fromElements(
Tuple2.of("a", 1000L),
Tuple2.of("b", 1000L),
Tuple2.of("a", 2000L),
Tuple2.of("b", 2000L),
Tuple2.of("c", 2000L)
).assignTimestampsAndWatermarks(
WatermarkStrategy.<Tuple2<String, Long>>forMonotonousTimestamps()
.withTimestampAssigner(new SerializableTimestampAssigner<Tuple2<String, Long>>() {
@Override
public long extractTimestamp(Tuple2<String, Long> element, long l) {
return element.f1;
}
})
);
SingleOutputStreamOperator<Tuple2<String, Long>> stream2 = env.fromElements(
Tuple2.of("a", 3000L),
Tuple2.of("b", 3000L),
Tuple2.of("a", 4000L),
Tuple2.of("b", 4000L),
Tuple2.of("d", 4000L)
).assignTimestampsAndWatermarks(
WatermarkStrategy.<Tuple2<String, Long>>forMonotonousTimestamps()
.withTimestampAssigner(new SerializableTimestampAssigner<Tuple2<String, Long>>() {
@Override
public long extractTimestamp(Tuple2<String, Long> element, long l) {
return element.f1;
}
})
);
stream1.coGroup(stream2)
.where(e1 -> e1.f0)
.equalTo(e2 -> e2.f0)
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.apply(
new CoGroupFunction<Tuple2<String, Long>, Tuple2<String, Long>, String>() {
@Override
public void coGroup(Iterable<Tuple2<String, Long>> iter1, Iterable<Tuple2<String, Long>> iter2, Collector<String> collector) throws Exception {
collector.collect(iter1 + "=>" + iter2);
}
}).print();
env.execute();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
[(a,1000), (a,2000)]=>[(a,3000), (a,4000)]
[]=>[(d,4000)]
[(c,2000)]=>[]
[(b,1000), (b,2000)]=>[(b,3000), (b,4000)]
2
3
4
# 本章总结
多流转换是流处理在实际应用中常见的需求,主要包括分流和合流两大类,本章分别做了详细讲解。在 Flink 中,分流操作可以通过处理函数的侧输出流(side output)很容易地实现;而合流则提供不同层级的各种 API。
最基本的合流方式是联合(union)和连接(connect),两者的主要区别在于 union 可以对多条流进行合并,数据类型必须一致;而 connect 只能连接两条流,数据类型可以不同。事实上 connect 提供了最底层的处理函数(process function)接口,可以通过状态和定时器实现任意自定义的合流操作,所以是最为通用的合流方式。
除此之外,Flink 还提供了内置的几个联结(join)操作,它们都是基于某个时间段的双流合并,是需求特化之后的高层级 API。主要包括窗口联结(window join)、间隔联结(interval join)和窗口同组联结(window coGroup)。其中 window join 和 coGroup 都是基于时间窗口的操作,窗口分配器的定义与之前介绍的相同,而窗口函数则被限定为一种,通过.apply()来调用;interval join 则与窗口无关,而是基于每个数据元素截取对应的一个时间段来做联结,最终的 处理操作则需调用.process(),由处理函数 ProcessJoinFunction 实现。
可以看到,基于时间的联结操作的每一步操作都是固定的接口,并没有其他变化,使用起来“专项专用”,非常方便。
至此我们已经将 DataStream API 的主要用法介绍完毕,处理函数家族中的成员也都已一一亮相。而处理函数中一些比较高级和复杂的用法,往往会涉及定时器和状态。在下一章中,我们将继续深入展开,系统地介绍 Flink 的状态管理机制和状态编程的用法。
# 状态编程
Flink 处理机制的核心,就是“有状态的流式计算”。我们在之前的章节中也已经多次提到了“状态”(state),不论是简单聚合、窗口聚合,还是处理函数的应用,都会有状态的身影出现。在第一章中,我们已经简单介绍过有状态流处理,状态就如同事务处理时数据库中保存的信息一样,是用来辅助进行任务计算的数据。而在 Flink 这样的分布式系统中,我们不仅需要定义出状态在任务并行时的处理方式,还需要考虑如何持久化保存、以便发生故障时正确地恢复。这就需要一套完整的管理机制来处理所有的状态。
本章将从状态的概念入手,详细介绍 Flink 中的状态分类、状态的使用、持久化及状态后端的配置。
# Flink 中的状态
在流处理中,数据是连续不断到来和处理的。每个任务进行计算处理时,可以基于当前数据直接转换得到输出结果;也可以依赖一些其他数据。这些由一个任务维护,并且用来计算输出结果的所有数据,就叫作这个任务的状态。
# 有状态算子
在 Flink 中,算子任务可以分为无状态和有状态两种情况。
无状态的算子任务只需要观察每个独立事件,根据当前输入的数据直接转换输出结果,如图 9-1 所示。例如,可以将一个字符串类型的数据拆分开作为元组输出;也可以对数据做一些计算,比如每个代表数量的字段加 1。我们之前讲到的基本转换算子,如 map、filter、flatMap,计算时不依赖其他数据,就都属于无状态的算子。
而有状态的算子任务,则除当前数据之外,还需要一些其他数据来得到计算结果。这里的“其他数据”,就是所谓的状态(state),最常见的就是之前到达的数据,或者由之前数据计算出的某个结果。比如,做求和(sum)计算时,需要保存之前所有数据的和,这就是状态;窗口算子中会保存已经到达的所有数据,这些也都是它的状态。另外,如果我们希望检索到某种“事件模式”(event pattern),比如“先有下单行为,后有支付行为”,那么也应该把之前的行为保存下来,这同样属于状态。容易发现,之前讲过的聚合算子、窗口算子都属于有状态的算子。

如图 9-2 所示为有状态算子的一般处理流程,具体步骤如下。
- 算子任务接收到上游发来的数据;
- 获取当前状态;
- 根据业务逻辑进行计算,更新状态;
- 得到计算结果,输出发送到下游任务。
# 状态的管理
在传统的事务型处理架构中,这种额外的状态数据是保存在数据库中的。而对于实时流处理来说,这样做需要频繁读写外部数据库,如果数据规模非常大肯定就达不到性能要求了。所以 Flink 的解决方案是,将状态直接保存在内存中来保证性能,并通过分布式扩展来提高吞吐量。
在 Flink 中,每一个算子任务都可以设置并行度,从而可以在不同的 slot 上并行运行多个实例,我们把它们叫作“并行子任务”。而状态既然在内存中,那么就可以认为是子任务实例上的一个本地变量,能够被任务的业务逻辑访问和修改。
这样看来状态的管理似乎非常简单,我们直接把它作为一个对象交给 JVM 就可以了。然而大数据的场景下,我们必须使用分布式架构来做扩展,在低延迟、高吞吐的基础上还要保证容错性,一系列复杂的问题就会随之而来了。
- 状态的访问权限。我们知道 Flink 上的聚合和窗口操作,一般都是基于 KeyedStream的,数据会按照 key 的哈希值进行分区,聚合处理的结果也应该是只对当前 key 有效。然而同一个分区(也就是 slot)上执行的任务实例,可能会包含多个 key 的数据,它们同时访问和更改本地变量,就会导致计算结果错误。所以这时状态并不是单纯的本地变量。
- 容错性,也就是故障后的恢复。状态只保存在内存中显然是不够稳定的,我们需要将它持久化保存,做一个备份;在发生故障后可以从这个备份中恢复状态。
- 我们还应该考虑到分布式应用的横向扩展性。比如处理的数据量增大时,我们应该相应地对计算资源扩容,调大并行度。这时就涉及到了状态的重组调整。
可见状态的管理并不是一件轻松的事。好在 Flink 作为有状态的大数据流式处理框架,已经帮我们搞定了这一切。Flink 有一套完整的状态管理机制,将底层一些核心功能全部封装起来,包括状态的高效存储和访问、持久化保存和故障恢复,以及资源扩展时的调整。这样,我们只需要调用相应的 API 就可以很方便地使用状态,或对应用的容错机制进行配置,从而将更多的精力放在业务逻辑的开发上。
# 状态的分类
# 托管状态(Managed State)和原始状态(Raw State)
Flink 的状态有两种:托管状态(Managed State)和原始状态(Raw State)。托管状态就是由 Flink 统一管理的,状态的存储访问、故障恢复和重组等一系列问题都由 Flink 实现,我们只要调接口就可以;而原始状态则是自定义的,相当于就是开辟了一块内存,需要我们自己管理,实现状态的序列化和故障恢复。
具体来讲,托管状态是由 Flink 的运行时(Runtime)来托管的;在配置容错机制后,状态会自动持久化保存,并在发生故障时自动恢复。当应用发生横向扩展时,状态也会自动地重组分配到所有的子任务实例上。对于具体的状态内容,Flink 也提供了值状态(ValueState)、列表状态(ListState)、映射状态(MapState)、聚合状态(AggregateState)等多种结构,内部支持各种数据类型。聚合、窗口等算子中内置的状态,就都是托管状态;我们也可以在富函数 类(RichFunction)中通过上下文来自定义状态,这些也都是托管状态。
而对比之下,原始状态就全部需要自定义了。Flink 不会对状态进行任何自动操作,也不知道状态的具体数据类型,只会把它当作最原始的字节(Byte)数组来存储。我们需要花费大量的精力来处理状态的管理和维护。
所以只有在遇到托管状态无法实现的特殊需求时,我们才会考虑使用原始状态;一般情况下不推荐使用。绝大多数应用场景,我们都可以用 Flink 提供的算子或者自定义托管状态来实现需求。
# 算子状态(Operator State)和按键分区状态(Keyed State)
接下来我们的重点就是托管状态(Managed State)。
我们知道在 Flink 中,一个算子任务会按照并行度分为多个并行子任务执行,而不同的子任务会占据不同的任务槽(task slot)。由于不同的 slot 在计算资源上是物理隔离的,所以 Flink能管理的状态在并行任务间是无法共享的,每个状态只能针对当前子任务的实例有效。
而很多有状态的操作(比如聚合、窗口)都是要先做 keyBy 进行按键分区的。按键分区之后,任务所进行的所有计算都应该只针对当前 key 有效,所以状态也应该按照 key 彼此隔离。在这种情况下,状态的访问方式又会有所不同。
基于这样的想法,我们又可以将托管状态分为两类:算子状态和按键分区状态。
# 算子状态(Operator State)
状态作用范围限定为当前的算子任务实例,也就是只对当前并行子任务实例有效。这就意味着对于一个并行子任务,占据了一个“分区”,它所处理的所有数据都会访问到相同的状态,状态对于同一任务而言是共享的,如图 9-3 所示

算子状态可以用在所有算子上,使用的时候其实就跟一个本地变量没什么区别——因为本地变量的作用域也是当前任务实例。在使用时,我们还需进一步实现 CheckpointedFunction 接口。
# 按键分区状态(Keyed State)
状态是根据输入流中定义的键(key)来维护和访问的,所以只能定义在按键分区流(KeyedStream)中,也就 keyBy 之后才可以使用,如图 9-4 所示。

按键分区状态应用非常广泛。之前讲到的聚合算子必须在 keyBy 之后才能使用,就是因为聚合的结果是以 Keyed State 的形式保存的。另外,也可以通过富函数类(Rich Function)来自定义 Keyed State,所以只要提供了富函数类接口的算子,也都可以使用 Keyed State。
所以即使是 map、filter 这样无状态的基本转换算子,我们也可以通过富函数类给它们“追加”Keyed State,或者实现 CheckpointedFunction 接口来定义 Operator State;从这个角度讲,Flink 中所有的算子都可以是有状态的,不愧是“有状态的流处理”。
无论是 Keyed State 还是 Operator State,它们都是在本地实例上维护的,也就是说每个并行子任务维护着对应的状态,算子的子任务之间状态不共享。关于状态的具体使用,我们会在下面继续展开讲解。
# 按键分区状态(Keyed State)
在实际应用中,我们一般都需要将数据按照某个 key 进行分区,然后再进行计算处理;所以最为常见的状态类型就是 Keyed State。之前介绍到 keyBy 之后的聚合、窗口计算,算子所持有的状态,都是 Keyed State。
另外,我们还可以通过富函数类(Rich Function)对转换算子进行扩展、实现自定义功能,比如 RichMapFunction、RichFilterFunction。在富函数中,我们可以调用.getRuntimeContext()获取当前的运行时上下文(RuntimeContext),进而获取到访问状态的句柄;这种富函数中自定义的状态也是 Keyed State。
# 基本概念和特点
按键分区状态(Keyed State)顾名思义,是任务按照键(key)来访问和维护的状态。它的特点非常鲜明,就是以 key 为作用范围进行隔离。
我们知道,在进行按键分区(keyBy)之后,具有相同键的所有数据,都会分配到同一个并行子任务中;所以如果当前任务定义了状态,Flink 就会在当前并行子任务实例中,为每个键值维护一个状态的实例。于是当前任务就会为分配来的所有数据,按照 key 维护和处理对应的状态。
因为一个并行子任务可能会处理多个 key 的数据,所以 Flink 需要对 Keyed State 进行一些特殊优化。在底层,Keyed State 类似于一个分布式的映射(map)数据结构,所有的状态会根据 key 保存成键值对(key-value)的形式。这样当一条数据到来时,任务就会自动将状态的访问范围限定为当前数据的 key,从 map 存储中读取出对应的状态值。所以具有相同 key 的所有数据都会到访问相同的状态,而不同 key 的状态之间是彼此隔离的。
这种将状态绑定到 key 上的方式,相当于使得状态和流的逻辑分区一一对应了:不会有别的 key 的数据来访问当前状态;而当前状态对应 key 的数据也只会访问这一个状态,不会分发到其他分区去。这就保证了对状态的操作都是本地进行的,对数据流和状态的处理做到了分区一致性。
另外,在应用的并行度改变时,状态也需要随之进行重组。不同 key 对应的 Keyed State可以进一步组成所谓的键组(key groups),每一组都对应着一个并行子任务。键组是 Flink 重新分配 Keyed State 的单元,键组的数量就等于定义的最大并行度。当算子并行度发生改变时,Keyed State 就会按照当前的并行度重新平均分配,保证运行时各个子任务的负载相同。
# 支持的结构类型
实际应用中,需要保存为状态的数据会有各种各样的类型,有时还需要复杂的集合类型,比如列表(List)和映射(Map)。对于这些常见的用法,Flink 的按键分区状态(Keyed State)提供了足够的支持。接下来我们就来了解一下 Keyed State 所支持的结构类型.
# 值状态(ValueState)
顾名思义,状态中只保存一个“值”(value)。ValueState
public interface ValueState<T> extends State {
T value() throws IOException;
void update(T value) throws IOException;
}
2
3
4
这里的 T 是泛型,表示状态的数据内容可以是任何具体的数据类型。如果想要保存一个长整型值作为状态,那么类型就是 ValueState
我们可以在代码中读写值状态,实现对于状态的访问和更新。
- T value():获取当前状态的值;
- update(T value):对状态进行更新,传入的参数 value 就是要覆写的状态值。
在具体使用时,为了让运行时上下文清楚到底是哪个状态,我们还需要创建一个“状态描述器”(StateDescriptor)来提供状态的基本信息。例如源码中,ValueState 的状态描述器构造方法如下:
public ValueStateDescriptor(String name, Class<T> typeClass) {
super(name, typeClass, null);
}
2
3
这里需要传入状态的名称和类型——这跟我们声明一个变量时做的事情完全一样。有了这个描述器,运行时环境就可以获取到状态的控制句柄(handler)了。关于代码中状态的使用,我们会在下一节详细介绍。
# 列表状态(ListState)
将需要保存的数据,以列表(List)的形式组织起来。在 ListState
- Iterable
get():获取当前的列表状态,返回的是一个可迭代类型 Iterable ; - update(List
values):传入一个列表 values,直接对状态进行覆盖; - add(T value):在状态列表中添加一个元素 value;
- addAll(List
values):向列表中添加多个元素,以列表 values 形式传入。
类似地,ListState 的状态描述器就叫作 ListStateDescriptor,用法跟 ValueStateDescriptor完全一致。
# 映射状态(MapState)
把一些键值对(key-value)作为状态整体保存起来,可以认为就是一组 key-value 映射的列表。对应的 MapState<UK, UV>接口中,就会有 UK、UV 两个泛型,分别表示保存的 key和 value 的类型。同样,MapState 提供了操作映射状态的方法,与 Map 的使用非常类似。
- UV get(UK key):传入一个 key 作为参数,查询对应的 value 值;
- put(UK key, UV value):传入一个键值对,更新 key 对应的 value 值;
- putAll(Map<UK, UV> map):将传入的映射 map 中所有的键值对,全部添加到映射状态中;
- remove(UK key):将指定 key 对应的键值对删除;
- boolean contains(UK key):判断是否存在指定的 key,返回一个 boolean 值。另外,MapState 也提供了获取整个映射相关信息的方法:
- Iterable<Map.Entry<UK, UV>> entries():获取映射状态中所有的键值对;
- Iterable
keys():获取映射状态中所有的键(key),返回一个可迭代 Iterable 类型; - Iterable
values():获取映射状态中所有的值(value),返回一个可迭代 Iterable类型; - boolean isEmpty():判断映射是否为空,返回一个 boolean 值。
# 归约状态(ReducingState)
类似于值状态(Value),不过需要对添加进来的所有数据进行归约,将归约聚合之后的值作为状态保存下来。ReducintState
归约逻辑的定义,是在归约状态描述器(ReducingStateDescriptor)中,通过传入一个归约函数(ReduceFunction)来实现的。这里的归约函数,就是我们之前介绍 reduce 聚合算子时讲到的 ReduceFunction,所以状态类型跟输入的数据类型是一样的。
public ReducingStateDescriptor(String name, ReduceFunction<T> reduceFunction, Class<T> typeClass) {...}
这里的描述器有三个参数,其中第二个参数就是定义了归约聚合逻辑的 ReduceFunction,另外两个参数则是状态的名称和类型。
# 聚合状态(AggregatingState)
与归约状态非常类似,聚合状态也是一个值,用来保存添加进来的所有数据的聚合结果。与 ReducingState 不同的是,它的聚合逻辑是由在描述器中传入一个更加一般化的聚合函数(AggregateFunction)来定义的;这也就是之前我们讲过的 AggregateFunction,里面通过一个累加器(Accumulator)来表示状态,所以聚合的状态类型可以跟添加进来的数据类型完全不同,使用更加灵活。
同样地,AggregatingState 接口调用方法也与 ReducingState 相同,调用.add()方法添加元素时,会直接使用指定的 AggregateFunction 进行聚合并更新状态。
# 代码实现
了解了按键分区状态(Keyed State)的基本概念和类型,接下来我们就可以尝试在代码中使用状态了。
# 整体介绍
在 Flink 中,状态始终是与特定算子相关联的;算子在使用状态前首先需要“注册”,其实就是告诉 Flink 当前上下文中定义状态的信息,这样运行时的 Flink 才能知道算子有哪些状态。
状态的注册,主要是通过“状态描述器”(StateDescriptor)来实现的。状态描述器中最重要的内容,就是状态的名称(name)和类型(type)。我们知道 Flink 中的状态,可以认为是加了一些复杂操作的内存中的变量;而当我们在代码中声明一个局部变量时,都需要指定变量类型和名称,名称就代表了变量在内存中的地址,类型则指定了占据内存空间的大小。同样地,我们一旦指定了名称和类型,Flink 就可以在运行时准确地在内存中找到对应的状态,进而返回状态对象供我们使用了。所以在一个算子中,我们也可以定义多个状态,只要它们的名称不同就可以了。
另外,状态描述器中还可能需要传入一个用户自定义函数(user-defined-function,UDF),用来说明处理逻辑,比如前面提到的 ReduceFunction 和 AggregateFunction。
以 ValueState 为例,我们可以定义值状态描述器如下:
ValueStateDescriptor<Long> descriptor = new ValueStateDescriptor<>(
"my state", // 状态名称
Types.LONG // 状态类型
);
2
3
4
这里我们定义了一个叫作“my state”的长整型 ValueState 的描述器。
代码中完整的操作是,首先定义出状态描述器;然后调用.getRuntimeContext()方法获取运行时上下文;继而调用 RuntimeContext 的获取状态的方法,将状态描述器传入,就可以得到对应的状态了
因为状态的访问需要获取运行时上下文,这只能在富函数类(Rich Function)中获取到,所以自定义的 Keyed State 只能在富函数中使用。当然,底层的处理函数(Process Function)本身继承了 AbstractRichFunction 抽象类,所以也可以使用。
在富函数中,调用.getRuntimeContext()方法获取到运行时上下文之后,RuntimeContext 有以下几个获取状态的方法:
ValueState<T> getState(ValueStateDescriptor<T>)
MapState<UK, UV> getMapState(MapStateDescriptor<UK, UV>)
ListState<T> getListState(ListStateDescriptor<T>)
ReducingState<T> getReducingState(ReducingStateDescriptor<T>)
AggregatingState<IN, OUT> getAggregatingState(AggregatingStateDescriptor<IN,ACC, OUT>)
2
3
4
5
对于不同结构类型的状态,只要传入对应的描述器、调用对应的方法就可以了。
获取到状态对象之后,就可以调用它们各自的方法进行读写操作了。另外,所有类型的状态都有一个方法.clear(),用于清除当前状态。
代码中使用状态的整体结构如下:
public class Demo_01_State_MyFlatMapFunction extends RichFlatMapFunction<Long,String> {
// 声明状态
private transient ValueState<Long> state;
@Override
public void open(Configuration parameters) throws Exception {
// 在 open 生命周期方法中获取状态
ValueStateDescriptor<Long> descriptor = new ValueStateDescriptor<>(
"my state", // 状态名称
Types.LONG // 状态类型
);
state = getRuntimeContext().getState(descriptor);
}
@Override
public void flatMap(Long aLong, Collector<String> out) throws Exception {
// 访问状态
Long currentState = state.value();
currentState += 1; // 状态数值加 1
// 更新状态
state.update(currentState);
if (currentState >= 100) {
out.collect("state: " + currentState);
state.clear(); // 清空状态
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
因为 RichFlatmapFunction 中的.flatmap()是每来一条数据都会调用一次的,所以我们不应该在这里调用运行时上下文的.getState()方法,而是在生命周期方法.open()中获取状态对象。另外还有一个问题,我们获取到的状态对象也需要有一个变量名称 state(注意这里跟状态的名称 my state 不同),但这个变量不应该在 open 中声明——否则在.flatmap()里就访问不到了。所以我们还需要在外面直接把它定义为类的属性,这样就可以在不同的方法中通用了。而在外部 又不能直接获取状态,因为编译时是无法拿到运行时上下文的。所以最终的解决方案就变成了:在外部声明状态对象,在 open 生命周期方法中通过运行时上下文获取状态。
这里需要注意,这种方式定义的都是 Keyed State,它对于每个 key 都会保存一份状态实例。所以对状态进行读写操作时,获取到的状态跟当前输入数据的 key 有关;只有相同 key的数据,才会操作同一个状态,不同 key 的数据访问到的状态值是不同的。而且上面提到的.clear()方法,也只会清除当前 key 对应的状态。
另外,状态不一定都存储在内存中,也可以放在磁盘或其他地方,具体的位置是由一个可配置的组件来管理的,这个组件叫作“状态后端”(State Backend)。关于状态后端,我们会在9.5 节详细介绍。
public class Demo_02_State_Demo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
SingleOutputStreamOperator<Event> stream = env.addSource(new Demo_03_Source_Customer.ClickSource())
.assignTimestampsAndWatermarks(
WatermarkStrategy.<Event>forBoundedOutOfOrderness(Duration.ZERO)
.withTimestampAssigner(new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event event, long l) {
return event.timestamp;
}
})
);
stream.keyBy(data -> data.user)
.process(new KeyedProcessFunction<String, Event, String>() {
ValueState<String> valueState;
ListState<String> listState;
MapState<String,Integer> mapState;
ReducingState<Event> reducerState;
AggregatingState<Event,String> aggregatingState;
@Override
public void open(Configuration parameters) throws Exception {
valueState = getRuntimeContext().getState(new ValueStateDescriptor<String>("valueState",String.class));
listState = getRuntimeContext().getListState(new ListStateDescriptor<String>("listState",String.class));
mapState = getRuntimeContext().getMapState(new MapStateDescriptor<String, Integer>("mapState",String.class,Integer.class));
reducerState = getRuntimeContext().getReducingState(new ReducingStateDescriptor<Event>("reducerState",
new ReduceFunction<Event>() {
@Override
public Event reduce(Event event, Event t1) throws Exception {
event.user = event.user + "~" + t1.user;
return event;
}
}
, Event.class));
aggregatingState = getRuntimeContext().getAggregatingState(new AggregatingStateDescriptor<Event, Long, String>("aggregatingState",
new AggregateFunction<Event, Long, String>() {
@Override
public Long createAccumulator() {
return 0L;
}
@Override
public Long add(Event event, Long aLong) {
return aLong ++;
}
@Override
public String getResult(Long aLong) {
return aLong + "~";
}
@Override
public Long merge(Long aLong, Long acc1) {
return null;
}
}
, Long.class));
}
@Override
public void processElement(Event event, KeyedProcessFunction<String, Event, String>.Context context, Collector<String> collector) throws Exception {
valueState.update(event.user);
System.out.println("valueState: " + valueState.value());
listState.add(event.user);
System.out.println("listState" + listState.get());
mapState.put(event.user, mapState.get(event.user) == null ? 1 : (mapState.get(event.user) + 1));
System.out.println("mapState" + mapState.iterator());
reducerState.add(event);
System.out.println("reducerState" + reducerState.get());
aggregatingState.add(event);
System.out.println("aggregatingState" + aggregatingState.get());
System.out.println("==================================================");
}
}).print();
env.execute();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
# 值状态(ValueState)
我们这里会使用用户 id 来进行分流,然后分别统计每个用户的 pv 数据,由于我们并不想每次 pv 加一,就将统计结果发送到下游去,所以这里我们注册了一个定时器,用来隔一段时间发送 pv 的统计结果,这样对下游算子的压力不至于太大。具体实现方式是定义一个用来保存定时器时间戳的值状态变量。当定时器触发并向下游发送数据以后,便清空储存定时器时间戳的状态变量,这样当新的数据到来时,发现并没有定时器存在,就可以注册新的定时器了,注册完定时器之后将定时器的时间戳继续保存在状态变量中。
public class Demo_03_State_PeriodicPvExample {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
SingleOutputStreamOperator<Event> stream = env.addSource(new Demo_03_Source_Customer.ClickSource())
.assignTimestampsAndWatermarks(
WatermarkStrategy.<Event>forBoundedOutOfOrderness(Duration.ZERO)
.withTimestampAssigner(new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event event, long l) {
return event.timestamp;
}
})
);
stream.keyBy(data -> data.user)
.process(new KeyedProcessFunction<String, Event, String>() {
private ValueState<Long> count;
private ValueState<Long> ts;
@Override
public void open(Configuration parameters) throws Exception {
count = getRuntimeContext().getState(new ValueStateDescriptor<Long>("count",Long.class));
ts = getRuntimeContext().getState(new ValueStateDescriptor<Long>("ts",Long.class));
}
@Override
public void processElement(Event event, KeyedProcessFunction<String, Event, String>.Context context, Collector<String> out) throws Exception {
System.out.println("生成数据:" + event);
// 更新 count 值
Long value = count.value();
if (value == null){
count.update(1L);
} else {
count.update(value + 1);
}
Long ts = this.ts.value();
if(ts == null) {
// 注册定时器
context.timerService().registerEventTimeTimer(event.timestamp + 10 * 1000L);
this.ts.update(event.timestamp);
}
}
@Override
public void onTimer(long timestamp, KeyedProcessFunction<String, Event, String>.OnTimerContext ctx, Collector<String> out) throws Exception {
System.out.println(ctx.getCurrentKey() + "->" + count.value());
System.out.println("ts: " + ts.value());
ts.update(null);
}
}).print();
env.execute();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
# 列表状态(ListState)
在 Flink SQL 中,支持两条流的全量 Join,语法如下:SELECT * FROM A INNER JOIN B WHERE A.id = B.id;这样一条 SQL 语句要慎用,因为 Flink 会将 A 流和 B 流的所有数据都保存下来,然后进行 Join。不过在这里我们可以用列表状态变量来实现一下这个 SQL 语句的功能。代码如下:
public class Demo_04_State_TwoStreamFullJoin {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
SingleOutputStreamOperator<Tuple3<String, String, Long>> stream1 = env
.fromElements(
Tuple3.of("a", "stream-1", 1000L),
Tuple3.of("b", "stream-1", 2000L)
)
.assignTimestampsAndWatermarks(
WatermarkStrategy.<Tuple3<String, String,
Long>>forMonotonousTimestamps()
.withTimestampAssigner(
new SerializableTimestampAssigner<Tuple3<String, String, Long>>() {
@Override
public long extractTimestamp(Tuple3<String,
String, Long> t, long l) {
return t.f2;
}
})
);
SingleOutputStreamOperator<Tuple3<String, String, Long>> stream2 = env
.fromElements(
Tuple3.of("a", "stream-2", 3000L),
Tuple3.of("b", "stream-2", 4000L)
)
.assignTimestampsAndWatermarks(
WatermarkStrategy.<Tuple3<String, String,
Long>>forMonotonousTimestamps()
.withTimestampAssigner(new SerializableTimestampAssigner<Tuple3<String, String, Long>>() {
@Override
public long extractTimestamp(Tuple3<String,
String, Long> t, long l) {
return t.f2;
}
})
);
stream1
.connect(stream2)
.keyBy(e1 -> e1.f0, e2 -> e2.f0)
.process(new CoProcessFunction<Tuple3<String, String, Long>, Tuple3<String, String, Long>, String>() {
ListState<Tuple3<String, String, Long>> first;
ListState<Tuple3<String, String, Long>> second;
@Override
public void open(Configuration parameters) throws Exception {
first = getRuntimeContext().getListState(new ListStateDescriptor<Tuple3<String, String, Long>>("first", Types.TUPLE(Types.STRING,Types.STRING,Types.LONG)));
second = getRuntimeContext().getListState(new ListStateDescriptor<Tuple3<String, String, Long>>("second", Types.TUPLE(Types.STRING,Types.STRING,Types.LONG)));
}
@Override
public void processElement1(Tuple3<String, String, Long> firstItem, CoProcessFunction<Tuple3<String, String, Long>, Tuple3<String, String, Long>, String>.Context context, Collector<String> collector) throws Exception {
for (Tuple3<String, String, Long> second : second.get()) {
System.out.println(firstItem + " -> " + second);
}
first.add(firstItem);
}
@Override
public void processElement2(Tuple3<String, String, Long> secondItem, CoProcessFunction<Tuple3<String, String, Long>, Tuple3<String, String, Long>, String>.Context context, Collector<String> collector) throws Exception {
for (Tuple3<String, String, Long> first : first.get()) {
System.out.println(secondItem + " -> " + first);
}
second.add(secondItem);
}
}).print();
env.execute();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
# 映射状态(MapState)
映射状态的用法和 Java 中的 HashMap 很相似。在这里我们可以通过 MapState 的使用来探索一下窗口的底层实现,也就是我们要用映射状态来完整模拟窗口的功能。这里我们模拟一个滚动窗口。我们要计算的是每一个 url 在每一个窗口中的 pv 数据。我们之前使用增量聚合和全窗口聚合结合的方式实现过这个需求。这里我们用 MapState 再来实现一下。
public class Demo_05_State_FakeWindow {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
SingleOutputStreamOperator<Event> stream = env.addSource(new Demo_03_Source_Customer.ClickSource())
.assignTimestampsAndWatermarks(
WatermarkStrategy.<Event>forMonotonousTimestamps()
.withTimestampAssigner(
new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event event, long l) {
return event.timestamp;
}
})
);
stream.keyBy(data -> data.url)
.process(new MyWindowKeyprocessFunction(10000L))
.print();
env.execute();
}
public static class MyWindowKeyprocessFunction extends KeyedProcessFunction<String,Event,String> {
private Long duration;
private MapState<Long,Long> windowState;
public MyWindowKeyprocessFunction (Long duration) {
this.duration = duration;
}
@Override
public void open(Configuration parameters) throws Exception {
windowState = getRuntimeContext().getMapState(new MapStateDescriptor<Long, Long>("windowState",Long.class,Long.class));
}
@Override
public void processElement(Event event, KeyedProcessFunction<String, Event, String>.Context context, Collector<String> collector) throws Exception {
System.out.println(event);
// 获取窗口起始时间
Long ts = event.timestamp;
long windowStart = ts / duration * duration;
long windowEnd = windowStart + duration;
// 判断并创建定时器
Long count = windowState.get(windowStart);
if(count == null) {
context.timerService().registerEventTimeTimer(windowEnd - 1);
windowState.put(windowStart,1L);
}else {
windowState.put(windowStart,count + 1);
}
}
@Override
public void onTimer(long timestamp, KeyedProcessFunction<String, Event, String>.OnTimerContext ctx, Collector<String> out) throws Exception {
long windowEnd = timestamp + 1;
long windowStart = windowEnd - duration;
System.out.println("窗口时间范围为:" + new Timestamp(windowStart) + " -> " + new Timestamp(windowEnd));
System.out.println(ctx.getCurrentKey() + " -> " + windowState.get(windowStart));
// 清除
windowState.remove(windowStart);
System.out.println("============================");
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
# 聚合状态(AggregatingState)
我们举一个简单的例子,对用户点击事件流每 5 个数据统计一次平均时间戳。这是一个类似计数窗口(CountWindow)求平均值的计算,这里我们可以使用一个有聚合状态的RichFlatMapFunction 来实现。
public class Demo_06_State_AverageTimestamp {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
SingleOutputStreamOperator<Event> stream = env.addSource(new Demo_03_Source_Customer.ClickSource())
.assignTimestampsAndWatermarks(
WatermarkStrategy.<Event>forMonotonousTimestamps()
.withTimestampAssigner(
new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event event, long l) {
return event.timestamp;
}
})
);
stream.keyBy(data -> data.user)
.flatMap(new RichFlatMapFunction<Event, String>() {
AggregatingState<Event,Tuple2<Long, Long>> state;
@Override
public void open(Configuration parameters) throws Exception {
state = getRuntimeContext().getAggregatingState(new AggregatingStateDescriptor<Event, Tuple2<Long,Long>, Tuple2<Long, Long>>(
"state",
new AggregateFunction<Event, Tuple2<Long, Long>, Tuple2<Long, Long>>() {
@Override
public Tuple2<Long, Long> createAccumulator() {
return Tuple2.of(0L, 0L);
}
@Override
public Tuple2<Long, Long> add(Event event, Tuple2<Long, Long> tuple) {
return Tuple2.of(tuple.f0 + event.timestamp , tuple.f1 + 1);
}
@Override
public Tuple2<Long, Long> getResult(Tuple2<Long, Long> tuple) {
return tuple;
}
@Override
public Tuple2<Long, Long> merge(Tuple2<Long, Long> longLongTuple2, Tuple2<Long, Long> acc1) {
return null;
}
},
Types.TUPLE(Types.LONG, Types.LONG)));
}
@Override
public void flatMap(Event event, Collector<String> collector) throws Exception {
System.out.println(event);
state.add(event);
Tuple2<Long, Long> tuple = state.get();
if(tuple.f1 == 5) {
collector.collect(event.user + " -> " + tuple.f0 / tuple.f1);
state.clear();
}
}
})
.print();
env.execute();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
# 状态生存时间(TTL)
在实际应用中,很多状态会随着时间的推移逐渐增长,如果不加以限制,最终就会导致存储空间的耗尽。一个优化的思路是直接在代码中调用.clear()方法去清除状态,但是有时候我们的逻辑要求不能直接清除。这时就需要配置一个状态的“生存时间”(time-to-live,TTL),当状态在内存中存在的时间超出这个值时,就将它清除。
具体实现上,如果用一个进程不停地扫描所有状态看是否过期,显然会占用大量资源做无用功。状态的失效其实不需要立即删除,所以我们可以给状态附加一个属性,也就是状态的“失效时间”。状态创建的时候,设置 失效时间 = 当前时间 + TTL;之后如果有对状态的访问和修改,我们可以再对失效时间进行更新;当设置的清除条件被触发时(比如,状态被访问的时候,或者每隔一段时间扫描一次失效状态),就可以判断状态是否失效、从而进行清除了。
配置状态的 TTL 时,需要创建一个 StateTtlConfig 配置对象,然后调用状态描述器的.enableTimeToLive()方法启动 TTL 功能。
StateTtlConfig ttlConfig = StateTtlConfig
.newBuilder(Time.seconds(10))
.setUpdateType(StateTtlConfig.UpdateType.OnCreateAndWrite)
.setStateVisibility(StateTtlConfig.StateVisibility.NeverReturnExpired)
.build();
ValueStateDescriptor<String> stateDescriptor = new ValueStateDescriptor<>("mystate", String.class);
stateDescriptor.enableTimeToLive(ttlConfig);
2
3
4
5
6
7
这里用到了几个配置项:
.newBuilder()
状态 TTL 配置的构造器方法,必须调用,返回一个 Builder 之后再调用.build()方法就可以得到 StateTtlConfig 了。方法需要传入一个 Time 作为参数,这就是设定的状态生存时间。
.setUpdateType()
设置更新类型。更新类型指定了什么时候更新状态失效时间,这里的 OnCreateAndWrite表示只有创建状态和更改状态(写操作)时更新失效时间。另一种类型 OnReadAndWrite 则表示无论读写操作都会更新失效时间,也就是只要对状态进行了访问,就表明它是活跃的,从而延长生存时间。这个配置默认为 OnCreateAndWrite。
.setStateVisibility()
设置状态的可见性。所谓的“状态可见性”,是指因为清除操作并不是实时的,所以当状态过期之后还有可能基于存在,这时如果对它进行访问,能否正常读取到就是一个问题了。这里设置的 NeverReturnExpired 是默认行为,表示从不返回过期值,也就是只要过期就认为它已经被清除了,应用不能继续读取;这在处理会话或者隐私数据时比较重要。对应的另一种配置是 ReturnExpireDefNotCleanedUp,就是如果过期状态还存在,就返回它的值。
除此之外,TTL 配置还可以设置在保存检查点(checkpoint)时触发清除操作,或者配置增量的清理(incremental cleanup),还可以针对 RocksDB 状态后端使用压缩过滤器(compaction filter)进行后台清理。关于检查点和状态后端的内容,我们会在后续章节继续讲解。
这里需要注意,目前的 TTL 设置只支持处理时间。另外,所有集合类型的状态(例如ListState、MapState)在设置 TTL 时,都是针对每一项(per-entry)元素的。也就是说,一个列表状态中的每一个元素,都会以自己的失效时间来进行清理,而不是整个列表一起清理。
# 算子状态(Operator State)
除按键分区状态(Keyed State)之外,另一大类受控状态就是算子状态(Operator State)。从某种意义上说,算子状态是更底层的状态类型,因为它只针对当前算子并行任务有效,不需要考虑不同 key 的隔离。算子状态功能不如按键分区状态丰富,应用场景较少,它的调用方法也会有一些区别。
# 基本概念和特点
算子状态(Operator State)就是一个算子并行实例上定义的状态,作用范围被限定为当前算子任务。算子状态跟数据的 key 无关,所以不同 key 的数据只要被分发到同一个并行子任务,就会访问到同一个 Operator State。
算子状态的实际应用场景不如 Keyed State 多,一般用在 Source 或 Sink 等与外部系统连接的算子上,或者完全没有 key 定义的场景。比如 Flink 的 Kafka 连接器中,就用到了算子状态。在我们给 Source 算子设置并行度后,Kafka 消费者的每一个并行实例,都会为对应的主题(topic)分区维护一个偏移量, 作为算子状态保存起来。这在保证 Flink 应用“精确一次”(exactly-once)状态一致性时非常有用。关于状态一致性的内容,我们会在第十章详细展开。
当算子的并行度发生变化时,算子状态也支持在并行的算子任务实例之间做重组分配。根据状态的类型不同,重组分配的方案也会不同。
# 状态类型
算子状态也支持不同的结构类型,主要有三种:ListState、UnionListState 和 BroadcastState。
# 列表状态(ListState)
与 Keyed State 中的 ListState 一样,将状态表示为一组数据的列表。
与 Keyed State 中的列表状态的区别是:在算子状态的上下文中,不会按键(key)分别处理状态,所以每一个并行子任务上只会保留一个“列表”(list),也就是当前并行子任务上所有状态项的集合。列表中的状态项就是可以重新分配的最细粒度,彼此之间完全独立。
当算子并行度进行缩放调整时,算子的列表状态中的所有元素项会被统一收集起来,相当于把多个分区的列表合并成了一个“大列表”,然后再均匀地分配给所有并行任务。这种“均匀分配”的具体方法就是“轮询”(round-robin),与之前介绍的 rebanlance 数据传输方式类似,是通过逐一“发牌”的方式将状态项平均分配的。这种方式也叫作“平均分割重组”(even-splitredistribution)。
算子状态中不会存在“键组”(key group)这样的结构,所以为了方便重组分配,就把它直接定义成了“列表”(list)。这也就解释了,为什么算子状态中没有最简单的值状态(ValueState)。
# 联合列表状态(UnionListState)
与 ListState 类似,联合列表状态也会将状态表示为一个列表。它与常规列表状态的区别在于,算子并行度进行缩放调整时对于状态的分配方式不同。
UnionListState 的重点就在于“联合”(union)。在并行度调整时,常规列表状态是轮询分配状态项,而联合列表状态的算子则会直接广播状态的完整列表。这样,并行度缩放之后的并行子任务就获取到了联合后完整的“大列表”,可以自行选择要使用的状态项和要丢弃的状态项。这种分配也叫作“联合重组”(union redistribution)。如果列表中状态项数量太多,为资源和效率考虑一般不建议使用联合重组的方式。
# 广播状态(BroadcastState)
有时我们希望算子并行子任务都保持同一份“全局”状态,用来做统一的配置和规则设定。这时所有分区的所有数据都会访问到同一个状态,状态就像被“广播”到所有分区一样,这种特殊的算子状态,就叫作广播状态(BroadcastState)。
因为广播状态在每个并行子任务上的实例都一样,所以在并行度调整的时候就比较简单,只要复制一份到新的并行任务就可以实现扩展;而对于并行度缩小的情况,可以将多余的并行子任务连同状态直接砍掉——因为状态都是复制出来的,并不会丢失。
在底层,广播状态是以类似映射结构(map)的键值对(key-value)来保存的,必须基于一个“广播流”(BroadcastStream)来创建。关于广播流,我们在第八章“广播连接流”的讲解中已经做过介绍,稍后还会在 9.4 节做一个总结。
# 代码实现
我们已经知道,状态从本质上来说就是算子并行子任务实例上的一个特殊本地变量。它的特殊之处就在于 Flink 会提供完整的管理机制,来保证它的持久化保存,以便发生故障时进行状态恢复;另外还可以针对不同的 key 保存独立的状态实例。按键分区状态(Keyed State)对这两个功能都要考虑;而算子状态(Operator State)并不考虑 key 的影响,所以主要任务就是要让 Flink 了解状态的信息、将状态数据持久化后保存到外部存储空间。
看起来算子状态的使用应该更加简单才对。不过仔细思考又会发现一个问题:我们对状态进行持久化保存的目的是为了故障恢复;在发生故障、重启应用后,数据还会被发往之前分配的分区吗?显然不是,因为并行度可能发生了调整,不论是按键(key)的哈希值分区,还是直接轮询(round-robin)分区,数据分配到的分区都会发生变化。这很好理解,当打牌的人数从 3 个增加到 4 个时,即使牌的次序不变,轮流发到每个人手里的牌也会不同。数据分区发生变化,带来的问题就是,怎么保证原先的状态跟故障恢复后数据的对应关系呢?
对于 Keyed State 这个问题很好解决:状态都是跟 key 相关的,而相同 key 的数据不管发往哪个分区,总是会全部进入一个分区的;于是只要将状态也按照 key的哈希值计算出对应的分区,进行重组分配就可以了。恢复状态后继续处理数据,就总能按照 key 找到对应之前的状态,就保证了结果的一致性。所以 Flink 对 Keyed State 进行了非常完善的包装,我们不需实现任何接口就可以直接使用。
而对于 Operator State 来说就会有所不同。因为不存在 key,所有数据发往哪个分区是不可预测的;也就是说,当发生故障重启之后,我们不能保证某个数据跟之前一样,进入到同一个并行子任务、访问同一个状态。所以 Flink 无法直接判断该怎样保存和恢复状态,而是提供了接口,让我们根据业务需求自行设计状态的快照保存(snapshot)和恢复(restore)逻辑。
# CheckpointedFunction 接口
在 Flink 中,对状态进行持久化保存的快照机制叫作“检查点”(Checkpoint)。于是使用算子状态时,就需要对检查点的相关操作进行定义,实现一个 CheckpointedFunction 接口。
CheckpointedFunction 接口在源码中定义如下:
public interface CheckpointedFunction {
// 保存状态快照到检查点时,调用这个方法
void snapshotState(FunctionSnapshotContext context) throws Exception
// 初始化状态时调用这个方法,也会在恢复状态时调用
void initializeState(FunctionInitializationContext context) throws Exception;
}
2
3
4
5
6
每次应用保存检查点做快照时,都会调用.snapshotState()方法,将状态进行外部持久化。而在算子任务进行初始化时,会调用. initializeState()方法。这又有两种情况:一种是整个应用第一次运行,这时状态会被初始化为一个默认值(default value);另一种是应用重启时,从检查点(checkpoint)或者保(savepoint)中读取之前状态的快照,并赋给本地状态。所以,接口中的.snapshotState()方法定义了检查点的快照保存逻辑,而. initializeState()方法不仅定义了初始化逻辑,也定义了恢复逻辑。
这里需要注意,CheckpointedFunction 接口中的两个方法,分别传入了一个上下文(context)作为参数。不同的是,.snapshotState()方法拿到的是快照的上下文 FunctionSnapshotContext,它可以提供检查点的相关信息,不过无法获取状态句柄;而. initializeState()方法拿到的是FunctionInitializationContext,这是函数类进行初始化时的上下文,是真正的“运行时上下文”。FunctionInitializationContext 中提供了“算子状态存储”(OperatorStateStore)和“按键分区状态存储” (KeyedStateStore),在这两个存储对象中可以非常方便地获取当前任务实例中的 OperatorState 和 Keyed State。例如:
ListStateDescriptor<String> descriptor =
new ListStateDescriptor<>(
"buffered-elements",
Types.of(String));
ListState<String> checkpointedState = context.getOperatorStateStore().getListState(descriptor);
2
3
4
5
我们看到,算子状态的注册和使用跟 Keyed State 非常类似,也是需要先定义一个状态描述器(StateDescriptor),告诉 Flink 当前状态的名称和类型,然后从上下文提供的算子状态存储(OperatorStateStore)中获取对应的状态对象。如果想要从 KeyedStateStore 中获取 Keyed State也是一样的,前提是必须基于定义了 key 的 KeyedStream,这和富函数类中的方式并不矛盾。通过这里的描述可以发现,CheckpointedFunction 是 Flink 中非常底层的接口,它为有状态的流处理提供了灵活且丰富的应用。
# 示例代码
接下来我们举一个算子状态的应用案例。在下面的例子中,自定义的 SinkFunction 会在CheckpointedFunction 中进行数据缓存,然后统一发送到下游。这个例子演示了列表状态的平均分割重组(event-split redistribution)。
public class Demo_07_State_BufferingSink {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
SingleOutputStreamOperator<Event> stream = env.addSource(new Demo_03_Source_Customer.ClickSource())
.assignTimestampsAndWatermarks(
WatermarkStrategy.<Event>forMonotonousTimestamps()
.withTimestampAssigner(
new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event event, long l) {
return event.timestamp;
}
})
);
stream.addSink(new MyBufferingSinkFunction());
env.execute();
}
public static class MyBufferingSinkFunction implements SinkFunction<Event>, CheckpointedFunction {
private transient ListState<Event> checkpointedState;
private List<Event> bufferedElements = new ArrayList<>();;
@Override
public void invoke(Event value, Context context) throws Exception {
bufferedElements.add(value);
if (bufferedElements.size() == 5) {
for (Event element: bufferedElements) {
// 输出到外部系统,这里用控制台打印模拟
System.out.println(element);
}
System.out.println("==========输出完毕=========");
bufferedElements.clear();
}
}
@Override
public void snapshotState(FunctionSnapshotContext functionSnapshotContext) throws Exception {
checkpointedState.clear();
// 把当前局部变量中的所有元素写入到检查点中
for (Event element : bufferedElements) {
checkpointedState.add(element);
}
}
@Override
public void initializeState(FunctionInitializationContext context) throws Exception {
ListStateDescriptor<Event> descriptor = new ListStateDescriptor<>(
"buffered-elements",
Types.POJO(Event.class));
checkpointedState = context.getOperatorStateStore().getListState(descriptor);
// 如果是从故障中恢复,就将 ListState 中的所有元素添加到局部变量中
if (context.isRestored()) {
for (Event element : checkpointedState.get()) {
bufferedElements.add(element);
}
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
当初始化好状态对象后,我们可以通过调用. isRestored()方法判断是否是从故障中恢复。在代码中 BufferingSink 初始化时,恢复出的 ListState 的所有元素会添加到一个局部变量bufferedElements 中,以后进行检查点快照时就可以直接使用了。在调用.snapshotState()时,直接清空 ListState,然后把当前局部变量中的所有元素写入到检查点中。
对于不同类型的算子状态,需要调用不同的获取状态对象的接口,对应地也就会使用不同的状态分配重组算法。比如获取列表状态时,调用.getListState() 会使用最简单的 平均分割重组(even-split redistribution)算法;而获取联合列表状态时,调用的是.getUnionListState() ,对应就会使用联合重组(union redistribution) 算法。
# 广播状态(Broadcast State)
算子状态中有一类很特殊,就是广播状态(Broadcast State)。从概念和原理上讲,广播状态非常容易理解:状态广播出去,所有并行子任务的状态都是相同的;并行度调整时只要直接复制就可以了。然而在应用上,广播状态却与其他算子状态大不相同。本节我们就专门来讨论一下广播状态的使用。
# 基本用法
让所有并行子任务都持有同一份状态,也就意味着一旦状态有变化,所以子任务上的实例都要更新。什么时候会用到这样的广播状态呢?
一个最为普遍的应用,就是“动态配置”或者“动态规则”。我们在处理流数据时,有时会基于一些配置(configuration)或者规则(rule)。简单的配置当然可以直接读取配置文件,一次加载,永久有效;但数据流是连续不断的,如果这配置随着时间推移还会动态变化,那又该怎么办呢?
一个简单的想法是,定期扫描配置文件,发现改变就立即更新。但这样就需要另外启动一个扫描进程,如果扫描周期太长,配置更新不及时就会导致结果错误;如果扫描周期太短,又会耗费大量资源做无用功。解决的办法,还是流处理的“事件驱动”思路——我们可以将这动态的配置数据看作一条流,将这条流和本身要处理的数据流进行连接(connect),就可以实时地更新配置进行计算了。
由于配置或者规则数据是全局有效的,我们需要把它广播给所有的并行子任务。而子任务需要把它作为一个算子状态保存起来,以保证故障恢复后处理结果是一致的。这时的状态,就是一个典型的广播状态。我们知道,广播状态与其他算子状态的列表(list)结构不同,底层是以键值对(key-value)形式描述的,所以其实就是一个映射状态(MapState)。
在代码上,可以直接调用 DataStream 的.broadcast()方法,传入一个“映射状态描述器”(MapStateDescriptor)说明状态的名称和类型,就可以得到一个“广播流”(BroadcastStream);进而将要处理的数据流与这条广播流进行连接(connect),就会得到“广播连接流”(BroadcastConnectedStream)。注意广播状态只能用在广播连接流中。
MapStateDescriptor<String, Rule> ruleStateDescriptor = newMapStateDescriptor<>(...);
BroadcastStream<Rule> ruleBroadcastStream = ruleStream.broadcast(ruleStateDescriptor);
DataStream<String> output = stream.connect(ruleBroadcastStream).process( new BroadcastProcessFunction<>() {...} );
2
3
这里我们定义了一个“规则流”ruleStream,里面的数据表示了数据流 stream 处理的规则,规则的数据类型定义为 Rule。于是需要先定义一个 MapStateDescriptor 来描述广播状态,然后传入 ruleStream.broadcast()得到广播流,接着用 stream 和广播流进行连接。这里状态描述器中的 key 类型为 String,就是为了区分不同的状态值而给定的 key 的名称。
对 于 广 播 连 接 流 调 用 .process() 方 法 , 可 以 传 入 “ 广 播 处 理 函 数 ”KeyedBroadcastProcessFunction 或者 BroadcastProcessFunction 来进行处理计算。广播处理函数里面有两个方法.processElement()和.processBroadcastElement(),源码中定义如下:
public abstract class BroadcastProcessFunction<IN1, IN2, OUT> extends BaseBroadcastProcessFunction {
...
public abstract void processElement(IN1 value, ReadOnlyContext ctx,Collector<OUT> out) throws Exception;
public abstract void processBroadcastElement(IN2 value, Context ctx,Collector<OUT> out) throws Exception;
...
}
2
3
4
5
6
这里的.processElement()方法,处理的是正常数据流,第一个参数 value 就是当前到来的流数据;而.processBroadcastElement()方法就相当于是用来处理广播流的,它的第一个参数 value就是广播流中的规则或者配置数据。两个方法第二个参数都是一个上下文 ctx,都可以通过调用.getBroadcastState()方法获取到当前的广播状态;区别在于,.processElement()方法里的上下文 是 “ 只 读 ” 的 ( ReadOnly ), 因 此 获 取 到 的 广 播 状 态 也 只 能 读 取 不 能 更 改 ; 而.processBroadcastElement()方法里的 Context 则没有限制,可以根据当前广播流中的数据更新状态。
Rule rule = ctx.getBroadcastState( new MapStateDescriptor<>("rules", Types.String,Types.POJO(Rule.class))).get("my rule");
通过调用 ctx.getBroadcastState()方法,传入一个 MapStateDescriptor,就可以得到当前的叫作“rules”的广播状态;调用它的.get()方法,就可以取出其中“my rule”对应的值进行计算处理。
# 代码实例
接下来我们举一个广播状态的应用案例。考虑在电商应用中,往往需要判断用户先后发生的行为的“组合模式”,比如“登录-下单”或者“登录-支付”,检测出这些连续的行为进行统计,就可以了解平台的运用状况以及用户的行为习惯。具体代码如下:
public class Demo_08_State_BehaviorPatternDetect {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 读取用户行为事件流
DataStreamSource<Action> actionStream = env.fromElements(
new Action("Alice", "login"),
new Action("Alice", "pay")
);
// 定义行为模式流,代表了要检测的标准
DataStreamSource<Pattern> patternStream = env.fromElements(
new Pattern("login", "pay"),
new Pattern("login", "buy")
);
// 定义广播状态的描述器,创建广播流
MapStateDescriptor<Void, Pattern> bcStateDescriptor = new MapStateDescriptor("patternStream", Types.VOID, Types.POJO(Pattern.class));
BroadcastStream<Pattern> broadcastStream = patternStream.broadcast(bcStateDescriptor);
actionStream.keyBy(data -> data.user)
.connect(broadcastStream)
.process(new KeyedBroadcastProcessFunction<String,Action, Pattern, Tuple2<String, Pattern>>() {
// 保存上一个状态
ValueState<String> perActionState;
@Override
public void processElement(Action action, KeyedBroadcastProcessFunction<String, Action, Pattern, Tuple2<String, Pattern>>.ReadOnlyContext readOnlyContext, Collector<Tuple2<String, Pattern>> collector) throws Exception {
ReadOnlyBroadcastState<Void,Pattern> patternState = readOnlyContext.getBroadcastState(new MapStateDescriptor("patternStream", Types.VOID, Types.POJO(Pattern.class)));
Pattern pattern = patternState.get(null);
String perAction = perActionState.value();
if(null != perAction && pattern != null) {
if(pattern.pattern1.equals(perAction) && pattern.pattern2.equals(action.action)) {
collector.collect(new Tuple2<>(readOnlyContext.getCurrentKey(),pattern));
}
}
perActionState.update(action.action);
}
@Override
public void processBroadcastElement(Pattern pattern, KeyedBroadcastProcessFunction<String, Action, Pattern, Tuple2<String, Pattern>>.Context context, Collector<Tuple2<String, Pattern>> collector) throws Exception {
// 更新广播数据
BroadcastState<Void,Pattern> state = context.getBroadcastState(new MapStateDescriptor("patternStream", Types.VOID, Types.POJO(Pattern.class)));
state.put(null,pattern);
}
@Override
public void open(Configuration parameters) throws Exception {
perActionState = getRuntimeContext().getState(new ValueStateDescriptor<String>("peractionstate",String.class));
}
}).print();
env.execute();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
# 状态持久化和状态后端
在 Flink 的状态管理机制中,很重要的一个功能就是对状态进行持久化(persistence)保存,这样就可以在发生故障后进行重启恢复。Flink 对状态进行持久化的方式,就是将当前所有分布式状态进行“快照”保存,写入一个“检查点”(checkpoint)或者保存点(savepoint)保存到外部存储系统中。具体的存储介质,一般是分布式文件系统(distributed file system)。
# 检查点(Checkpoint)
有状态流应用中的检查点(checkpoint),其实就是所有任务的状态在某个时间点的一个快照(一份拷贝)。简单来讲,就是一次“存盘”,让我们之前处理数据的进度不要丢掉。在一个流应用程序运行时,Flink 会定期保存检查点,在检查点中会记录每个算子的 id 和状态;如果发生故障,Flink 就会用最近一次成功保存的检查点来恢复应用的状态,重新启动处理流程,就如同“读档”一样。
如果保存检查点之后又处理了一些数据,然后发生了故障,那么重启恢复状态之后这些数据带来的状态改变会丢失。为了让最终处理结果正确,我们还需要让源(Source)算子重新读取这些数据,再次处理一遍。这就需要流的数据源具有“数据重放”的能力,一个典型的例子就是 Kafka,我们可以通过保存消费数据的偏移量、故障重启后重新提交来实现数据的重放。这是对“至少一次”(at least once)状态一致性的保证,如果希望实现“精确一次”(exactly once)的一致性,还需要数据写入外部系统时的相关保证。关于这部分内容我们会在第 10 章继续讨论。
默认情况下,检查点是被禁用的,需要在代码中手动开启。直接调用执行环境的.enableCheckpointing()方法就可以开启检查点。
StreamExecutionEnvironment env = StreamExecutionEnvironment.getEnvironment();
env.enableCheckpointing(1000);
2
这里传入的参数是检查点的间隔时间,单位为毫秒。关于检查点的详细配置,可以参考第10 章的内容。
除了检查点之外,Flink 还提供了“保存点”(savepoint)的功能。保存点在原理和形式上跟检查点完全一样,也是状态持久化保存的一个快照;区别在于,保存点是自定义的镜像保存,所以不会由 Flink 自动创建,而需要用户手动触发。这在有计划地停止、重启应用时非常有用。
# 状态后端(State Backends)
检查点的保存离不开 JobManager 和 TaskManager,以及外部存储系统的协调。在应用进行检查点保存时,首先会由 JobManager 向所有 TaskManager 发出触发检查点的命令;TaskManger 收到之后,将当前任务的所有状态进行快照保存,持久化到远程的存储介质中;完成之后向 JobManager 返回确认信息。这个过程是分布式的,当 JobManger 收到所有TaskManager 的返回信息后,就会确认当前检查点成功保存,如图 9-5 所示。而这一切工作的协调,就需要一个“专职人员”来完成。

在 Flink 中,状态的存储、访问以及维护,都是由一个可插拔的组件决定的,这个组件就叫作状态后端(state backend)。状态后端主要负责两件事:一是本地的状态管理,二是将检查点(checkpoint)写入远程的持久化存储。
# 状态后端的分类
状态后端是一个“开箱即用”的组件,可以在不改变应用程序逻辑的情况下独立配置。Flink 中提供了两类不同的状态后端,一种是“哈希表状态后端”(HashMapStateBackend),另一种是“内嵌 RocksDB 状态后端”(EmbeddedRocksDBStateBackend)。如果没有特别配置,系统默认的状态后端是 HashMapStateBackend。
哈希表状态后端(HashMapStateBackend)
这种方式就是我们之前所说的,把状态存放在内存里。具体实现上,哈希表状态后端在内部会直接把状态当作对象(objects),保存在 Taskmanager 的 JVM 堆(heap)上。普通的状态,以及窗口中收集的数据和触发器(triggers),都会以键值对(key-value)的形式存储起来,所以底层是一个哈希表(HashMap),这种状态后端也因此得名。
对于检查点的保存,一般是放在持久化的分布式文件系统(file system)中,也可以通过配置“检查点存储”(CheckpointStorage)来另外指定。
HashMapStateBackend 是将本地状态全部放入内存的,这样可以获得最快的读写速度,使计算性能达到最佳;代价则是内存的占用。它适用于具有大状态、长窗口、大键值状态的作业,对所有高可用性设置也是有效的。
内嵌 RocksDB 状态后端(EmbeddedRocksDBStateBackend)
RocksDB 是一种内嵌的 key-value 存储介质,可以把数据持久化到本地硬盘。配置EmbeddedRocksDBStateBackend 后,会将处理中的数据全部放入 RocksDB 数据库中,RocksDB默认存储在 TaskManager 的本地数据目录里。
与 HashMapStateBackend 直接在堆内存中存储对象不同,这种方式下状态主要是放在RocksDB 中的。数据被存储为序列化的字节数组(Byte Arrays),读写操作需要序列化/反序列化,因此状态的访问性能要差一些。另外,因为做了序列化,key 的比较也会按照字节进行,而不是直接调用.hashCode()和.equals()方法。
对于检查点,同样会写入到远程的持久化文件系统中。
EmbeddedRocksDBStateBackend 始终执行的是异步快照,也就是不会因为保存检查点而阻塞数据的处理;而且它还提供了增量式保存检查点的机制,这在很多情况下可以大大提升保存效率。
由于它会把状态数据落盘,而且支持增量化的检查点,所以在状态非常大、窗口非常长、键/值状态很大的应用场景中是一个好选择,同样对所有高可用性设置有效。
# 如何选择正确的状态后端
HashMap 和 RocksDB 两种状态后端最大的区别,就在于本地状态存放在哪里:前者是内存,后者是 RocksDB。在实际应用中,选择那种状态后端,主要是需要根据业务需求在处理性能和应用的扩展性上做一个选择。
HashMapStateBackend 是内存计算,读写速度非常快;但是,状态的大小会受到集群可用内存的限制,如果应用的状态随着时间不停地增长,就会耗尽内存资源。
而 RocksDB 是硬盘存储,所以可以根据可用的磁盘空间进行扩展,而且是唯一支持增量检查点的状态后端,所以它非常适合于超级海量状态的存储。不过由于每个状态的读写都需要做序列化/反序列化,而且可能需要直接从磁盘读取数据,这就会导致性能的降低,平均读写性能要比 HashMapStateBackend 慢一个数量级。
我们可以发现,实际应用就是权衡利弊后的取舍。最理想的当然是处理速度快且内存不受限制可以处理海量状态,那就需要非常大的内存资源了,这会导致成本超出项目预算。比起花更多的钱,稍慢的处理速度或者稍小的处理规模,老板可能更容易接受一点。
# 状态后端的配置
在不做配置的时候,应用程序使用的默认状态后端是由集群配置文件 flink-conf.yaml 中指定的,配置的键名称为 state.backend。这个默认配置对集群上运行的所有作业都有效,我们可以通过更改配置值来改变默认的状态后端。另外,我们还可以在代码中为当前作业单独配置状态后端,这个配置会覆盖掉集群配置文件的默认值。
配置默认的状态后端
在 flink-conf.yaml 中,可以使用 state.backend 来配置默认状态后端。
配置项的可能值为 hashmap,这样配置的就是 HashMapStateBackend;也可以是 rocksdb,这样配置的就是 EmbeddedRocksDBStateBackend。另外,也可以是一个实现了状态后端工厂StateBackendFactory 的类的完全限定类名。
配置项的可能值为 hashmap,这样配置的就是 HashMapStateBackend;也可以是 rocksdb,这样配置的就是 EmbeddedRocksDBStateBackend。另外,也可以是一个实现了状态后端工厂StateBackendFactory 的类的完全限定类名。
下面是一个配置 HashMapStateBackend 的例子:
# 默认状态后端 state.backend: hashmap # 存放检查点的文件路径 state.checkpoints.dir: hdfs://namenode:40010/flink/checkpoints1
2
3
4这里的 state.checkpoints.dir 配置项,定义了状态后端将检查点和元数据写入的目录。
为每个作业(Per-job)单独配置状态后端
每个作业独立的状态后端,可以在代码中,基于作业的执行环境直接设置。代码如下:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setStateBackend(new HashMapStateBackend());1
2上面代码设置的是 HashMapStateBackend,如果想要设置 EmbeddedRocksDBStateBackend,可以用下面的配置方式:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setStateBackend(new EmbeddedRocksDBStateBackend());1
2需要注意,如果想在 IDE 中使用 EmbeddedRocksDBStateBackend,需要为 Flink 项目添加依赖:
<dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-statebackend-rocksdb_${scala.binary.version}</artifactId> <version>1.13.0</version> </dependency>1
2
3
4
5而由于 Flink 发行版中默认就包含了 RocksDB,所以只要我们的代码中没有使用 RocksDB的相关内容,就不需要引入这个依赖。即使我们在 flink-conf.yaml 配置文件中设定了state.backend 为 rocksdb,也可以直接正常运行,并且使用 RocksDB 作为状态后端。
# 本章总结
有状态的流处理是 Flink 的本质,所以状态可以说是 Flink 中最为重要的概念。之前聚合算子、窗口算子中已经提到了状态的概念,而通过本章的学习,我们对整个 Flink 的状态管理机制和状态编程的方式都有了非常详尽的了解。
本章从状态的概念和分类出发,详细介绍了 Flink 中的按键分区状态(Keyed State)和算子状态(Operator State)的特点和用法,并对广播状态(Broadcast State)做了进一步的展开说明。最后,我们还介绍了状态的持久化和状态后端,引出了检查点(checkpoint)的概念。检查点是一个非常重要的概念,是 Flink 容错机制的核心,我们将在下一章继续进行详细的讨论。
# 容错机制
流式数据连续不断地到来,无休无止;所以流处理程序也是持续运行的,并没有一个明确的结束退出时间。机器运行程序,996 起来当然比人要容易得多,不过希望“永远运行”也是不切实际的。因为各种硬件软件的原因,运行一段时间后程序可能异常退出、机器可能宕机,如果我们只依赖一台机器来运行,就会使得任务的处理被迫中断。
一个解决方案就是多台机器组成集群,以“分布式架构”来运行程序。这样不仅扩展了系统的并行处理能力,而且可以解决单点故障的问题,从而大大提高系统的稳定性和可用性。
在分布式架构中,当某个节点出现故障,其他节点基本不受影响。这时只需要重启应用,恢复之前某个时间点的状态继续处理就可以了。这一切看似简单,可是在实时流处理中,我们不仅需要保证故障后能够重启继续运行,还要保证结果的正确性、故障恢复的速度、对处理性能的影响,这就需要在架构上做出更加精巧的设计。
在 Flink 中,有一套完整的容错机制(fault tolerance)来保证故障后的恢复,其中最重要的就是检查点(checkpoint)。在第九章中,我们已经介绍过检查点的基本概念和用途,接下来我们就深入探讨一下检查点的原理和 Flink 的容错机制。
# 检查点(Checkpoint)
发生故障之后怎么办?最简单的想法当然是重启机器、重启应用。由于是分布式的集群,即使一个节点无法恢复,也不会影响应用的重启执行。这里的问题在于,流处理应用中的任务都是有状态的,而为了快速访问这些状态一般会直接放在堆内存里;现在重启应用,内存中的状态已经丢失,就意味着之前的计算全部白费了,需要从头来过。就像编写文档或是玩 RPG游戏,因为宕机没保存而要重来一遍是一件令人崩溃的事情;这种惨痛的经历让我们养成了一个好习惯——随时存档,这样即使遇到宕机也可以读档继续了,如图 10-1 所示。

在流处理中,我们同样可以用存档读档的思路,把之前的计算结果做个保存,这样重启之后就可以继续处理新数据、而不需要重新计算了。进一步地,我们知道在有状态的流处理中,任务继续处理新数据,并不需要“之前的计算结果”,而是需要任务“之前的状态”。所以我们最终的选择,就是将之前某个时间点所有的状态保存下来,这份“存档”就是所谓的“检查点”(checkpoint)。
遇到故障重启的时候,我们可以从检查点中“读档”,恢复出之前的状态,这样就可以回到当时保存的一刻接着处理数据了。
检查点是 Flink 容错机制的核心。这里所谓的“检查”,其实是针对故障恢复的结果而言的:故障恢复之后继续处理的结果,应该与发生故障前完全一致,我们需要“检查”结果的正确性。所以,有时又会把 checkpoint 叫作“一致性检查点”。
# 检查点的保存
什么时候进行检查点的保存呢?最理想的情况下,我们应该“随时”保存,也就是每处理完一个数据就保存一下当前的状态;这样如果在处理某条数据时出现故障,我们只要回到上一个数据处理完之后的状态,然后重新处理一遍这条数据就可以。这样重复处理的数据最少,完全没有多余操作,可以做到最低的延迟。然而实际情况不会这么完美。
# 周期性的触发保存
“随时存档”确实恢复起来方便,可是需要我们不停地做存档操作。如果每处理一条数据就进行检查点的保存,当大量数据同时到来时,就会耗费很多资源来频繁做检查点,数据处理的速度就会受到影响。所以更好的方式是,每隔一段时间去做一次存档,这样既不会影响数据的正常处理,也不会有太大的延迟——毕竟故障恢复的情况不是随时发生的。在 Flink 中,检查点的保存是周期性触发的,间隔时间可以进行设置。
所以检查点作为应用状态的一份“存档”,其实就是所有任务状态在同一时间点的一个“快照”(snapshot),它的触发是周期性的。具体来说,当每隔一段时间检查点保存操作被触发时,就把每个任务当前的状态复制一份,按照一定的逻辑结构放在一起持久化保存起来,就构成了检查点。
# 保存的时间点
这里有一个关键问题:当检查点的保存被触发时,任务有可能正在处理某个数据,这时该怎么办呢?
最简单的想法是,可以在某个时刻“按下暂停键”,让所有任务停止处理数据。这样状态就不再更改,大家可以一起复制保存;保存完毕之后,再同时恢复数据处理就可以了。
然而仔细思考就会发现这有很多问题。这种想法其实是粗暴地“停止一切来拍照”,在保存检查点的过程中,任务完全中断了,这会造成很大的延迟;我们之前为了实时性做出的所有设计就毁在了做快照上。另一方面,我们做快照的目的是为了故障恢复;现在的快照中,有些任务正在处理数据,那它保存的到底是处理到什么程度的状态呢?举个例子,我们在程序中某一步操作中自定义了一个 ValueState,处理的逻辑是:当遇到一个数据时,状态先加 1;而后经过一些其他步骤后再加 1。现在停止处理数据,状态到底是被加了 1 还是加了 2 呢?这很重要,因为状态恢复之后,我们需要知道当前数据从哪里开始继续处理。要满足这个要求,就必 须将暂停时的所有环境信息都保存下来——而这显然是很麻烦的。
为了解决这个问题,我们不应该“一刀切”把所有任务同时停掉,而是至少得先把手头正在处理的数据弄完。这样的话,我们在检查点中就不需要保存所有上下文信息,只要知道当前处理到哪个数据就可以了。
但这样依然会有问题:分布式系统的节点之间需要通过网络通信来传递数据,如果我们保存检查点的时候刚好有数据在网络传输的路上,那么下游任务是没法将数据保存起来的;故障重启之后,我们只能期待上游任务重新发送这个数据。然而上游任务是无法知道下游任务是否收到数据的,只能盲目地重发,这可能导致下游将数据处理两次,结果就会出现错误。
所以我们最终的选择是:当所有任务都恰好处理完一个相同的输入数据的时候,将它们的状态保存下来。首先,这样避免了除状态之外其他额外信息的存储,提高了检查点保存的效率。其次,一个数据要么就是被所有任务完整地处理完,状态得到了保存;要么就是没处理完,状态全部没保存:这就相当于构建了一个“事务”(transaction)。如果出现故障,我们恢复到之前保存的状态,故障时正在处理的所有数据都需要重新处理;所以我们只需要让源(source)任务向数据源重新提交偏移量、请求重放数据就可以了。这需要源任务可以把偏移量作为算子状态保存下来,而且外部数据源能够重置偏移量;Kafka 就是满足这些要求的一个最好的例子,我们会在后面详细讨论。
# 保存的具体流程
检查点的保存,最关键的就是要等所有任务将“同一个数据”处理完毕。下面我们通过一个具体的例子,来详细描述一下检查点具体的保存过程。
回忆一下我们最初实现的统计词频的程序——WordCount。这里为了方便,我们直接从数据源读入已经分开的一个个单词,例如这里输入的就是:
“hello”“world”“hello”“flink”“hello”“world”“hello”“flink”……
对应的代码就可以简化为:
SingleOutputStreamOperator<Tuple2<String, Long>> wordCountStream =
env.addSource(...)
.map(word -> Tuple2.of(word, 1L))
.returns(Types.TUPLE(Types.STRING, Types.LONG));
.keyBy(t -> t.f0);
.sum(1);
2
3
4
5
6
源(Source)任务从外部数据源读取数据,并记录当前的偏移量,作为算子状态(OperatorState)保存下来。然后将数据发给下游的 Map 任务,它会将一个单词转换成(word, count)二元组,初始 count 都是 1,也就是(“hello”, 1)、(“world”, 1)这样的形式;这是一个无状态的算子任务。进而以 word 作为键(key)进行分区,调用.sum()方法就可以对 count 值进行求和统计了;Sum 算子会把当前求和的结果作为按键分区状态(Keyed State)保存下来。最后得到的就是当前单词的频次统计(word, count),如图 10-2 所示。
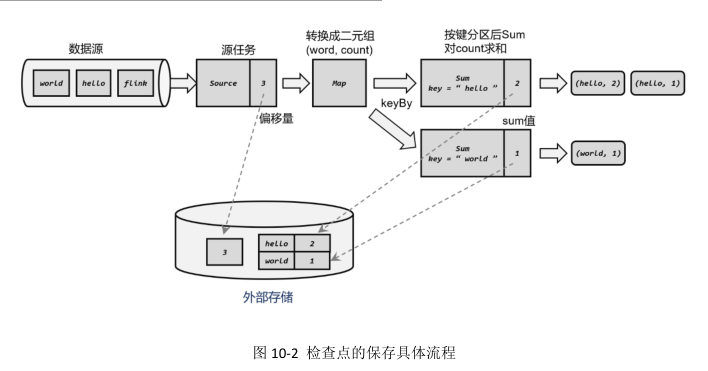
当我们需要保存检查点(checkpoint)时,就是在所有任务处理完同一条数据后,对状态做个快照保存下来。例如上图中,已经处理了 3 条数据:“hello”“world”“hello”,所以我们会看到 Source 算子的偏移量为 3;后面的 Sum 算子处理完第三条数据“hello”之后,此时已经有 2 个“hello”和 1 个“world”,所以对应的状态为“hello”-> 2, “world”-> 1(这里 KeyedState底层会以 key-value 形式存储)。此时所有任务都已经处理完了前三个数据,所以我们可以把当 前的状态保存成一个检查点,写入外部存储中。至于具体保存到哪里,这是由状态后端的配置项 “ 检 查 点 存 储 ”( CheckpointStorage ) 来 决 定 的 , 可 以 有 作 业 管 理 器 的 堆 内 存(JobManagerCheckpointStorage)和文件系统(FileSystemCheckpointStorage)两种选择。一般情况下,我们会将检查点写入持久化的分布式文件系统。
# 从检查点恢复状态
在运行流处理程序时,Flink 会周期性地保存检查点。当发生故障时,就需要找到最近一次成功保存的检查点来恢复状态。
例如在上节的 word count 示例中,我们处理完三个数据后保存了一个检查点。之后继续运行,又正常处理了一个数据“flink”,在处理第五个数据“hello”时发生了故障,如图 10-3所示。

这里 Source 任务已经处理完毕,所以偏移量为 5;Map 任务也处理完成了。而 Sum 任务在处理中发生了故障,此时状态并未保存。
接下来就需要从检查点来恢复状态了。具体的步骤为:
重启应用
遇到故障之后,第一步当然就是重启。我们将应用重新启动后,所有任务的状态会清空,如图 10-4 所示。
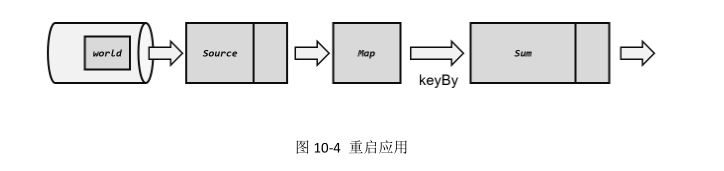
读取检查点,重置状态
找到最近一次保存的检查点,从中读出每个算子任务状态的快照,分别填充到对应的状态中。这样,Flink 内部所有任务的状态,就恢复到了保存检查点的那一时刻,也就是刚好处理完第三个数据的时候,如图 10-5 所示。这里 key 为“flink”并没有数据到来,所以初始为 0。

重放数据
从检查点恢复状态后还有一个问题:如果直接继续处理数据,那么保存检查点之后、到发生故障这段时间内的数据,也就是第 4、5 个数据(“flink”“hello”)就相当于丢掉了;这会造成计算结果的错误
为了不丢数据,我们应该从保存检查点后开始重新读取数据,这可以通过 Source 任务向外部数据源重新提交偏移量(offset)来实现,如图 10-6 所示。

继续处理数据
接下来,我们就可以正常处理数据了。首先是重放第 4、5 个数据,然后继续读取后面的数据,如图 10-7 所示。
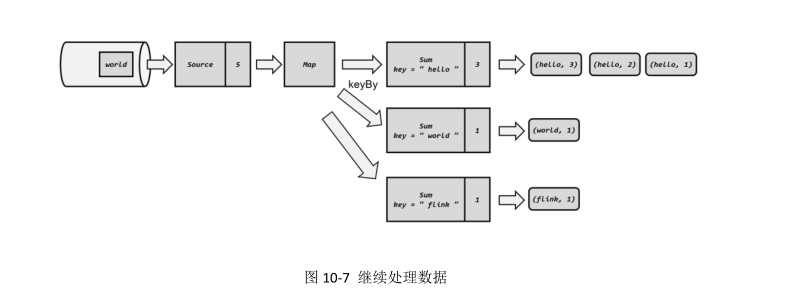
当处理到第 5 个数据时,就已经追上了发生故障时的系统状态。之后继续处理,就好像没有发生过故障一样;我们既没有丢掉数据也没有重复计算数据,这就保证了计算结果的正确性。在分布式系统中,这叫作实现了“精确一次”(exactly-once)的状态一致性保证。关于状态一致性的概念,我们会在本章后面的 10.2 节继续展开。
这里我们也可以发现,想要正确地从检查点中读取并恢复状态,必须知道每个算子任务状态的类型和它们的先后顺序(拓扑结构);因此为了可以从之前的检查点中恢复状态,我们在改动程序、修复 bug 时要保证状态的拓扑顺序和类型不变。状态的拓扑结构在 JobManager 上可以由 JobGraph 分析得到,而检查点保存的定期触发也是由 JobManager 控制的;所以故障恢复的过程需要 JobManager 的参与。
# 检查点算法
我们已经知道,Flink 保存检查点的时间点,是所有任务都处理完同一个输入数据的时候。但是不同的任务处理数据的速度不同,当第一个 Source 任务处理到某个数据时,后面的 Sum任务可能还在处理之前的数据;而且数据经过任务处理之后类型和值都会发生变化,面对着“面目全非”的数据,不同的任务怎么知道处理的是“同一个”呢?
一个简单的想法是,当接到 JobManager 发出的保存检查点的指令后,Source 算子任务处理完当前数据就暂停等待,不再读取新的数据了。这样我们就可以保证在流中只有需要保存到检查点的数据,只要把它们全部处理完,就可以保证所有任务刚好处理完最后一个数据;这时把所有状态保存起来,合并之后就是一个检查点了。这就好比我们想要保存所有同学刚好毕业时的状态,那就在所有人答辩完成之后,集合起来拍一张毕业合照。这样做最大的问题,就是每个人的进度可能不同;先答辩完的人为了保证状态一致不能进行其他工作,只能等待。当先保存完状态的任务需要等待其他任务时,就导致了资源的闲置和性能的降低。
所以更好的做法是,在不暂停整体流处理的前提下,将状态备份保存到检查点。在 Flink中,采用了基于 Chandy-Lamport 算法的分布式快照,下面我们就来详细了解一下。
# 检查点分界线(Barrier)
我们现在的目标是,在不暂停流处理的前提下,让每个任务“认出”触发检查点保存的那个数据。
自然想到,如果给数据添加一个特殊标识,任务就可以准确识别并开始保存状态了。这需要在 Source 任务收到触发检查点保存的指令后,立即在当前处理的数据中插入一个标识字段,然后再向下游任务发出。但是假如 Source 任务此时并没有正在处理的数据,这个操作就无法实现了。
所以我们可以借鉴水位线(watermark)的设计,在数据流中插入一个特殊的数据结构,专门用来表示触发检查点保存的时间点。收到保存检查点的指令后,Source 任务可以在当前数据流中插入这个结构;之后的所有任务只要遇到它就开始对状态做持久化快照保存。由于数据流是保持顺序依次处理的,因此遇到这个标识就代表之前的数据都处理完了,可以保存一个检查点;而在它之后的数据,引起的状态改变就不会体现在这个检查点中,而需要保存到下一个检查点。
这种特殊的数据形式,把一条流上的数据按照不同的检查点分隔开,所以就叫作检查点的“分界线”(Checkpoint Barrier)。
与水位线很类似,检查点分界线也是一条特殊的数据,由 Source 算子注入到常规的数据流中,它的位置是限定好的,不能超过其他数据,也不能被后面的数据超过。检查点分界线中带有一个检查点 ID,这是当前要保存的检查点的唯一标识,如图 10-8 所示。
这样,分界线就将一条流逻辑上分成了两部分:分界线之前到来的数据导致的状态更改,都会被包含在当前分界线所表示的检查点中;而基于分界线之后的数据导致的状态更改,则会被包含在之后的检查点中。s

在 JobManager 中有一个“检查点协调器”(checkpoint coordinator),专门用来协调处理检查点的相关工作。检查点协调器会定期向 TaskManager 发出指令,要求保存检查点(带着检查点 ID);TaskManager 会让所有的 Source 任务把自己的偏移量(算子状态)保存起来,并将带有检查点 ID 的分界线(barrier)插入到当前的数据流中,然后像正常的数据一样像下游传递;之后 Source 任务就可以继续读入新的数据了。
每个算子任务只要处理到这个 barrier,就把当前的状态进行快照;在收到 barrier 之前,还是正常地处理之前的数据,完全不受影响。比如上图中,Source 任务收到 1 号检查点保存指令时,读取完了三个数据,所以将偏移量 3 保存到外部存储中;而后将 ID 为 1 的 barrier 注入数据流;与此同时,Map 任务刚刚收到上一条数据“hello”,而 Sum 任务则还在处理之前的第二条数据(world, 1)。下游任务不会在这时就立刻保存状态,而是等收到 barrier 时才去做快照,这时可以保证前三个数据都已经处理完了。同样地,下游任务做状态快照时,也不会影响上游任务的处理,每个任务的快照保存并行不悖,不会有暂停等待的时间。
如果还是拿拍毕业照来类比的话,现在就不需要大家答辩完之后聚在一起排队摆 pose 了——每个人完成答辩之后只要单独照张相,就可以继续做自己的事情去了;最后由班主任老师发挥 P 图技能合成合照,这样无疑就省去了大家集合等待的时间。
# 分布式快照算法
通过在流中插入分界线(barrier),我们可以明确地指示触发检查点保存的时间。在一条单一的流上,数据依次进行处理,顺序保持不变;不过对于分布式流处理来说,想要一直保持数据的顺序就不是那么容易了。
我们先回忆一下水位线(watermark)的处理:上游任务向多个并行下游任务传递时,需要广播出去;而多个上游任务向同一个下游任务传递时,则需要下游任务为每个上游并行任务维护一个“分区水位线”,取其中最小的那个作为当前任务的事件时钟。
那 barier 在并行数据流中的传递,是不是也有类似的规则呢?
watermark 指示的是“之前的数据全部到齐了”,而 barrier 指示的是“之前所有数据的状态更改保存入当前检查点”:它们都是一个“截止时间”的标志。所以在处理多个分区的传递时,也要以是否还会有数据到来作为一个判断标准。
具体实现上,Flink 使用了 Chandy-Lamport 算法的一种变体,被称为“异步分界线快照”(asynchronous barrier snapshotting)算法。算法的核心就是两个原则:当上游任务向多个并行下游任务发送 barrier 时,需要广播出去;而当多个上游任务向同一个下游任务传递 barrier 时,需要在下游任务执行“分界线对齐”(barrier alignment)操作,也就是需要等到所有并行分区的 barrier 都到齐,才可以开始状态的保存。
为了详细解释检查点算法的原理,我们对之前的 word count 程序进行扩展,考虑所有算子并行度为 2 的场景,如图 10-9 所示。

我们有两个并行的 Source 任务,会分别读取两个数据流(或者是一个源的不同分区)。这里每条流中的数据都是一个个的单词:“hello”“world”“hello”“flink”交替出现。此时第一条流的 Source 任务(为了方便,下文中我们直接叫它“Source 1”,其他任务类似)读取了 3个数据,偏移量为 3;而第二条流的 Source 任务(Source 2)只读取了一个“hello”数据,偏移量为 1。第一条流中的第一个数据“hello”已经完全处理完毕,所以 Sum 任务的状态中 key为 hello 对应着值 1,而且已经发出了结果(hello, 1);第二个数据“world”经过了 Map 任务的转换,还在被 Sum 任务处理;第三个数据“hello”还在被 Map 任务处理。而第二条流的第一个数据“hello”同样已经经过了 Map 转换,正在被 Sum 任务处理。
接下来就是检查点保存的算法。具体过程如下:
JobManager 发送指令,触发检查点的保存;Source 任务保存状态,插入分界线JobManager 会周期性地向每个 TaskManager 发送一条带有新检查点 ID 的消息,通过这种方式来启动检查点。收到指令后,TaskManger 会在所有 Source 任务中插入一个分界线(barrier),并将偏移量保存到远程的持久化存储中,如图 10-10 所示。
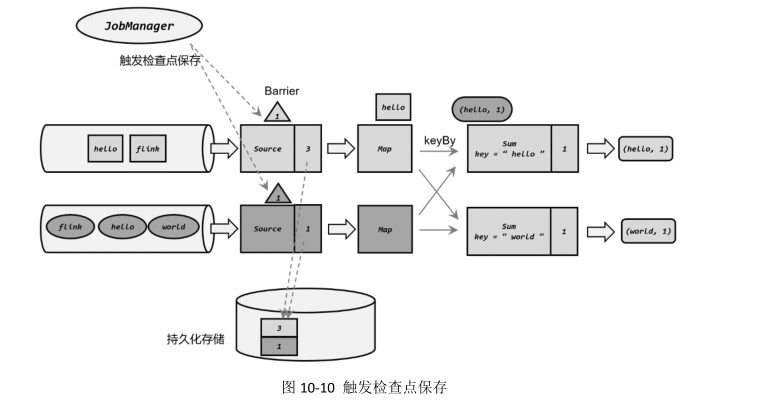
并行的 Source 任务保存的状态为 3 和 1,表示当前的 1 号检查点应该包含:第一条流中截至第三个数据、第二条流中截至第一个数据的所有状态更改。可以发现 Source 任务做这些的时候并不影响后面任务的处理,Sum 任务已经处理完了第一条流中传来的(world, 1),对应的状态也有了更改。
状态快照保存完成,分界线向下游传递
状态存入持久化存储之后,会返回通知给 Source 任务;Source 任务就会向 JobManager确认检查点完成,然后像数据一样把 barrier 向下游任务传递,如图 10-11 所示。
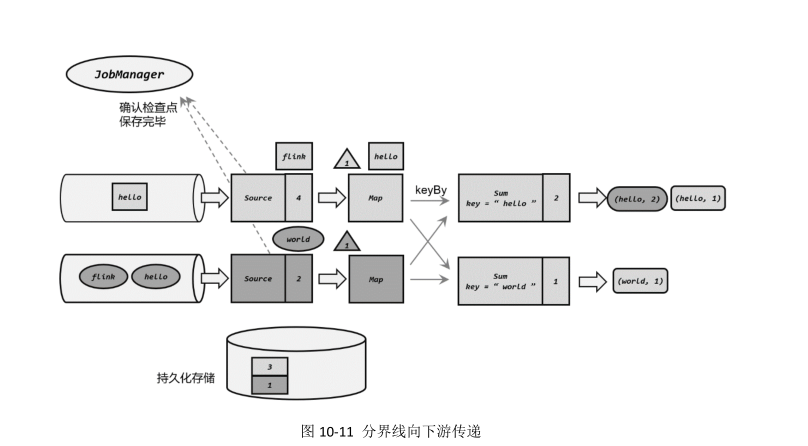
由于 Source 和 Map 之间是一对一(forward)的传输关系(这里没有考虑算子链 operatorchain),所以 barrier 可以直接传递给对应的 Map 任务。之后
Source 任务就可以继续读取新的数据了。与此同时,Sum 1 已经将第二条流传来的(hello,1)处理完毕,更新了状态。
向下游多个并行子任务广播分界线,执行分界线对齐
Map 任务没有状态,所以直接将 barrier 继续向下游传递。这时由于进行了 keyBy 分区,所以需要将 barrier 广播到下游并行的两个 Sum 任务,如图 10-12 所示。同时,Sum 任务可能收到来自上游两个并行 Map 任务的 barrier,所以需要执行“分界线对齐”操作。
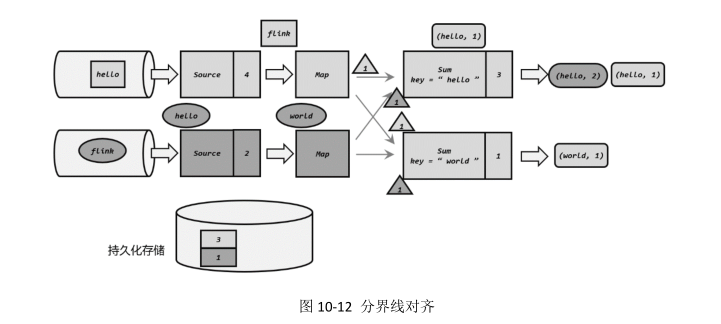
此时的 Sum 2 收到了来自上游两个 Map 任务的 barrier,说明第一条流第三个数据、第二条流第一个数据都已经处理完,可以进行状态的保存了;而 Sum 1 只收到了来自 Map 2 的barrier,所以这时需要等待分界线对齐。在等待的过程中,如果分界线尚未到达的分区任务Map 1 又传来了数据(hello, 1),说明这是需要保存到检查点的,Sum 任务应该正常继续处理数据,状态更新为 3;而如果分界线已经到达的分区任务 Map 2 又传来数据,这已经是下一个检查点要保存的内容了,就不应立即处理,而是要缓存起来、等到状态保存之后再做处理。
分界线对齐后,保存状态到持久化存储
各个分区的分界线都对齐后,就可以对当前状态做快照,保存到持久化存储了。存储完成之后,同样将 barrier 向下游继续传递,并通知 JobManager 保存完毕,如图 10-13 所示。

这个过程中,每个任务保存自己的状态都是相对独立的,互不影响。我们可以看到,当Sum 将当前状态保存完毕时,Source 1 任务已经读取到第一条流的第五个数据了。
先处理缓存数据,然后正常继续处理
完成检查点保存之后,任务就可以继续正常处理数据了。这时如果有等待分界线对齐时缓存的数据,需要先做处理;然后再按照顺序依次处理新到的数据。
当 JobManager 收到所有任务成功保存状态的信息,就可以确认当前检查点成功保存。之后遇到故障就可以从这里恢复了。
由于分界线对齐要求先到达的分区做缓存等待,一定程度上会影响处理的速度;当出现背压(backpressure)时,下游任务会堆积大量的缓冲数据,检查点可能需要很久才可以保存完毕。为了应对这种场景,Flink 1.11 之后提供了不对齐的检查点保存方式,可以将未处理的缓冲数据(in-flight data)也保存进检查点。这样,当我们遇到一个分区 barrier 时就不需等待对齐,而是可以直接启动状态的保存了。












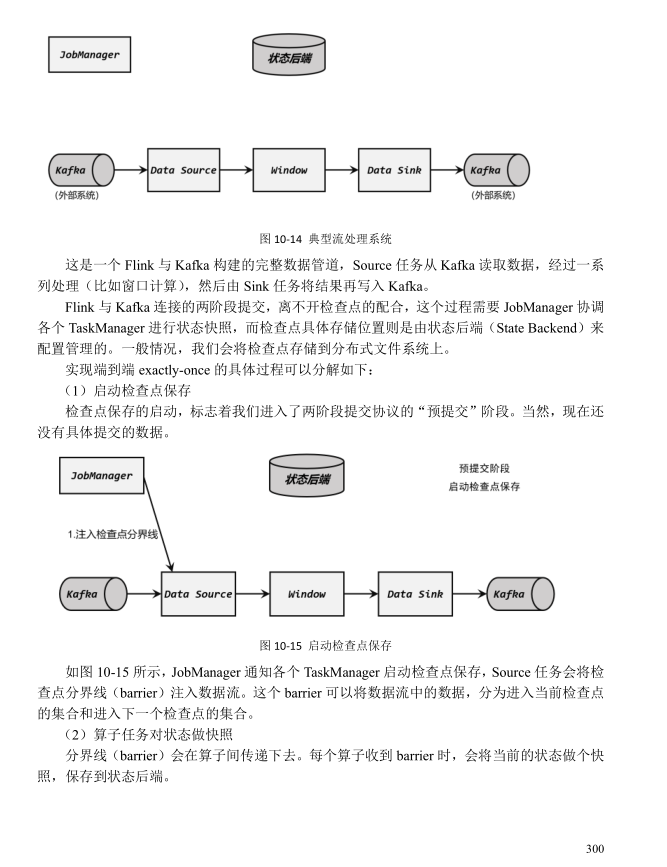
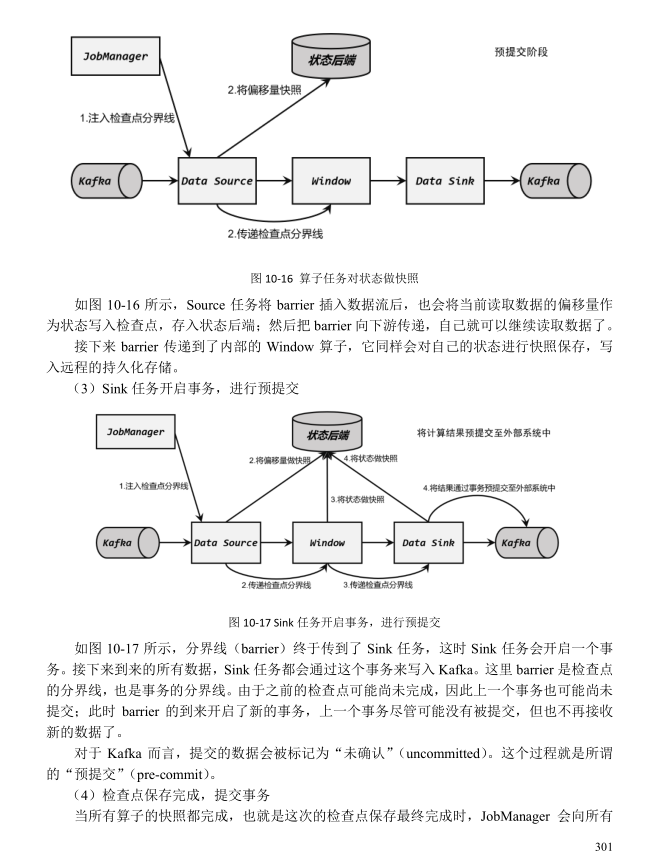
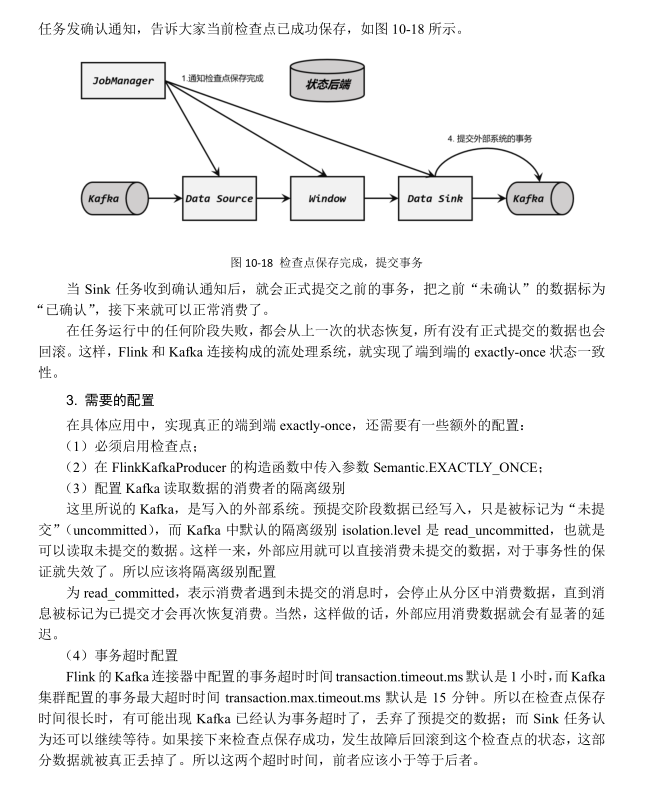

# Table API 和SQL
如图 11-1 所示,在 Flink 提供的多层级 API 中,核心是 DataStream API,这是我们开发流处理应用的基本途径;底层则是所谓的处理函数(process function),可以访问事件的时间信息、注册定时器、自定义状态,进行有状态的流处理。DataStream API 和处理函数比较通用,有了这些 API,理论上我们就可以实现所有场景的需求了。
不过在企业实际应用中,往往会面对大量类似的处理逻辑,所以一般会将底层 API 包装成更加具体的应用级接口。怎样的接口风格最容易让大家接收呢?作为大数据工程师,我们最为熟悉的数据统计方式,当然就是写 SQL 了。
SQL 是结构化查询语言(Structured Query Language)的缩写,是我们对关系型数据库进行查询和修改的通用编程语言。在关系型数据库中,数据是以表(table)的形式组织起来的,所以也可以认为 SQL 是用来对表进行处理的工具语言。无论是传统架构中进行数据存储的MySQL、PostgreSQL,还是大数据应用中的 Hive,都少不了 SQL 的身影;而 Spark 作为大数据处理引擎,为了更好地支持在 Hive 中的 SQL 查询,也提供了 Spark SQL 作为入口。
Flink 同样提供了对于“表”处理的支持,这就是更高层级的应用 API,在 Flink 中被称为Table API 和 SQL。Table API 顾名思义,就是基于“表”(Table)的一套 API,它是内嵌在 Java、Scala 等语言中的一种声明式领域特定语言(DSL),也就是专门为处理表而设计的;在此基础上,Flink 还基于 Apache Calcite 实现了对 SQL 的支持。这样一来,我们就可以在 Flink 程序中直接写 SQL 来实现处理需求了。
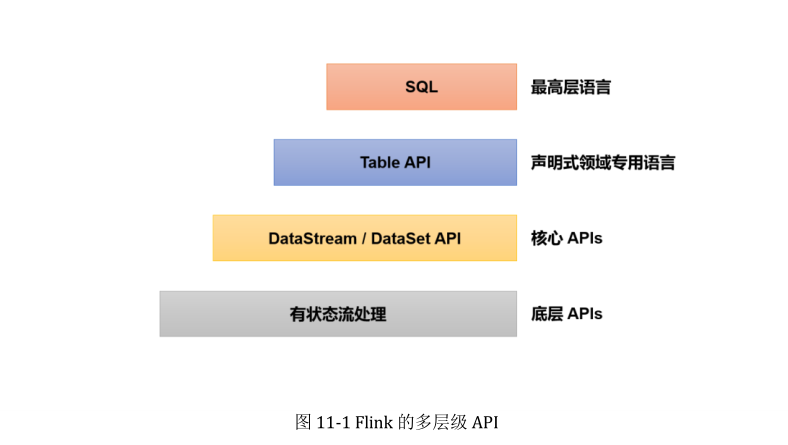
在 Flink 中这两种 API 被集成在一起,SQL 执行的对象也是 Flink 中的表(Table),所以我们一般会认为它们是一体的,本章会放在一起进行介绍。Flink 是批流统一的处理框架,无论是批处理(DataSet API)还是流处理(DataStream API),在上层应用中都可以直接使用 Table API 或者 SQL 来实现;这两种 API 对于一张表执行相同的查询操作,得到的结果是完全一样的。我们主要还是以流处理应用为例进行讲解。
需要说明的是,Table API 和 SQL 最初并不完善,在 Flink 1.9 版本合并阿里巴巴内部版本Blink 之后发生了非常大的改变,此后也一直处在快速开发和完善的过程中,直到 Flink 1.12版本才基本上做到了功能上的完善。而即使是在目前最新的 1.13 版本中,Table API 和 SQL 也依然不算稳定,接口用法还在不停调整和更新。所以这部分希望大家重在理解原理和基本用法,具体的 API 调用可以随时关注官网的更新变化。
# 快速上手
如果我们对关系型数据库和 SQL 非常熟悉,那么Table API和 SQL的使用其实非常简单:只要得到一个“表”(Table),然后对它调用 Table API,或者直接写 SQL 就可以了。接下来我们就以一个非常简单的例子上手,初步了解一下这种高层级 API 的使用方法。
# 需要引入的依赖
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
2
3
4
5
这里的依赖是一个 Java 的“桥接器”(bridge),主要就是负责 Table API 和下层 DataStreamAPI 的连接支持,按照不同的语言分为 Java 版和 Scala 版
如果我们希望在本地的集成开发环境(IDE)里运行 Table API 和 SQL,还需要引入以下依赖:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-blink_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
2
3
4
5
6
7
8
9
10
这里主要添加的依赖是一个“计划器”(planner),它是 Table API 的核心组件,负责提供运行时环境,并生成程序的执行计划。这里我们用到的是新版的 blink planner。由于 Flink 安装包的 lib 目录下会自带 planner,所以在生产集群环境中提交的作业不需要打包这个依赖。
而在 Table API 的内部实现上,部分相关的代码是用 Scala 实现的,所以还需要额外添加一个 Scala 版流处理的相关依赖。
另外,如果想实现自定义的数据格式来做序列化,可以引入下面的依赖:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-common</artifactId>
<version>${flink.version}</version>
</dependency>
2
3
4
5
# 一个简单示例
public class Demo_01_TableApi_Demo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
SingleOutputStreamOperator<Event> stream = env.addSource(new Demo_03_Source_Customer.ClickSource())
.assignTimestampsAndWatermarks(
WatermarkStrategy.<Event>forBoundedOutOfOrderness(Duration.ZERO)
.withTimestampAssigner(new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event event, long l) {
return event.timestamp;
}
})
);
// 获取表环境
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
// 将数据流转换成表
Table eventTable = tableEnv.fromDataStream(stream);
// 用SQL的方式提取数据
Table visitTable = tableEnv.sqlQuery("select url, user from " + eventTable);
// 将表转换成数据流,打印输出
tableEnv.toDataStream(visitTable).print();
env.execute();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
这里我们需要创建一个“表环境”(TableEnvironment),然后将数据流(DataStream)转换成一个表(Table);之后就可以执行 SQL 在这个表中查询数据了。查询得到的结果依然是一个表,把它重新转换成流就可以打印输出了。
+I[./home, Alice]
+I[./cart, Bob]
+I[./prod?id=1, Alice]
+I[./home, Cary]
+I[./prod?id=3, Bob]
+I[./prod?id=7, Alice]
2
3
4
5
6
可以看到,我们将原始的 Event 数据转换成了(url,user)这样类似二元组的类型。每行输出前面有一个“+I”标志,这是表示每条数据都是“插入”(Insert)到表中的新增数据。
Table 是 Table API 中的核心接口类,对应着我们熟悉的“表”的概念。基于 Table 我们也可以调用一系列查询方法直接进行转换,这就是所谓 Table API 的处理方式:
// 用 Table API 方式提取数据
Table clickTable2 = eventTable.select($("url"), $("user"));
2
这里的$符号是 Table API 中定义的“表达式”类 Expressions 中的一个方法,传入一个字段名称,就可以指代数据中对应字段。将得到的表转换成流打印输出,会发现结果与直接执行SQL 完全一样。
# 基本 API
通过上节中的简单示例,我们已经对 Table API 和 SQL 的用法有了大致的了解;本节就继续展开,对 API 的相关用法做一个详细的说明。
# 程序架构
在 Flink 中,Table API 和 SQL 可以看作联结在一起的一套 API,这套 API 的核心概念就是“表”(Table)。在我们的程序中,输入数据可以定义成一张表;然后对这张表进行查询,就可以得到新的表,这相当于就是流数据的转换操作;最后还可以定义一张用于输出的表,负责将处理结果写入到外部系统。
我们可以看到,程序的整体处理流程与 DataStream API 非常相似,也可以分为读取数据源(Source)、转换(Transform)、输出数据(Sink)三部分;只不过这里的输入输出操作不需要额外定义,只需要将用于输入和输出的表定义出来,然后进行转换查询就可以了。
程序基本架构如下:
// 创建表环境
TableEnvironment tableEnv = ...;
// 创建输入表,连接外部系统读取数据
tableEnv.executeSql("CREATE TEMPORARY TABLE inputTable ... WITH ( 'connector' = ... )");
// 注册一个表,连接到外部系统,用于输出
tableEnv.executeSql("CREATE TEMPORARY TABLE outputTable ... WITH ( 'connector' = ... )");
// 执行 SQL 对表进行查询转换,得到一个新的表
Table table1 = tableEnv.sqlQuery("SELECT ... FROM inputTable... ");
// 使用 Table API 对表进行查询转换,得到一个新的表
Table table2 = tableEnv.from("inputTable").select(...);
// 将得到的结果写入输出表
TableResult tableResult = table1.executeInsert("outputTable");
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
与上一节中不同,这里不是从一个 DataStream 转换成 Table,而是通过执行 DDL 来直接创建一个表。这里执行的 CREATE 语句中用 WITH 指定了外部系统的连接器,于是就可以连接外部系统读取数据了。这其实是更加一般化的程序架构,因为这样我们就可以完全抛开DataStream API,直接用 SQL 语句实现全部的流处理过程。
而后面对于输出表的定义是完全一样的。可以发现,在创建表的过程中,其实并不区分“输入”还是“输出”,只需要将这个表“注册”进来、连接到外部系统就可以了;这里的 inputTable、outputTable 只是注册的表名,并不代表处理逻辑,可以随意更换。至于表的具体作用,则要等到执行后面的查询转换操作时才能明确。我们直接从 inputTable 中查询数据,那么 inputTable就是输入表;而 outputTable 会接收另外表的结果进行写入,那么就是输出表。
在早期的版本中,有专门的用于输入输出的 TableSource 和 TableSink,这与流处理里的概念是一一对应的;不过这种方式与关系型表和 SQL 的使用习惯不符,所以已被弃用,不再区分 Source 和 Sink。
# 创建表环境
对于 Flink 这样的流处理框架来说,数据流和表在结构上还是有所区别的。所以使用 TableAPI 和 SQL 需要一个特别的运行时环境,这就是所谓的“表环境”(TableEnvironment)。它主要负责:
- 注册 Catalog 和表
- 执行 SQL 查询;
- 注册用户自定义函数(UDF);
- DataStream 和表之间的转换。
这里的 Catalog 就是“目录”,与标准 SQL 中的概念是一致的,主要用来管理所有数据库(database)和表(table)的元数据(metadata)。通过 Catalog 可以方便地对数据库和表进行查询的管理,所以可以认为我们所定义的表都会“挂靠”在某个目录下,这样就可以快速检索。在表环境中可以由用户自定义 Catalog,并在其中注册表和自定义函数(UDF)。默认的 Catalog就叫作 default_catalog。
每个表和 SQL 的执行,都必须绑定在一个表环境(TableEnvironment)中。TableEnvironment是 Table API 中提供的基本接口类,可以通过调用静态的 create()方法来创建一个表环境实例。方法需要传入一个环境的配置参数 EnvironmentSettings,它可以指定当前表环境的执行模式和计划器(planner)。执行模式有批处理和流处理两种选择,默认是流处理模式;计划器默认使用 blink planner。
EnvironmentSettings settings = EnvironmentSettings
.newInstance()
.inStreamingMode() // 使用流处理模式
.build();
TableEnvironment tableEnv = TableEnvironment.create(settings);
2
3
4
5
6
对于流处理场景,其实默认配置就完全够用了。所以我们也可以用另一种更加简单的方式来创建表环境:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
2
这 里 我 们 引 入 了 一 个 “ 流 式 表 环 境 ”( StreamTableEnvironment ), 它 是 继 承 自TableEnvironment 的子接口。调用它的 create()方法,只需要直接将当前的流执行环境(StreamExecutionEnvironment)传入,就可以创建出对应的流式表环境了。这也正是我们在上一节简单示例中使用的方式。
# 创建表
表(Table)是我们非常熟悉的一个概念,它是关系型数据库中数据存储的基本形式,也是 SQL 执行的基本对象。Flink 中的表概念也并不特殊,是由多个“行”数据构成的,每个行(Row)又可以有定义好的多个列(Column)字段;整体来看,表就是固定类型的数据组成的二维矩阵。
为了方便地查询表,表环境中会维护一个目录(Catalog)和表的对应关系。所以表都是通过 Catalog 来进行注册创建的。表在环境中有一个唯一的 ID,由三部分组成:目录(catalog)名,数据库(database)名,以及表名。在默认情况下,目录名为 default_catalog,数据库名为default_database。所以如果我们直接创建一个叫作 MyTable 的表,它的 ID 就是:
default_catalog.default_database.MyTable
具体创建表的方式,有通过连接器(connector)和虚拟表(virtual tables)两种。
# 连接器表(Connector Tables)
在代码中,我们可以调用表环境的 executeSql()方法,可以传入一个 DDL 作为参数执行SQL 操作。这里我们传入一个 CREATE 语句进行表的创建,并通过 WITH 关键字指定连接到外部系统的连接器:
tableEnv.executeSql("CREATE [TEMPORARY] TABLE MyTable ... WITH ( 'connector' = ... )");
这里的 TEMPORARY 关键字可以省略。关于连接器的具体定义,我们会在 11.8 节中展开讲解。
这 里 没 有 定 义 Catalog 和 Database , 所 以 都 是 默 认 的 , 表 的 完 整 ID 就 是default_catalog.default_database.MyTable。如果希望使用自定义的目录名和库名,可以在环境中进行设置:
tEnv.useCatalog("custom_catalog");
tEnv.useDatabase("custom_database");
2
这样我们创建的表完整 ID 就变成了 custom_catalog.custom_database.MyTable。之后在表环境中创建的所有表,ID 也会都以 custom_catalog.custom_database 作为前缀。
# 虚拟表(Virtual Tables)
在环境中注册之后,我们就可以在 SQL 中直接使用这张表进行查询转换了。
Table newTable = tableEnv.sqlQuery("SELECT ... FROM MyTable... ");
这里调用了表环境的 sqlQuery()方法,直接传入一条 SQL 语句作为参数执行查询,得到的结果是一个 Table 对象。Table 是 Table API 中提供的核心接口类,就代表了一个 Java 中定义的表实例。
得到的 newTable 是一个中间转换结果,如果之后又希望直接使用这个表执行 SQL,又该怎么做呢?由于 newTable 是一个 Table 对象,并没有在表环境中注册;所以我们还需要将这个中间结果表注册到环境中,才能在 SQL 中使用:
tableEnv.createTemporaryView("NewTable", newTable);
我们发现,这里的注册其实是创建了一个“虚拟表”(Virtual Table)。这个概念与 SQL 语法中的视图(View)非常类似,所以调用的方法也叫作创建“虚拟视图” (createTemporaryView)。视图之所以是“虚拟”的,是因为我们并不会直接保存这个表的内容,并没有“实体”;只是在用到这张表的时候,会将它对应的查询语句嵌入到 SQL 中。
注册为虚拟表之后,我们就又可以在 SQL 中直接使用 NewTable 进行查询转换了。不难看到,通过虚拟表可以非常方便地让 SQL 分步骤执行得到中间结果,这为代码编写提供了很大的便利。
另外,虚拟表也可以让我们在 Table API 和 SQL 之间进行自由切换。一个 Java 中的 Table对象可以直接调用 Table API 中定义好的查询转换方法,得到一个中间结果表;这跟对注册好的表直接执行 SQL 结果是一样的。具体我们会在下一小节继续讲解。
# 表的查询
创建好了表,接下来自然就是对表进行查询转换了。对一个表的查询(Query)操作,就对应着流数据的转换(Transform)处理。
Flink 为我们提供了两种查询方式:SQL 和 Table API。
# 执行 SQL 进行查询
基于表执行 SQL 语句,是我们最为熟悉的查询方式。Flink 基于 Apache Calcite 来提供对SQL 的支持,Calcite 是一个为不同的计算平台提供标准 SQL 查询的底层工具,很多大数据框架比如 Apache Hive、Apache Kylin 中的 SQL 支持都是通过集成 Calcite 来实现的。
在代码中,我们只要调用表环境的 sqlQuery()方法,传入一个字符串形式的 SQL 查询语句就可以了。执行得到的结果,是一个 Table 对象。
// 创建表环境
TableEnvironment tableEnv = ...;
// 创建表
tableEnv.executeSql("CREATE TABLE EventTable ... WITH ( 'connector' = ... )");
// 查询用户 Alice 的点击事件,并提取表中前两个字段
Table aliceVisitTable = tableEnv.sqlQuery(
"SELECT user, url " +
"FROM EventTable " +
"WHERE user = 'Alice' "
);
2
3
4
5
6
7
8
9
10
目前 Flink 支持标准 SQL 中的绝大部分用法,并提供了丰富的计算函数。这样我们就可以把已有的技术迁移过来,像在 MySQL、Hive 中那样直接通过编写 SQL 实现自己的处理需求,从而大大降低了 Flink 上手的难度。
例如,我们也可以通过 GROUP BY 关键字定义分组聚合,调用 COUNT()、SUM()这样的函数来进行统计计算:
Table urlCountTable = tableEnv.sqlQuery(
"SELECT user, COUNT(url) " +
"FROM EventTable " +
"GROUP BY user "
);
2
3
4
5
上面的例子得到的是一个新的 Table 对象,我们可以再次将它注册为虚拟表继续在 SQL中调用。另外,我们也可以直接将查询的结果写入到已经注册的表中,这需要调用表环境的executeSql()方法来执行 DDL,传入的是一个 INSERT 语句:
// 注册表
tableEnv.executeSql("CREATE TABLE EventTable ... WITH ( 'connector' = ... )");
tableEnv.executeSql("CREATE TABLE OutputTable ... WITH ( 'connector' = ... )");
// 将查询结果输出到 OutputTable 中
tableEnv.executeSql (
"INSERT INTO OutputTable " +
"SELECT user, url " +
"FROM EventTable " +
"WHERE user = 'Alice' "
);
2
3
4
5
6
7
8
9
10
11
# 调用 Table API 进行查询
另外一种查询方式就是调用 Table API。这是嵌入在 Java 和 Scala 语言内的查询 API,核心就是 Table 接口类,通过一步步链式调用 Table 的方法,就可以定义出所有的查询转换操作。每一步方法调用的返回结果,都是一个 Table。
由于Table API是基于Table的Java实例进行调用的,因此我们首先要得到表的Java对象。基于环境中已注册的表,可以通过表环境的 from()方法非常容易地得到一个 Table 对象:
Table eventTable = tableEnv.from("EventTable");
传入的参数就是注册好的表名。注意这里 eventTable 是一个 Table 对象,而 EventTable 是在环境中注册的表名。得到 Table 对象之后,就可以调用 API 进行各种转换操作了,得到的是一个新的 Table 对象:
Table maryClickTable = eventTable
.where($("user").isEqual("Alice"))
.select($("url"), $("user"));
2
3
这里每个方法的参数都是一个“表达式”(Expression),用方法调用的形式直观地说明了想要表达的内容;“$”符号用来指定表中的一个字段。上面的代码和直接执行 SQL 是等效的。
Table API 是嵌入编程语言中的 DSL,SQL 中的很多特性和功能必须要有对应的实现才可以使用,因此跟直接写 SQL 比起来肯定就要麻烦一些。目前 Table API 支持的功能相对更少,可以预见未来 Flink 社区也会以扩展 SQL 为主,为大家提供更加通用的接口方式;所以我们接下来也会以介绍 SQL 为主,简略地提及 Table API。
# 两种 API 的结合使用
可以发现,无论是调用 Table API 还是执行 SQL,得到的结果都是一个 Table 对象;所以这两种 API 的查询可以很方便地结合在一起。
无论是那种方式得到的 Table 对象,都可以继续调用 Table API 进行查询转换;
如果想要对一个表执行 SQL 操作(用 FROM 关键字引用),必须先在环境中对它进行注册。所以我们可以通过创建虚拟表的方式实现两者的转换:
tableEnv.createTemporaryView("MyTable", myTable);1
注意:这里的第一个参数"MyTable"是注册的表名,而第二个参数 myTable 是 Java 中的Table 对象。
另外要说明的是,在 11.1.2 小节的简单示例中,我们并没有将 Table 对象注册为虚拟表就直接在 SQL 中使用了:
Table clickTable = tableEnvironment.sqlQuery("select url, user from " + eventTable);
这其实是一种简略的写法,我们将 Table 对象名 eventTable 直接以字符串拼接的形式添加到 SQL 语句中,在解析时会自动注册一个同名的虚拟表到环境中,这样就省略了创建虚拟视图的步骤。
两种 API 殊途同归,实际应用中可以按照自己的习惯任意选择。不过由于结合使用容易引起混淆,而 Table API 功能相对较少、通用性较差,所以企业项目中往往会直接选择 SQL 的方式来实现需求。
# 输出表
表的创建和查询,就对应着流处理中的读取数据源(Source)和转换(Transform);而最后一个步骤 Sink,也就是将结果数据输出到外部系统,就对应着表的输出操作。
在代码上,输出一张表最直接的方法,就是调用 Table 的方法 executeInsert()方法将一个Table 写入到注册过的表中,方法传入的参数就是注册的表名。
// 注册表,用于输出数据到外部系统
tableEnv.executeSql("CREATE TABLE OutputTable ... WITH ( 'connector' = ... )");
// 经过查询转换,得到结果表
Table result = ...
// 将结果表写入已注册的输出表中
result.executeInsert("OutputTable");
2
3
4
5
6
7
8
在底层,表的输出是通过将数据写入到 TableSink 来实现的。TableSink 是 Table API 中提供的一个向外部系统写入数据的通用接口,可以支持不同的文件格式(比如 CSV、Parquet)、存储数据库(比如 JDBC、HBase、Elasticsearch)和消息队列(比如 Kafka)。它有些类似于DataStream API 中调用 addSink()方法时传入的 SinkFunction,有不同的连接器对它进行了实现。关于不同外部系统的连接器,我们会在 11.8 节展开介绍。
这里可以发现,我们在环境中注册的“表”,其实在写入数据的时候就对应着一个 TableSink。
# 表和流的转换
从创建表环境开始,历经表的创建、查询转换和输出,我们已经可以使用 Table API 和 SQL进行完整的流处理了。不过在应用的开发过程中,我们测试业务逻辑一般不会直接将结果直接写入到外部系统,而是在本地控制台打印输出。对于 DataStream 这非常容易,直接调用 print()方法就可以看到结果数据流的内容了;但对于 Table 就比较悲剧——它没有提供 print()方法。这该怎么办呢?
在 Flink 中我们可以将 Table 再转换成 DataStream,然后进行打印输出。这就涉及了表和流的转换。
# 将表(Table)转换成流(DataStream)
调用 toDataStream()方法
将一个Table对象转换成DataStream非常简单,只要直接调用表环境的方法toDataStream()就可以了。例如,我们可以将 11.2.4 小节经查询转换得到的表 maryClickTable 转换成流打印输出,这代表了“Mary 点击的 url 列表”:
Table aliceVisitTable = tableEnv.sqlQuery( "SELECT user, url " + "FROM EventTable " + "WHERE user = 'Alice' " ); // 将表转换成数据流 tableEnv.toDataStream(aliceVisitTable).print();1
2
3
4
5
6
7
8这里需要将要转换的 Table 对象作为参数传入。
调用 toChangelogStream()方法
将 maryClickTable 转换成流打印输出是很简单的;然而,如果我们同样希望将“用户点击次数统计”表 urlCountTable 进行打印输出,就会抛出一个 TableException 异常:
Exception in thread "main" org.apache.flink.table.api.TableException: Table sink 'default_catalog.default_database.Unregistered_DataStream_Sink_1' doesn't support consuming update changes ...1
2
3这表示当前的 TableSink 并不支持表的更新(update)操作。这是什么意思呢? 因为 print 本身也可以看作一个 Sink 操作,所以这个异常就是说打印输出的 Sink 操作不支持对数据进行更新。具体来说,urlCountTable 这个表中进行了分组聚合统计,所以表中的每一行是会“更新”的。也就是说,Alice 的第一个点击事件到来,表中会有一行(Alice, 1);第二个点击事件到来,这一行就要更新为(Alice, 2)。但之前的(Alice, 1)已经打印输出了,“覆水难收”,我们怎么能对它进行更改呢?所以就会抛出异常。
解决的思路是,对于这样有更新操作的表,我们不要试图直接把它转换成 DataStream 打印输出,而是记录一下它的“更新日志”(change log)。这样一来,对于表的所有更新操作,就变成了一条更新日志的流,我们就可以转换成流打印输出了。 代码中需要调用的是表环境的 toChangelogStream()方法:
Table urlCountTable = tableEnv.sqlQuery( "SELECT user, COUNT(url) " + "FROM EventTable " + "GROUP BY user " ); // 将表转换成更新日志流 tableEnv.toDataStream(urlCountTable).print();1
2
3
4
5
6
7与“更新日志流”(Changelog Streams)对应的,是那些只做了简单转换、没有进行聚合统计的表,例如前面提到的 maryClickTable。它们的特点是数据只会插入、不会更新,所以也被叫作“仅插入流”(Insert-Only Streams)。
# 将流(DataStream)转换成表(Table)
调用 fromDataStream()方法
想要将一个 DataStream 转换成表也很简单,可以通过调用表环境的 fromDataStream()方法来实现,返回的就是一个 Table 对象。例如,我们可以直接将事件流 eventStream 转换成一个表:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); // 获取表环境 StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env); // 读取数据源 SingleOutputStreamOperator<Event> eventStream = env.addSource(...) // 将数据流转换成表 Table eventTable = tableEnv.fromDataStream(eventStream);1
2
3
4
5
6
7由于流中的数据本身就是定义好的 POJO 类型 Event,所以我们将流转换成表之后,每一行数据就对应着一个 Event,而表中的列名就对应着 Event 中的属性。
另外,我们还可以在 fromDataStream()方法中增加参数,用来指定提取哪些属性作为表中的字段名,并可以任意指定位置:
// 提取 Event 中的 timestamp 和 url 作为表中的列 Table eventTable2 = tableEnv.fromDataStream(eventStream, $("timestamp"),$("url"));1
2需要注意的是,timestamp 本身是 SQL 中的关键字,所以我们在定义表名、列名时要尽量避免。这时可以通过表达式的 as()方法对字段进行重命名:
// 将 timestamp 字段重命名为 ts Table eventTable2 = tableEnv.fromDataStream(eventStream, $("timestamp").as("ts"),$("url"));1
2调用 createTemporaryView()方法
调用 fromDataStream()方法简单直观,可以直接实现 DataStream 到 Table 的转换;不过如果我们希望直接在 SQL 中引用这张表,就还需要调用表环境的 createTemporaryView()方法来创建虚拟视图了。
对于这种场景,也有一种更简洁的调用方式。我们可以直接调用 createTemporaryView()方法创建虚拟表,传入的两个参数,第一个依然是注册的表名,而第二个可以直接就是DataStream。之后仍旧可以传入多个参数,用来指定表中的字段
tableEnv.createTemporaryView("EventTable", eventStream,$("timestamp").as("ts"),$("url"));1这样,我们接下来就可以直接在 SQL 中引用表 EventTable 了。
调用 fromChangelogStream ()方法
表环境还提供了一个方法 fromChangelogStream(),可以将一个更新日志流转换成表。这个方法要求流中的数据类型只能是 Row,而且每一个数据都需要指定当前行的更新类型(RowKind);所以一般是由连接器帮我们实现的,直接应用比较少见,感兴趣的读者可以查看官网的文档说明。
# 支持的数据类型
前面示例中的 DataStream,流中的数据类型都是定义好的 POJO 类。如果 DataStream 中的类型是简单的基本类型,还可以直接转换成表吗?这就涉及了 Table 中支持的数据类型。
整体来看,DataStream 中支持的数据类型,Table 中也是都支持的,只不过在进行转换时需要注意一些细节。
原子类型
在 Flink 中,基础数据类型(Integer、Double、String)和通用数据类型(也就是不可再拆分的数据类型)统一称作“原子类型”。原子类型的 DataStream,转换之后就成了只有一列的Table,列字段(field)的数据类型可以由原子类型推断出。另外,还可以在 fromDataStream()方法里增加参数,用来重新命名列字段。
StreamTableEnvironment tableEnv = ...; DataStream<Long> stream = ...; // 将数据流转换成动态表,动态表只有一个字段,重命名为 myLong Table table = tableEnv.fromDataStream(stream, $("myLong"));1
2
3
4Tuple 类型
当原子类型不做重命名时,默认的字段名就是“f0”,容易想到,这其实就是将原子类型看作了一元组 Tuple1 的处理结果。
Table 支持 Flink 中定义的元组类型 Tuple,对应在表中字段名默认就是元组中元素的属性名 f0、f1、f2...。所有字段都可以被重新排序,也可以提取其中的一部分字段。字段还可以通过调用表达式的 as()方法来进行重命名。
StreamTableEnvironment tableEnv = ...; DataStream<Tuple2<Long, Integer>> stream = ...; // 将数据流转换成只包含 f1 字段的表 Table table = tableEnv.fromDataStream(stream, $("f1")); // 将数据流转换成包含 f0 和 f1 字段的表,在表中 f0 和 f1 位置交换 Table table = tableEnv.fromDataStream(stream, $("f1"), $("f0")); // 将 f1 字段命名为 myInt,f0 命名为 myLong Table table = tableEnv.fromDataStream(stream, $("f1").as("myInt"),$("f0").as("myLong"));1
2
3
4
5
6
7
8POJO 类型
Flink 也支持多种数据类型组合成的“复合类型”,最典型的就是简单 Java 对象(POJO 类型)。由于 POJO 中已经定义好了可读性强的字段名,这种类型的数据流转换成 Table 就显得无比顺畅了。
将 POJO 类型的 DataStream 转换成 Table,如果不指定字段名称,就会直接使用原始 POJO类型中的字段名称。POJO 中的字段同样可以被重新排序、提却和重命名,这在之前的例子中已经有过体现。
StreamTableEnvironment tableEnv = ...; DataStream<Event> stream = ...; Table table = tableEnv.fromDataStream(stream); Table table = tableEnv.fromDataStream(stream, $("user")); Table table = tableEnv.fromDataStream(stream, $("user").as("myUser"),$("url").as("myUrl"));1
2
3
4
5Row 类型
Flink 中还定义了一个在关系型表中更加通用的数据类型——行(Row),它是 Table 中数据的基本组织形式。Row 类型也是一种复合类型,它的长度固定,而且无法直接推断出每个字段的类型,所以在使用时必须指明具体的类型信息;我们在创建 Table 时调用的 CREATE语句就会将所有的字段名称和类型指定,这在 Flink 中被称为表的“模式结构”(Schema)。除此之外,Row 类型还附加了一个属性 RowKind,用来表示当前行在更新操作中的类型。这样,Row 就可以用来表示更新日志流(changelog stream)中的数据,从而架起了 Flink 中流和表的转换桥梁。
所以在更新日志流中,元素的类型必须是 Row,而且需要调用 ofKind()方法来指定更新类型。下面是一个具体的例子:
DataStream<Row> dataStream = env.fromElements( Row.ofKind(RowKind.INSERT, "Alice", 12), Row.ofKind(RowKind.INSERT, "Bob", 5), Row.ofKind(RowKind.UPDATE_BEFORE, "Alice", 12), Row.ofKind(RowKind.UPDATE_AFTER, "Alice", 100)); // 将更新日志流转换为表 Table table = tableEnv.fromChangelogStream(dataStream);1
2
3
4
5
6
7
8
# 综合应用示例
现在,我们可以将介绍过的所有 API 整合起来,写出一段完整的代码。同样还是用户的一组点击事件,我们可以查询出某个用户(例如 Alice)点击的 url 列表,也可以统计出每个用户累计的点击次数,这可以用两句 SQL 来分别实现。具体代码如下:
clicks.txt
Mary, ./home, 1000
Bob, ./cart, 1000
Alice, ./cart, 1000
Mary, ./cart, 2000
2
3
4
public class Demo_02_TableToStream_Demo {
public static void main(String[] args) throws Exception {
EnvironmentSettings settings = EnvironmentSettings
.newInstance()
.inStreamingMode() // 使用流处理模式
.build();
TableEnvironment tableEnv = TableEnvironment.create(settings);
String creatDDL = "CREATE TABLE clickTable (" +
" user_name STRING, " +
" url STRING, " +
" ts BIGINT " +
" ) WITH ( " +
" 'connector' = 'filesystem', " +
" 'path' = 'bigdata_09_flink/datas/clicks.txt', " +
" 'format' = 'csv' " +
")";
tableEnv.executeSql(creatDDL);
Table tableRes = tableEnv.sqlQuery("SELECT user_name,count(url) cnt FROM clickTable GROUP BY user_name");
String createPrintOutDDL = "CREATE TABLE printOutTable (" +
" user_name STRING, " +
" cnt BIGINT " +
" ) WITH ( " +
" 'connector' = 'print' " +
")";
tableEnv.executeSql(createPrintOutDDL);
tableRes.executeInsert("printOutTable");
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
6> +I[Alice, 1]
5> +I[Bob, 1]
3> +I[Mary, 1]
3> -U[Mary, 1]
3> +U[Mary, 2]
2
3
4
5
这里数据的前缀出现了+I、-U 和+U 三种 RowKind,分别表示 INSERT(插入)、UPDATE_BEFORE(更新前)和 UPDATE_AFTER(更新后)。当收到每个用户的第一次点击事件时,会在表中插入一条数据,例如+I[Alice, 1]、+I[Bob, 1]。而之后每当用户增加一次点击事件,就会带来一次更新操作,更新日志流(changelog stream)中对应会出现两条数据,分别表示之前数据的失效和新数据的生效;例如当 Alice 的第二条点击数据到来时,会出现一个-U[Alice, 1]和一个+U[Alice, 2],表示 Alice 的点击个数从 1 变成了 2。
这种表示更新日志的方式,有点像是声明“撤回”了之前的一条数据、再插入一条更新后的数据,所以也叫作“撤回流”(Retract Stream)。关于表到流转换过程的编码方式,我们会在下节进行更深入的讨论。
# 流处理中的表
上一节中介绍了 Table API 和 SQL 的基本使用方法。我们会发现,在 Flink 中使用表和 SQL基本上跟其它场景是一样的;不过对于表和流的转换,却稍显复杂。当我们将一个 Table 转换成 DataStream 时,有“仅插入流”(Insert-Only Streams)和“更新日志流”(Changelog Streams)两种不同的方式,具体使用哪种方式取决于表中是否存在更新(update)操作。
这种麻烦其实是不可避免的。我们知道,Table API 和 SQL 本质上都是基于关系型表的操作方式;而关系型表(Table)本身是有界的,更适合批处理的场景。所以在 MySQL、Hive这样的固定数据集中进行查询,使用 SQL 就会显得得心应手。而对于 Flink 这样的流处理框架来说,要处理的是源源不断到来的无界数据流,我们无法等到数据都到齐再做查询,每来一条数据就应该更新一次结果;这时如果一定要使用表和 SQL 进行处理,就会显得有些别扭了,需要引入一些特殊的概念。
我们可以将关系型表/SQL 与流处理做一个对比,如表 11-1 所示。
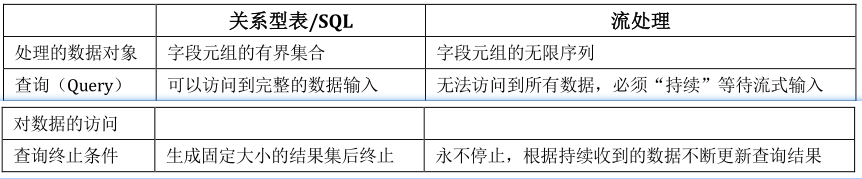
可以看到,其实关系型表和 SQL,主要就是针对批处理设计的,这和流处理有着天生的隔阂。既然“八字不合”,那 Flink 中的 Table API 和 SQL 又是怎样做流处理的呢?接下来我们就来深入探讨一下流处理中表的概念。
# 动态表和持续查询
流处理面对的数据是连续不断的,这导致了流处理中的“表”跟我们熟悉的关系型数据库中的表完全不同;而基于表执行的查询操作,也就有了新的含义
如果我们希望把流数据转换成表的形式,那么这表中的数据就会不断增长;如果进一步基于表执行 SQL 查询,那么得到的结果就不是一成不变的,而是会随着新数据的到来持续更新。
# 动态表(Dynamic Tables)
当流中有新数据到来,初始的表中会插入一行;而基于这个表定义的 SQL 查询,就应该在之前的基础上更新结果。这样得到的表就会不断地动态变化,被称为“动态表”(Dynamic Tables)。
动态表是Flink在Table API和SQL中的核心概念,它为流数据处理提供了表和SQL支持。我们所熟悉的表一般用来做批处理,面向的是固定的数据集,可以认为是“静态表”;而动态表则完全不同,它里面的数据会随时间变化。
其实动态表的概念,我们在传统的关系型数据库中已经有所接触。数据库中的表,其实是一系列 INSERT、UPDATE 和 DELETE 语句执行的结果;在关系型数据库中,我们一般把它称为更新日志流(changelog stream)。如果我们保存了表在某一时刻的快照(snapshot),那么接下来只要读取更新日志流,就可以得到表之后的变化过程和最终结果了。在很多高级关系型数据库(比如 Oracle、DB2)中都有“物化视图”(Materialized Views)的概念,可以用来缓存 SQL 查询的结果;它的更新其实就是不停地处理更新日志流的过程。
Flink 中的动态表,就借鉴了物化视图的思想。
# 持续查询(Continuous Query)
动态表可以像静态的批处理表一样进行查询操作。由于数据在不断变化,因此基于它定义的 SQL 查询也不可能执行一次就得到最终结果。这样一来,我们对动态表的查询也就永远不会停止,一直在随着新数据的到来而继续执行。这样的查询就被称作“持续查询”(Continuous Query)。对动态表定义的查询操作,都是持续查询;而持续查询的结果也会是一个动态表。
由于每次数据到来都会触发查询操作,因此可以认为一次查询面对的数据集,就是当前输入动态表中收到的所有数据。这相当于是对输入动态表做了一个“快照”(snapshot),当作有限数据集进行批处理;流式数据的到来会触发连续不断的快照查询,像动画一样连贯起来,就构成了“持续查询”。
如图 11-2 所示,描述了持续查询的过程。这里我们也可以清晰地看到流、动态表和持续查询的关系:

持续查询的步骤如下:
- 流(stream)被转换为动态表(dynamic table);
- 对动态表进行持续查询(continuous query),生成新的动态表;
- 生成的动态表被转换成流。
这样,只要 API 将流和动态表的转换封装起来,我们就可以直接在数据流上执行 SQL 查询,用处理表的方式来做流处理了。
# 将流转换成动态表
为了能够使用 SQL 来做流处理,我们必须先把流(stream)转换成动态表。当然,之前在讲解基本 API 时,已经介绍过代码中的 DataStream 和 Table 如何转换;现在我们则要抛开具体的数据类型,从原理上理解流和动态表的转换过程。
如果把流看作一张表,那么流中每个数据的到来,都应该看作是对表的一次插入(Insert)操作,会在表的末尾添加一行数据。因为流是连续不断的,而且之前的输出结果无法改变、只能在后面追加;所以我们其实是通过一个只有插入操作(insert-only)的更新日志(changelog)流,来构建一个表。
为了更好地说明流转换成动态表的过程,我们还是用 11.2 节中举的例子来做分析说明。
// 获取流环境
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 读取数据源
SingleOutputStreamOperator<Event> eventStream = env
.fromElements(
new Event("Alice", "./home", 1000L),
new Event("Bob", "./cart", 1000L),
new Event("Alice", "./prod?id=1", 5 * 1000L),
new Event("Cary", "./home", 60 * 1000L),
new Event("Bob", "./prod?id=3", 90 * 1000L),
new Event("Alice", "./prod?id=7", 105 * 1000L)
);
// 获取表环境
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
// 将数据流转换成表
tableEnv.createTemporaryView("EventTable", eventStream, $("user"), $("url"),$("timestamp").as("ts"));
// 统计每个用户的点击次数
Table urlCountTable = tableEnv.sqlQuery("SELECT user, COUNT(url) as cnt FROM EventTable GROUP BY user");
// 将表转换成数据流,在控制台打印输出
tableEnv.toChangelogStream(urlCountTable).print("count");
// 执行程序
env.execute();
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
我们现在的输入数据,就是用户在网站上的点击访问行为,数据类型被包装为 POJO 类型Event。我们将它转换成一个动态表,注册为 EventTable。表中的字段定义如下:
[
user: VARCHAR, // 用户名
url: VARCHAR, // 用户访问的 URL
ts: BIGINT // 时间戳
]
2
3
4
5
如图 11-3 所示,当用户点击事件到来时,就对应着动态表中的一次插入(Insert)操作,每条数据就是表中的一行;随着插入更多的点击事件,得到的动态表将不断增长。
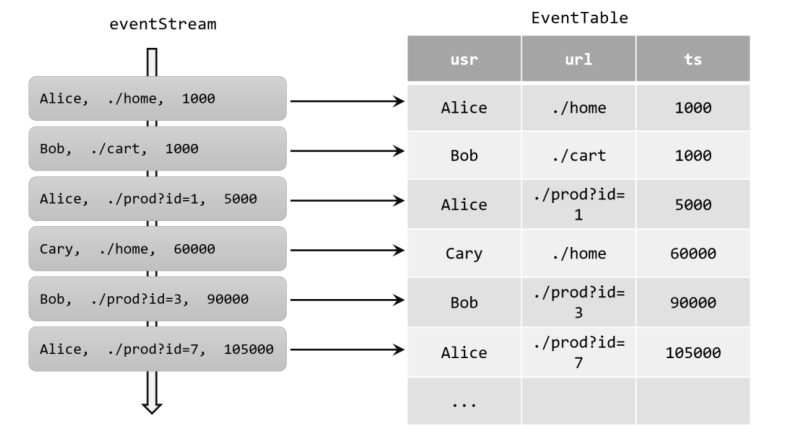
# 用 SQL 持续查询
# 更新(Update)查询
我们在代码中定义了一个 SQL 查询。
Table urlCountTable = tableEnv.sqlQuery("SELECT user, COUNT(url) as cnt FROM EventTable GROUP BY user");
这个查询很简单,主要是分组聚合统计每个用户的点击次数。我们把原始的动态表注册为EventTable,经过查询转换后得到 urlCountTable;这个结果动态表中包含两个字段,具体定义如下:
[
user: VARCHAR, // 用户名
cnt: BIGINT // 用户访问 url 的次数
]
2
3
4
如图 11-4 所示,当原始动态表不停地插入新的数据时,查询得到的 urlCountTable 会持续地进行更改。由于 count 数量可能会叠加增长,因此这里的更改操作可以是简单的插入(Insert),也可以是对之前数据的更新(Update)。换句话说,用来定义结果表的更新日志(changelog)流中,包含了 INSERT 和 UPDATE 两种操作。这种持续查询被称为更新查询(Update Query),更新查询得到的结果表如果想要转换成 DataStream,必须调用 toChangelogStream()方法。

具体步骤解释如下:
- 当查询启动时,原始动态表 EventTable 为空;
- 当第一行 Alice 的点击数据插入 EventTable 表时,查询开始计算结果表,urlCountTable中插入一行数据[Alice,1]。
- 当第二行 Bob 点击数据插入 EventTable 表时,查询将更新结果表并插入新行[Bob,1]。
- 第三行数据到来,同样是 Alice 的点击事件,这时不会插入新行,而是生成一个针对已有行的更新操作。这样,结果表中第一行[Alice,1]就更新为[Alice,2]。
- 当第四行 Cary 的点击数据插入到 EventTable 表时,查询将第三行[Cary,1]插入到结果表中。
# 追加(Append)查询
上面的例子中,查询过程用到了分组聚合,结果表中就会产生更新操作。如果我们执行一个简单的条件查询,结果表中就会像原始表 EventTable 一样,只有插入(Insert)操作了。
Table aliceVisitTable = tableEnv.sqlQuery("SELECT url, user FROM EventTable WHERE user = 'Cary'");
这样的持续查询,就被称为追加查询(Append Query),它定义的结果表的更新日志(changelog)流中只有 INSERT 操作。追加查询得到的结果表,转换成 DataStream 调用方法没有限制,可以直接用 toDataStream(),也可以像更新查询一样调用 toChangelogStream()。
这样看来,我们似乎可以总结一个规律:只要用到了聚合,在之前的结果上有叠加,就会产生更新操作,就是一个更新查询。但事实上,更新查询的判断标准是结果表中的数据是否会有 UPDATE 操作,如果聚合的结果不再改变,那么同样也不是更新查询。
什么时候聚合的结果会保持不变呢?一个典型的例子就是窗口聚合。
我们考虑开一个滚动窗口,统计每一小时内所有用户的点击次数,并在结果表中增加一个endT 字段,表示当前统计窗口的结束时间。这时结果表的字段定义如下:
[
user: VARCHAR, // 用户名
endT: TIMESTAMP, // 窗口结束时间
cnt: BIGINT // 用户访问 url 的次数
]
2
3
4
5
如图 11-5 所示,与之前的分组聚合一样,当原始动态表不停地插入新的数据时,查询得到的结果 result 会持续地进行更改。比如时间戳在 12:00:00 到 12:59:59 之间的有四条数据,其中 Alice 三次点击、Bob 一次点击;所以当水位线达到 13:00:00 时窗口关闭,输出到结果表中的就是新增两条数据[Alice, 13:00:00, 3]和[Bob, 13:00:00, 1]。同理,当下一小时的窗口关闭时,也会将统计结果追加到 result 表后面,而不会更新之前的数据。
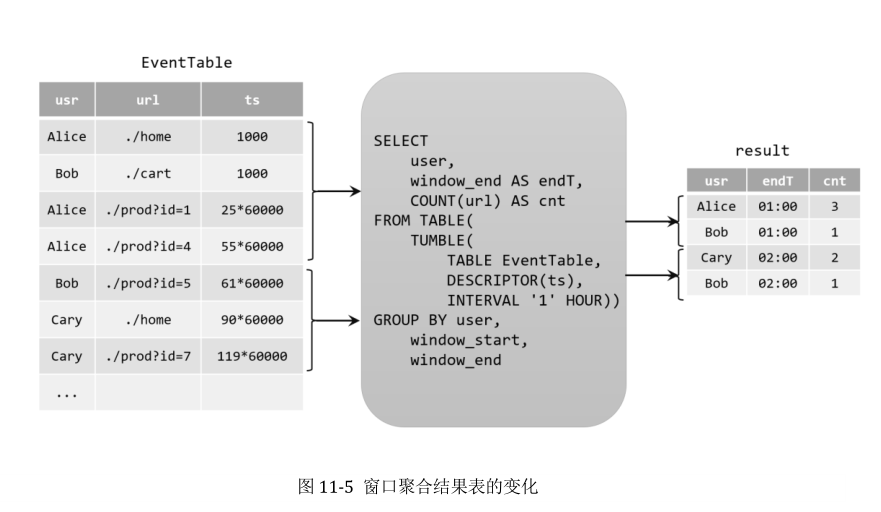
所以我们发现,由于窗口的统计结果是一次性写入结果表的,所以结果表的更新日志流中只会包含插入 INSERT 操作,而没有更新 UPDATE 操作。所以这里的持续查询,依然是一个追加(Append)查询。结果表 result 如果转换成 DataStream,可以直接调用 toDataStream()方法。
需要注意的是,由于涉及时间窗口,我们还需要为事件时间提取时间戳和生成水位线。完整代码如下:
public class Demo_04_AppendQuery {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
SingleOutputStreamOperator<Event> stream = env.fromElements(
new Event("Alice", "./home", 1000L),
new Event("Bob", "./cart", 1000L),
new Event("Alice", "./prod?id=1", 25 * 60 * 1000L),
new Event("Alice", "./prod?id=4", 55 * 60 * 1000L),
new Event("Bob", "./prod?id=5", 3600 * 1000L + 60 * 1000L),
new Event("Cary", "./home", 3600 * 1000L + 30 * 60 * 1000L),
new Event("Cary", "./prod?id=7", 3600 * 1000L + 59 * 60 * 1000L)
)
.assignTimestampsAndWatermarks(
WatermarkStrategy.<Event>forBoundedOutOfOrderness(Duration.ZERO)
.withTimestampAssigner(new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event event, long l) {
return event.timestamp;
}
})
);
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
// 将数据流转换成表,并指定时间属性
Table eventTable = tableEnv.fromDataStream(
stream,
$("user"),
$("url"),
$("timestamp").rowtime().as("ts")
// 将 timestamp 指定为事件时间,并命名为 ts
);
// 为方便在 SQL 中引用,在环境中注册表 EventTable
tableEnv.createTemporaryView("EventTable", eventTable);
// 设置 1 小时滚动窗口,执行 SQL 统计查询
Table result = tableEnv
.sqlQuery(
"SELECT " +
"user, " +
"window_end AS endT, " + // 窗口结束时间
"COUNT(url) AS cnt " + // 统计 url 访问次数
"FROM TABLE( " +
"TUMBLE( TABLE EventTable, " + // 1 小时滚动窗口
"DESCRIPTOR(ts), " +
"INTERVAL '1' HOUR)) " +
"GROUP BY user, window_start, window_end "
);
tableEnv.toDataStream(result).print();
env.execute();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
+I[Alice, 1970-01-01T01:00, 3]
+I[Bob, 1970-01-01T01:00, 1]
+I[Cary, 1970-01-01T02:00, 2]
+I[Bob, 1970-01-01T02:00, 1]
2
3
4
可以看到,所有输出结果都以+I 为前缀,表示都是以 INSERT 操作追加到结果表中的;这是一个追加查询,所以我们直接使用 toDataStream()转换成流是没有问题的。这里输出的window_end 是一个 TIMESTAMP 类型;由于我们直接以一个长整型数作为事件发生的时间戳,所以可以看到对应的都是 1970 年 1 月 1 日的时间。
关于 Table API 和 SQL 中窗口和聚合查询的使用,我们会在后面详细讲解。
# 查询限制
在实际应用中,有些持续查询会因为计算代价太高而受到限制。所谓的“代价太高”,可能是由于需要维护的状态持续增长,也可能是由于更新数据的计算太复杂。
状态大小
用持续查询做流处理,往往会运行至少几周到几个月;所以持续查询处理的数据总量可能非常大。例如我们之前举的更新查询的例子,需要记录每个用户访问 url 的次数。如果随着时间的推移用户数越来越大,那么要维护的状态也将逐渐增长,最终可能会耗尽存储空间导致查询失败。
SELECT user, COUNT(url) FROM clicks GROUP BY user;1
2
3更新计算
对于有些查询来说,更新计算的复杂度可能很高。每来一条新的数据,更新结果的时候可能需要全部重新计算,并且对很多已经输出的行进行更新。一个典型的例子就是 RANK()函数,它会基于一组数据计算当前值的排名。例如下面的 SQL 查询,会根据用户最后一次点击的时间为每个用户计算一个排名。当我们收到一个新的数据,用户的最后一次点击时间(lastAction)就会更新,进而所有用户必须重新排序计算一个新的排名。当一个用户的排名发生改变时,被他超过的那些用户的排名也会改变;这样的更新操作无疑代价巨大,而且还会随着用户的增多越来越严重。
SELECT user, RANK() OVER (ORDER BY lastAction) FROM ( SELECT user, MAX(ts) AS lastAction FROM EventTable GROUP BY user );1
2
3
4这样的查询操作,就不太适合作为连续查询在流处理中执行。这里 RANK()的使用要配合一个 OVER 子句,这是所谓的“开窗聚合”,我们会在 11.5 节展开介绍。
# 将动态表转换为流
与关系型数据库中的表一样,动态表也可以通过插入(Insert)、更新(Update)和删除(Delete)操作,进行持续的更改。将动态表转换为流或将其写入外部系统时,就需要对这些更改操作进行编码,通过发送编码消息的方式告诉外部系统要执行的操作。在 Flink 中,Table API 和 SQL支持三种编码方式:
仅追加(Append-only)流
仅通过插入(Insert)更改来修改的动态表,可以直接转换为“仅追加”流。这个流中发出的数据,其实就是动态表中新增的每一行。
撤回(Retract)流
撤回流是包含两类消息的流,添加(add)消息和撤回(retract)消息。
具体的编码规则是:INSERT 插入操作编码为 add 消息;DELETE 删除操作编码为 retract消息;而 UPDATE 更新操作则编码为被更改行的 retract 消息,和更新后行(新行)的 add 消息。这样,我们可以通过编码后的消息指明所有的增删改操作,一个动态表就可以转换为撤回流了。
可以看到,更新操作对于撤回流来说,对应着两个消息:之前数据的撤回(删除)和新数据的插入。
如图 11-6 所示,显示了将动态表转换为撤回流的过程。

这里我们用+代表 add 消息(对应插入 INSERT 操作),用-代表 retract 消息(对应删除DELETE 操作);当 Alice 的第一个点击事件到来时,结果表新增一条数据[Alice, 1];而当 Alice的第二个点击事件到来时,结果表会将[Alice, 1]更新为[Alice, 2],对应的编码就是删除[Alice, 1]、插入[Alice, 2]。这样当一个外部系统收到这样的两条消息时,就知道是要对 Alice 的点击统计次数进行更新了。
更新插入(Upsert)流
更新插入流中只包含两种类型的消息:更新插入(upsert)消息和删除(delete)消息。所谓的“upsert”其实是“update”和“insert”的合成词,所以对于更新插入流来说,INSERT 插入操作和UPDATE更新操作,统一被编码为upsert消息;而DELETE删除操作则被编码为delete消息。
既然更新插入流中不区分插入(insert)和更新(update),那我们自然会想到一个问题:如果希望更新一行数据时,怎么保证最后做的操作不是插入呢?
这就需要动态表中必须有唯一的键(key)。通过这个 key 进行查询,如果存在对应的数据就做更新(update),如果不存在就直接插入(insert)。这是一个动态表可以转换为更新插入流的必要条件。当然,收到这条流中数据的外部系统,也需要知道这唯一的键(key),这样才能正确地处理消息。
可以看到,更新插入流跟撤回流的主要区别在于,更新(update)操作由于有 key 的存在,只需要用单条消息编码就可以,因此效率更高。
需要注意的是,在代码里将动态表转换为 DataStream 时,只支持仅追加(append-only)和撤回(retract)流,我们调用 toChangelogStream()得到的其实就是撤回流;这也很好理解,DataStream 中并没有 key 的定义,所以只能通过两条消息一减一增来表示更新操作。而连接到外部系统时,则可以支持不同的编码方法,这取决于外部系统本身的特性。
# 时间属性和窗口
基于时间的操作(比如时间窗口),需要定义相关的时间语义和时间数据来源的信息。在Table API 和 SQL 中,会给表单独提供一个逻辑上的时间字段,专门用来在表处理程序中指示时间。
所以所谓的时间属性(time attributes),其实就是每个表模式结构(schema)的一部分。它可以在创建表的 DDL 里直接定义为一个字段,也可以在 DataStream 转换成表时定义。一旦定义了时间属性,它就可以作为一个普通字段引用,并且可以在基于时间的操作中使用。
时间属性的数据类型为 TIMESTAMP,它的行为类似于常规时间戳,可以直接访问并且进行计算。
按照时间语义的不同,我们可以把时间属性的定义分成事件时间(event time)和处理时间(processing time)两种情况。
# 事件时间
我们在实际应用中,最常用的就是事件时间。在事件时间语义下,允许表处理程序根据每个数据中包含的时间戳(也就是事件发生的时间)来生成结果。
事件时间语义最大的用途就是处理乱序事件或者延迟事件的场景。我们通过设置水位线(watermark)来表示事件时间的进展,而水位线可以根据数据的最大时间戳设置一个延迟时间。这样即使在出现乱序的情况下,对数据的处理也可以获得正确的结果。
为了处理无序事件,并区分流中的迟到事件。Flink 需要从事件数据中提取时间戳,并生成水位线,用来推进事件时间的进展。
事件时间属性可以在创建表 DDL 中定义,也可以在数据流和表的转换中定义。
# 在创建表的 DDL 中定义
在创建表的 DDL(CREATE TABLE 语句)中,可以增加一个字段,通过 WATERMARK语句来定义事件时间属性。WATERMARK 语句主要用来定义水位线(watermark)的生成表达式,这个表达式会将带有事件时间戳的字段标记为事件时间属性,并在它基础上给出水位线的延迟时间。具体定义方式如下:
CREATE TABLE EventTable(
user STRING,
url STRING,
ts TIMESTAMP(3),
WATERMARK FOR ts AS ts - INTERVAL '5' SECOND
) WITH (
...
);
2
3
4
5
6
7
8
这里我们把 ts 字段定义为事件时间属性,而且基于 ts 设置了 5 秒的水位线延迟。这里的“5 秒”是以“时间间隔”的形式定义的,格式是 INTERVAL <数值> <时间单位>:
INTERVAL '5' SECOND
这里的数值必须用单引号引起来,而单位用 SECOND 和 SECONDS 是等效的
Flink 中支持的事件时间属性数据类型必须为 TIMESTAMP 或者 TIMESTAMP_LTZ。这里TIMESTAMP_LTZ 是指带有本地时区信息的时间戳(TIMESTAMP WITH LOCAL TIMEZONE);一般情况下如果数据中的时间戳是“年-月-日-时-分-秒”的形式,那就是不带时区信息的,可以将事件时间属性定义为 TIMESTAMP 类型。
而如果原始的时间戳就是一个长整型的毫秒数,这时就需要另外定义一个字段来表示事件时间属性,类型定义为 TIMESTAMP_LTZ 会更方便:
CREATE TABLE events (
user STRING,
url STRING,
ts BIGINT,
ts_ltz AS TO_TIMESTAMP_LTZ(ts, 3),
WATERMARK FOR ts_ltz AS time_ltz - INTERVAL '5' SECOND
) WITH (
...
);
2
3
4
5
6
7
8
9
这里我们另外定义了一个字段 ts_ltz,是把长整型的 ts 转换为 TIMESTAMP_LTZ 得到的;进而使用 WATERMARK 语句将它设为事件时间属性,并设置 5 秒的水位线延迟。
# 在数据流转换为表时定义
事件时间属性也可以在将 DataStream 转换为表的时候来定义。我们调用 fromDataStream()方法创建表时,可以追加参数来定义表中的字段结构;这时可以给某个字段加上.rowtime() 后缀,就表示将当前字段指定为事件时间属性。这个字段可以是数据中本不存在、额外追加上去的“逻辑字段”,就像之前 DDL 中定义的第二种情况;也可以是本身固有的字段,那么这个字段就会被事件时间属性所覆盖,类型也会被转换为 TIMESTAMP。不论那种方式,时间属性字段中保存的都是事件的时间戳(TIMESTAMP 类型)。
需要注意的是,这种方式只负责指定时间属性,而时间戳的提取和水位线的生成应该之前就在 DataStream 上定义好了。由于 DataStream 中没有时区概念,因此 Flink 会将事件时间属性解析成不带时区的 TIMESTAMP 类型,所有的时间值都被当作 UTC 标准时间。
在代码中的定义方式如下:
// 方法一:
// 流中数据类型为二元组 Tuple2,包含两个字段;需要自定义提取时间戳并生成水位线
DataStream<Tuple2<String, String>> stream =
inputStream.assignTimestampsAndWatermarks(...);
// 声明一个额外的逻辑字段作为事件时间属性
Table table = tEnv.fromDataStream(stream, $("user"), $("url"),$("ts").rowtime());
// 方法二:
// 流中数据类型为三元组 Tuple3,最后一个字段就是事件时间戳
DataStream<Tuple3<String, String, Long>> stream =
inputStream.assignTimestampsAndWatermarks(...);
// 不再声明额外字段,直接用最后一个字段作为事件时间属性
Table table = tEnv.fromDataStream(stream, $("user"), $("url"),$("ts").rowtime());
2
3
4
5
6
7
8
9
10
11
12
13
14
# 处理时间
相比之下处理时间就比较简单了,它就是我们的系统时间,使用时不需要提取时间戳(timestamp)和生成水位线(watermark)。因此在定义处理时间属性时,必须要额外声明一个字段,专门用来保存当前的处理时间。
类似地,处理时间属性的定义也有两种方式:创建表 DDL 中定义,或者在数据流转换成表时定义。
# 在创建表的 DDL 中定义
在创建表的 DDL(CREATE TABLE 语句)中,可以增加一个额外的字段,通过调用系统内置的 PROCTIME()函数来指定当前的处理时间属性,返回的类型是 TIMESTAMP_LTZ。
CREATE TABLE EventTable(
user STRING,
url STRING,
ts AS PROCTIME()
) WITH (
...
);
2
3
4
5
6
7
这里的时间属性,其实是以“计算列”(computed column)的形式定义出来的。所谓的计算列是 Flink SQL 中引入的特殊概念,可以用一个 AS 语句来在表中产生数据中不存在的列,并且可以利用原有的列、各种运算符及内置函数。在前面事件时间属性的定义中,将 ts 字段转换成 TIMESTAMP_LTZ 类型的 ts_ltz,也是计算列的定义方式。
# 在数据流转换为表时定义
处 理 时 间 属 性 同 样 可 以 在 将 DataStream 转 换 为 表 的 时 候 来 定 义 。 我 们 调 用fromDataStream()方法创建表时,可以用.proctime()后缀来指定处理时间属性字段。由于处理时间是系统时间,原始数据中并没有这个字段,所以处理时间属性一定不能定义在一个已有字段上,只能定义在表结构所有字段的最后,作为额外的逻辑字段出现。
DataStream<Tuple2<String, String>> stream = ...;
// 声明一个额外的字段作为处理时间属性字段
Table table = tEnv.fromDataStream(stream, $("user"), $("url"),$("ts").proctime());
2
3
# 11.4.3 窗口(Window)
有了时间属性,接下来就可以定义窗口进行计算了。我们知道,窗口可以将无界流切割成大小有限的“桶”(bucket)来做计算,通过截取有限数据集来处理无限的流数据。在 DataStreamAPI 中提供了对不同类型的窗口进行定义和处理的接口,而在 Table API 和 SQL 中,类似的功能也都可以实现。
# 分组窗口(Group Window,老版本)
在 Flink 1.12 之前的版本中,Table API 和 SQL 提供了一组“分组窗口”(Group Window)函数,常用的时间窗口如滚动窗口、滑动窗口、会话窗口都有对应的实现;具体在 SQL 中就是调用 TUMBLE()、HOP()、SESSION(),传入时间属性字段、窗口大小等参数就可以了。以滚动窗口为例:
TUMBLE(ts, INTERVAL '1' HOUR)
这里的 ts 是定义好的时间属性字段,窗口大小用“时间间隔”INTERVAL 来定义。
在进行窗口计算时,分组窗口是将窗口本身当作一个字段对数据进行分组的,可以对组内的数据进行聚合。基本使用方式如下:
Table result = tableEnv.sqlQuery(
"SELECT " +
"user, " +
"TUMBLE_END(ts, INTERVAL '1' HOUR) as endT, " +
"COUNT(url) AS cnt " +
"FROM EventTable " +
"GROUP BY " + // 使用窗口和用户名进行分组
"user, " +
"TUMBLE(ts, INTERVAL '1' HOUR)" // 定义 1 小时滚动窗口
);
2
3
4
5
6
7
8
9
10
这里定义了 1 小时的滚动窗口,将窗口和用户 user 一起作为分组的字段。用聚合函数COUNT()对分组数据的个数进行了聚合统计,并将结果字段重命名为cnt;用TUPMBLE_END()函数获取滚动窗口的结束时间,重命名为 endT 提取出来。
分组窗口的功能比较有限,只支持窗口聚合,所以目前已经处于弃用(deprecated)的状态。
# 窗口表值函数(Windowing TVFs,新版本)
从 1.13 版本开始,Flink 开始使用窗口表值函数(Windowing table-valued functions,Windowing TVFs)来定义窗口。窗口表值函数是 Flink 定义的多态表函数(PTF),可以将表进行扩展后返回。表函数(table function)可以看作是返回一个表的函数,关于这部分内容,我们会在 11.6 节进行介绍。
目前 Flink 提供了以下几个窗口 TVF:
- 滚动窗口(Tumbling Windows);
- 滑动窗口(Hop Windows,跳跃窗口);
- 累积窗口(Cumulate Windows);
- 会话窗口(Session Windows,目前尚未完全支持)。
窗口表值函数可以完全替代传统的分组窗口函数。窗口 TVF 更符合 SQL 标准,性能得到了优化,拥有更强大的功能;可以支持基于窗口的复杂计算,例如窗口Top-N、窗口联结(window join)等等。当然,目前窗口 TVF 的功能还不完善,会话窗口和很多高级功能还不支持,不过正在快速地更新完善。可以预见在未来的版本中,窗口 TVF 将越来越强大,将会是窗口处理的唯一入口。
在窗口 TVF 的返回值中,除去原始表中的所有列,还增加了用来描述窗口的额外 3 个列:“窗口起始点”(window_start)、“窗口结束点”(window_end)、“窗口时间”(window_time)。起始点和结束点比较好理解,这里的“窗口时间”指的是窗口中的时间属性,它的值等于window_end - 1ms,所以相当于是窗口中能够包含数据的最大时间戳。
在 SQL 中的声明方式,与以前的分组窗口是类似的,直接调用 TUMBLE()、HOP()、CUMULATE()就可以实现滚动、滑动和累积窗口,不过传入的参数会有所不同。下面我们就分别对这几种窗口 TVF 进行介绍。
滚动窗口(TUMBLE)
滚动窗口在 SQL 中的概念与 DataStream API 中的定义完全一样,是长度固定、时间对齐、无重叠的窗口,一般用于周期性的统计计算。
在 SQL 中通过调用 TUMBLE()函数就可以声明一个滚动窗口,只有一个核心参数就是窗口大小(size)。在 SQL 中不考虑计数窗口,所以滚动窗口就是滚动时间窗口,参数中还需要将当前的时间属性字段传入;另外,窗口 TVF 本质上是表函数,可以对表进行扩展,所以还应该把当前查询的表作为参数整体传入。具体声明如下:
TUMBLE(TABLE EventTable, DESCRIPTOR(ts), INTERVAL '1' HOUR)1这里基于时间字段 ts,对表 EventTable 中的数据开了大小为 1 小时的滚动窗口。窗口会将表中的每一行数据,按照它们 ts 的值分配到一个指定的窗口中。
滑动窗口(HOP)
滑动窗口的使用与滚动窗口类似,可以通过设置滑动步长来控制统计输出的频率。在 SQL中通过调用 HOP()来声明滑动窗口;除了也要传入表名、时间属性外,还需要传入窗口大小(size)和滑动步长(slide)两个参数。
HOP(TABLE EventTable, DESCRIPTOR(ts), INTERVAL '5' MINUTES, INTERVAL '1' HOURS));1这里我们基于时间属性 ts,在表 EventTable 上创建了大小为 1 小时的滑动窗口,每 5 分钟滑动一次。需要注意的是,紧跟在时间属性字段后面的第三个参数是步长(slide),第四个参数才是窗口大小(size)。
累积窗口(CUMULATE)
滚动窗口和滑动窗口,可以用来计算大多数周期性的统计指标。不过在实际应用中还会遇到这样一类需求:我们的统计周期可能较长,因此希望中间每隔一段时间就输出一次当前的统计值;与滑动窗口不同的是,在一个统计周期内,我们会多次输出统计值,它们应该是不断叠加累积的。
例如,我们按天来统计网站的 PV(Page View,页面浏览量),如果用 1 天的滚动窗口,那需要到每天 24 点才会计算一次,输出频率太低;如果用滑动窗口,计算频率可以更高,但统计的就变成了“过去 24 小时的 PV”。所以我们真正希望的是,还是按照自然日统计每天的PV,不过需要每隔 1 小时就输出一次当天到目前为止的 PV 值。这种特殊的窗口就叫作“累积窗口”(Cumulate Window)。

累积窗口是窗口 TVF 中新增的窗口功能,它会在一定的统计周期内进行累积计算。累积窗口中有两个核心的参数:最大窗口长度(max window size)和累积步长(step)。所谓的最大窗口长度其实就是我们所说的“统计周期”,最终目的就是统计这段时间内的数据。如图 11-8所示,开始时,创建的第一个窗口大小就是步长 step;之后的每个窗口都会在之前的基础上再扩展 step 的长度,直到达到最大窗口长度。在 SQL 中可以用 CUMULATE()函数来定义,具体如下:
CUMULATE(TABLE EventTable, DESCRIPTOR(ts), INTERVAL '1' HOURS, INTERVAL '1' DAYS))1这里我们基于时间属性 ts,在表 EventTable 上定义了一个统计周期为 1 天、累积步长为 1小时的累积窗口。注意第三个参数为步长 step,第四个参数则是最大窗口长度。
上面所有的语句只是定义了窗口,类似于 DataStream API 中的窗口分配器;在 SQL 中窗口的完整调用,还需要配合聚合操作和其它操作。我们会在下一节详细讲解窗口的聚合。
# 聚合(Aggregation)查询
在 SQL 中,一个很常见的功能就是对某一列的多条数据做一个合并统计,得到一个或多个结果值;比如求和、最大最小值、平均值等等,这种操作叫作聚合(Aggregation)查询。Flink 中的 SQL 是流处理与标准 SQL 结合的产物,所以聚合查询也可以分成两种:流处理中特有的聚合(主要指窗口聚合),以及 SQL 原生的聚合查询方式。
# 分组聚合
SQL 中一般所说的聚合我们都很熟悉,主要是通过内置的一些聚合函数来实现的,比如SUM()、MAX()、MIN()、AVG()以及 COUNT()。它们的特点是对多条输入数据进行计算,得到一个唯一的值,属于“多对一”的转换。比如我们可以通过下面的代码计算输入数据的个数:
Table eventCountTable = tableEnv.sqlQuery("select COUNT(*) from EventTable");
而更多的情况下,我们可以通过 GROUP BY 子句来指定分组的键(key),从而对数据按照某个字段做一个分组统计。例如之前我们举的例子,可以按照用户名进行分组,统计每个用户点击 url 的次数:
SELECT user, COUNT(url) as cnt FROM EventTable GROUP BY user
这种聚合方式,就叫作“分组聚合”(group aggregation)。从概念上讲,SQL 中的分组聚合可以对应 DataStream API 中 keyBy 之后的聚合转换,它们都是按照某个 key 对数据进行了划分,各自维护状态来进行聚合统计的。在流处理中,分组聚合同样是一个持续查询,而且是一个更新查询,得到的是一个动态表;每当流中有一个新的数据到来时,都会导致结果表的更新操作。因此,想要将结果表转换成流或输出到外部系统,必须采用撤回流(retract stream)或更新插入流(upsert stream)的编码方式;如果在代码中直接转换成 DataStream 打印输出,需要调用 toChangelogStream()。
另外,在持续查询的过程中,由于用于分组的 key 可能会不断增加,因此计算结果所需要维护的状态也会持续增长。为了防止状态无限增长耗尽资源,Flink Table API 和 SQL 可以在表环境中配置状态的生存时间(TTL):
TableEnvironment tableEnv = ...
// 获取表环境的配置
TableConfig tableConfig = tableEnv.getConfig();
// 配置状态保持时间
tableConfig.setIdleStateRetention(Duration.ofMinutes(60));
2
3
4
5
或者也可以直接设置配置项 table.exec.state.ttl:
TableEnvironment tableEnv = ...
Configuration configuration = tableEnv.getConfig().getConfiguration();
configuration.setString("table.exec.state.ttl", "60 min");
2
3
这两种方式是等效的。需要注意,配置 TTL 有可能会导致统计结果不准确,这其实是以牺牲正确性为代价换取了资源的释放。
此外,在 Flink SQL 的分组聚合中同样可以使用 DISTINCT 进行去重的聚合处理;可以使用 HAVING 对聚合结果进行条件筛选;还可以使用 GROUPING SETS(分组集)设置多个分组情况分别统计。这些语法跟标准 SQL 中的用法一致,这里就不再详细展开了。
可以看到,分组聚合既是 SQL 原生的聚合查询,也是流处理中的聚合操作,这是实际应用中最常见的聚合方式。当然,使用的聚合函数一般都是系统内置的,如果希望实现特殊需求也可以进行自定义。关于自定义函数(UDF),我们会在 11.7 节中详细介绍。
# 窗口聚合
在流处理中,往往需要将无限数据流划分成有界数据集,这就是所谓的“窗口”。在 11.4.3小节中已经介绍了窗口的声明方式,这相当于 DataStream API 中的窗口分配器(windowassigner),只是明确了窗口的形式以及数据如何分配;而窗口具体的计算处理操作,在DataStream API 中还需要窗口函数(window function)来进行定义。
在 Flink 的 Table API 和 SQL 中,窗口的计算是通过“窗口聚合”(window aggregation)来实现的。与分组聚合类似,窗口聚合也需要调用 SUM()、MAX()、MIN()、COUNT()一类的聚合函数,通过 GROUP BY 子句来指定分组的字段。只不过窗口聚合时,需要将窗口信息作为分组 key 的一部分定义出来。在 Flink 1.12 版本之前,是直接把窗口自身作为分组 key 放在GROUP BY 之后的,所以也叫“分组窗口聚合”(参见 11.4.3 小节);而 1.13 版本开始使用了“窗口表值函数” (Windowing TVF),窗口本身返回的是就是一个表,所以窗口会出现在 FROM后面,GROUP BY 后面的则是窗口新增的字段 window_start 和 window_end。
比如,我们将 11.4.3 中分组窗口的聚合,用窗口 TVF 重新实现一下:
Table result = tableEnv.sqlQuery(
"SELECT " +
"user, " +
"window_end AS endT, " +
"COUNT(url) AS cnt " +
"FROM TABLE( " +
"TUMBLE( TABLE EventTable, " +
"DESCRIPTOR(ts), " +
"INTERVAL '1' HOUR)) " +
"GROUP BY user, window_start, window_end "
);
2
3
4
5
6
7
8
9
10
11
这里我们以 ts 作为时间属性字段、基于 EventTable 定义了 1 小时的滚动窗口,希望统计出每小时每个用户点击 url 的次数。用来分组的字段是用户名 user,以及表示窗口的window_start 和 window_end;而 TUMBLE()是表值函数,所以得到的是一个表(Table),我们的聚合查询就是在这个 Table 中进行的。这就是 11.3.2 小节中窗口聚合的实现方式。
Flink SQL 目前提供了滚动窗口 TUMBLE()、滑动窗口 HOP()和累积窗口(CUMULATE)三种表值函数(TVF)。在具体应用中,我们还需要提前定义好时间属性。下面是一段窗口聚合的完整代码,以累积窗口为例:
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import static org.apache.flink.table.api.Expressions.$;
public class CumulateWindowExample {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 读取数据源,并分配时间戳、生成水位线
SingleOutputStreamOperator<Event> eventStream = env
.fromElements(
new Event("Alice", "./home", 1000L),
new Event("Bob", "./cart", 1000L),
new Event("Alice", "./prod?id=1", 25 * 60 * 1000L),
new Event("Alice", "./prod?id=4", 55 * 60 * 1000L),
new Event("Bob", "./prod?id=5", 3600 * 1000L + 60 * 1000L),
new Event("Cary", "./home", 3600 * 1000L + 30 * 60 * 1000L),
new Event("Cary", "./prod?id=7", 3600 * 1000L + 59 * 60 * 1000L)
)
.assignTimestampsAndWatermarks(
WatermarkStrategy.<Event>forMonotonousTimestamps()
.withTimestampAssigner(new
SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event element, long
recordTimestamp) {
return element.timestamp;
}
})
);
// 创建表环境
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
// 将数据流转换成表,并指定时间属性
Table eventTable = tableEnv.fromDataStream(
eventStream,
$("user"),
$("url"),
$("timestamp").rowtime().as("ts")
);
// 为方便在 SQL 中引用,在环境中注册表 EventTable
tableEnv.createTemporaryView("EventTable", eventTable);
// 设置累积窗口,执行 SQL 统计查询
Table result = tableEnv
.sqlQuery(
"SELECT " +
"user, " +
"window_end AS endT, " +
"COUNT(url) AS cnt " +
"FROM TABLE( " +
"CUMULATE( TABLE EventTable, " + // 定义累积窗口
"DESCRIPTOR(ts), " +
"INTERVAL '30' MINUTE, " +
"INTERVAL '1' HOUR)) " +
"GROUP BY user, window_start, window_end "
);
tableEnv.toDataStream(result).print();
env.execute();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
这里我们使用了统计周期为 1 小时、累积间隔为 30 分钟的累积窗口。可以看到,代码的架构和处理逻辑与 11.3.2 小节中的实现完全一致,只是将滚动窗口 TUMBLE()换成了累积窗口CUMULATE()。代码执行结果如下:
+I[Alice, 1970-01-01T00:30, 2]
+I[Bob, 1970-01-01T00:30, 1]
+I[Alice, 1970-01-01T01:00, 3]
+I[Bob, 1970-01-01T01:00, 1]
+I[Bob, 1970-01-01T01:30, 1]
+I[Cary, 1970-01-01T02:00, 2]
+I[Bob, 1970-01-01T02:00, 1]
2
3
4
5
6
7
与分组聚合不同,窗口聚合不会将中间聚合的状态输出,只会最后输出一个结果。我们可以看到,所有数据都是以 INSERT 操作追加到结果动态表中的,因此输出每行前面都有+I 的前缀。所以窗口聚合查询都属于追加查询,没有更新操作,代码中可以直接用 toDataStream()将结果表转换成流。
具体来看,上面代码输入的前三条数据属于第一个半小时的累积窗口,其中 Alice 的访问数据有两条,Bob 的访问数据有 1 条,所以输出了两条结果[Alice, 1970-01-01T00:30, 2]和[Bob,1970-01-01T00:30, 1];而之后又到来的一条 Alice 访问数据属于第二个半小时范围,同时也属于第一个 1 小时的统计周期,所以会在之前两条的基础上进行叠加,输出[Alice,1970-01-01T00:30, 3],而 Bob 没有新的访问数据,因此依然输出[Bob, 1970-01-01T00:30, 1]。从第二个小时起,数据属于新的统计周期,就全部从零开始重新计数了。
相比之前的分组窗口聚合,Flink 1.13 版本的窗口表值函数(TVF)聚合有更强大的功能。除了应用简单的聚合函数、提取窗口开始时间(window_start)和结束时间(window_end)之外,窗口 TVF 还提供了一个 window_time 字段,用于表示窗口中的时间属性;这样就可以方便地进行窗口的级联(cascading window)和计算了。另外,窗口 TVF 还支持 GROUPING SETS,极大地扩展了窗口的应用范围。
基于窗口的聚合,是流处理中聚合统计的一个特色,也是与标准 SQL 最大的不同之处。在实际项目中,很多统计指标其实都是基于时间窗口来进行计算的,所以窗口聚合是 Flink SQL中非常重要的功能;基于窗口 TVF 的聚合未来也会有更多功能的扩展支持,比如窗口 Top N、会话窗口、窗口联结等等。
# 开窗(Over)聚合
在标准 SQL 中还有另外一类比较特殊的聚合方式,可以针对每一行计算一个聚合值。比如说,我们可以以每一行数据为基准,计算它之前 1 小时内所有数据的平均值;也可以计算它之前 10 个数的平均值。就好像是在每一行上打开了一扇窗户、收集数据进行统计一样,这就是所谓的“开窗函数”。开窗函数的聚合与之前两种聚合有本质的不同:分组聚合、窗口 TVF聚合都是“多对一”的关系,将数据分组之后每组只会得到一个聚合结果;而开窗函数是对每行都要做一次开窗聚合,因此聚合之后表中的行数不会有任何减少,是一个“多对多”的关系。
与标准 SQL 中一致,Flink SQL 中的开窗函数也是通过 OVER 子句来实现的,所以有时开窗聚合也叫作“OVER 聚合”(Over Aggregation)。基本语法如下:
SELECT
<聚合函数> OVER (
[PARTITION BY <字段 1>[, <字段 2>, ...]]
ORDER BY <时间属性字段>
<开窗范围>),
...
FROM ...
2
3
4
5
6
7
这里 OVER 关键字前面是一个聚合函数,它会应用在后面 OVER 定义的窗口上。在 OVER子句中主要有以下几个部分:
PARTITION BY(可选)
用来指定分区的键(key),类似于 GROUP BY 的分组,这部分是可选的;
ORDER BY
OVER 窗口是基于当前行扩展出的一段数据范围,选择的标准可以基于时间也可以基于数量。不论那种定义,数据都应该是以某种顺序排列好的;而表中的数据本身是无序的。所以在OVER 子句中必须用 ORDER BY 明确地指出数据基于那个字段排序。在 Flink 的流处理中,目前只支持按照时间属性的升序排列,所以这里 ORDER BY 后面的字段必须是定义好的时间属性。
开窗范围
对于开窗函数而言,还有一个必须要指定的就是开窗的范围,也就是到底要扩展多少行来做聚合。这个范围是由 BETWEEN <下界> AND <上界> 来定义的,也就是“从下界到上界”的范围。目前支持的上界只能是 CURRENT ROW,也就是定义一个“从之前某一行到当前行”的范围,所以一般的形式为:
BETWEEN ... PRECEDING AND CURRENT ROW1前面我们提到,开窗选择的范围可以基于时间,也可以基于数据的数量。所以开窗范围还应该在两种模式之间做出选择:范围间隔(RANGE intervals)和行间隔(ROW intervals)。
范围间隔
范围间隔以 RANGE 为前缀,就是基于 ORDER BY 指定的时间字段去选取一个范围,一般就是当前行时间戳之前的一段时间。例如开窗范围选择当前行之前 1 小时的数据:
RANGE BETWEEN INTERVAL '1' HOUR PRECEDING AND CURRENT ROW1行间隔
行间隔以 ROWS 为前缀,就是直接确定要选多少行,由当前行出发向前选取就可以了。例如开窗范围选择当前行之前的 5 行数据(最终聚合会包括当前行,所以一共 6 条数据):
ROWS BETWEEN 5 PRECEDING AND CURRENT ROW1下面是一个具体示例:
SELECT user, ts, COUNT(url) OVER ( PARTITION BY user ORDER BY ts RANGE BETWEEN INTERVAL '1' HOUR PRECEDING AND CURRENT ROW ) AS cnt FROM EventTable1
2
3
4
5
6
7这里我们以 ts 作为时间属性字段,对 EventTable 中的每行数据都选取它之前 1 小时的所有数据进行聚合,统计每个用户访问 url 的总次数,并重命名为 cnt。最终将表中每行的 user,ts 以及扩展出 cnt 提取出来。
可以看到,整个开窗聚合的结果,是对每一行数据都有一个对应的聚合值,因此就像将表中扩展出了一个新的列一样。由于聚合范围上界只能到当前行,新到的数据一般不会影响之前数据的聚合结果,所以结果表只需要不断插入(INSERT)就可以了。执行上面 SQL 得到的结果表,可以用 toDataStream()直接转换成流打印输出。
开窗聚合与窗口聚合(窗口 TVF 聚合)本质上不同,不过也还是有一些相似之处的:它们都是在无界的数据流上划定了一个范围,截取出有限数据集进行聚合统计;这其实都是“窗口”的思路。事实上,在 Table API 中确实就定义了两类窗口:分组窗口(GroupWindow)和开窗窗口(OverWindow);而在 SQL 中,也可以用 WINDOW 子句来在 SELECT 外部单独定义一个 OVER 窗口:
SELECT user, ts, COUNT(url) OVER w AS cnt, MAX(CHAR_LENGTH(url)) OVER w AS max_url FROM EventTable WINDOW w AS ( PARTITION BY user ORDER BY ts ROWS BETWEEN 2 PRECEDING AND CURRENT ROW)1
2
3
4
5
6
7
8上面的 SQL 中定义了一个选取之前 2 行数据的 OVER 窗口,并重命名为 w;接下来就可以基于它调用多个聚合函数,扩展出更多的列提取出来。比如这里除统计 url 的个数外,还统计了 url 的最大长度:首先用 CHAR_LENGTH()函数计算出 url 的长度,再调用聚合函数 MAX()进行聚合统计。这样,我们就可以方便重复引用定义好的 OVER 窗口了,大大增强了代码的可读性。
# 应用实例 —— Top N
灵活使用各种类型的窗口以及聚合函数,可以实现不同的需求。一般的聚合函数,比如SUM()、MAX()、MIN()、COUNT()等,往往只是针对一组数据聚合得到一个唯一的值;所谓OVER 聚合的“多对多”模式,也是针对每行数据都进行一次聚合才得到了多行的结果,对于每次聚合计算实际上得到的还是唯一的值。而有时我们可能不仅仅需要统计数据中的最大/最小值,还希望得到前 N 个最大/最小值;这时每次聚合的结果就不是一行,而是 N 行了。这就是经典的“Top N”应用场景。
Top N 聚合字面意思是“最大 N 个”,这只是一个泛称,它不仅包括查询最大的 N 个值、也包括了查询最小的 N 个值的场景。
理想的状态下,我们应该有一个 TOPN()聚合函数,调用它对表进行聚合就可以得到想要选取的前 N 个值了。不过仔细一想就会发现,这个聚合函数并不容易实现:对于每一次聚合计算,都应该都有多行数据输入,并得到 N 行结果输出,这是一个真正意义上的“多对多”转换。这种函数相当于把一个表聚合成了另一个表,所以叫作“表聚合函数”(Table Aggregate Function)。表聚合函数的抽象比较困难,目前只有窗口 TVF 有能力提供直接的 Top N 聚合,不过也尚未实现。
所以目前在 Flink SQL 中没有能够直接调用的 Top N 函数,而是提供了稍微复杂些的变通实现方法。
# 普通 Top N
在 Flink SQL 中,是通过 OVER 聚合和一个条件筛选来实现 Top N 的。具体来说,是通过将一个特殊的聚合函数ROW_NUMBER()应用到OVER窗口上,统计出每一行排序后的行号,作为一个字段提取出来;然后再用 WHERE 子句筛选行号小于等于 N 的那些行返回。
SELECT ...
FROM (
SELECT ...,
ROW_NUMBER() OVER (
[PARTITION BY <字段 1>[, <字段 1>...]]
ORDER BY <排序字段 1> [asc|desc][, <排序字段 2> [asc|desc]...]
) AS row_num
FROM ...)
WHERE row_num <= N [AND <其它条件>]
2
3
4
5
6
7
8
9
这里的 OVER 窗口定义与之前的介绍基本一致,目的就是利用 ROW_NUMBER()函数为每一行数据聚合得到一个排序之后的行号。行号重命名为 row_num,并在外层的查询中以row_num <= N 作为条件进行筛选,就可以得到根据排序字段统计的 Top N 结果了。
需要对关键字额外做一些说明:
WHERE
用来指定 Top N 选取的条件,这里必须通过 row_num <= N 或者 row_num < N + 1 指定一个“排名结束点”(rank end),以保证结果有界。
PARTITION BY
是可选的,用来指定分区的字段,这样我们就可以针对不同的分组分别统计 Top N 了。
ORDER BY
指定了排序的字段,因为只有排序之后,才能进行前 N 个最大/最小的选取。每个排序字段后可以用 asc 或者 desc 来指定排序规则:asc 为升序排列,取出的就是最小的 N 个值;desc为降序排序,对应的就是最大的 N 个值。默认情况下为升序,asc 可以省略。
细心的读者可能会发现,之前介绍的 OVER 窗口不是说了,目前 ORDER BY 后面只能跟时间字段、并且只支持升序吗?这里怎么又可以任意指定字段进行排序了呢?
这是因为 OVER 窗口目前并不完善,不过针对 Top N 这样一个经典应用场景,Flink SQL专门用 OVER 聚合做了优化实现。所以只有在 Top N 的应用场景中,OVER 窗口 ORDER BY后才可以指定其它排序字段;而要想实现 Top N,就必须按照上面的格式进行定义,否则 FlinkSQL 的优化器将无法正常解析。而且,目前 Table API 中并不支持 ROW_NUMBER()函数,所以也只有 SQL 中这一种通用的 Top N 实现方式。
另外要注意,Top N 的实现必须写成上面的嵌套查询形式。这是因为行号 row_num 是内部子查询聚合的结果,不可能在内部作为筛选条件,只能放在外层的 WHERE 子句中。
下面是一个具体的示例,我们统计每个用户的访问事件中,按照字符长度排序的前两个url
SELECT user, url, ts, row_num FROM ( SELECT *, ROW_NUMBER() OVER ( PARTITION BY user ORDER BY CHAR_LENGTH(url) desc ) AS row_num FROM EventTable) WHERE row_num <= 21
2
3
4
5
6
7
8
9这里我们以用户来分组,以访问 url 的字符长度作为排序的字段,降序排列后用聚合统计出每一行的行号,这样就相当于在 EventTable 基础上扩展出了一列 row_num。而后筛选出行号小于等于 2 的所有数据,就得到了每个用户访问的长度最长的两个 url。
需要特别说明的是,这里的 Top N 聚合是一个更新查询。新数据到来后,可能会改变之前数据的排名,所以会有更新(UPDATE)操作。这是ROW_NUMBER()聚合函数的特性决定的。因此,如果执行上面的 SQL 得到结果表,需要调用 toChangelogStream()才能转换成流打印输出。
# 窗口 Top N
除了直接对数据进行 Top N 的选取,我们也可以针对窗口来做 Top N。
例如电商行业,实际应用中往往有这样的需求:统计一段时间内的热门商品。这就需要先开窗口,在窗口中统计每个商品的点击量;然后将统计数据收集起来,按窗口进行分组,并按点击量大小降序排序,选取前 N 个作为结果返回。
我们已经知道,Top N 聚合本质上是一个表聚合函数,这和窗口表值函数(TVF)有天然的联系。尽管如此,想要基于窗口 TVF 实现一个通用的 Top N 聚合函数还是比较麻烦的,目前Flink SQL尚不支持。不过我们同样可以借鉴之前的思路,使用OVER窗口统计行号来实现。
具体来说,可以先做一个窗口聚合,将窗口信息 window_start、window_end 连同每个商品的点击量一并返回,这样就得到了聚合的结果表,包含了窗口信息、商品和统计的点击量。接下来就可以像一般的 Top N 那样定义 OVER 窗口了,按窗口分组,按点击量排序,用ROW_NUMBER()统计行号并筛选前 N 行就可以得到结果。所以窗口 Top N 的实现就是窗口聚合与 OVER 聚合的结合使用。
下面是一个具体案例的代码实现。由于用户访问事件 Event 中没有商品相关信息,因此我们统计的是每小时内有最多访问行为的用户,取前两名,相当于是一个每小时活跃用户的查询。
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import static org.apache.flink.table.api.Expressions.$;
public class WindowTopNExample {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 读取数据源,并分配时间戳、生成水位线
SingleOutputStreamOperator<Event> eventStream = env
.fromElements(
new Event("Alice", "./home", 1000L),
new Event("Bob", "./cart", 1000L),
new Event("Alice", "./prod?id=1", 25 * 60 * 1000L),
new Event("Alice", "./prod?id=4", 55 * 60 * 1000L),
new Event("Bob", "./prod?id=5", 3600 * 1000L + 60 * 1000L),
new Event("Cary", "./home", 3600 * 1000L + 30 * 60 * 1000L),
new Event("Cary", "./prod?id=7", 3600 * 1000L + 59 * 60 * 1000L)
)
.assignTimestampsAndWatermarks(
WatermarkStrategy.<Event>forMonotonousTimestamps()
.withTimestampAssigner(new
SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event element, long
recordTimestamp) {
return element.timestamp;
}
})
);
// 创建表环境
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
// 将数据流转换成表,并指定时间属性
Table eventTable = tableEnv.fromDataStream(
eventStream,
$("user"),
$("url"),
$("timestamp").rowtime().as("ts")
// 将 timestamp 指定为事件时间,并命名为 ts
);
// 为方便在 SQL 中引用,在环境中注册表 EventTable
tableEnv.createTemporaryView("EventTable", eventTable);
// 定义子查询,进行窗口聚合,得到包含窗口信息、用户以及访问次数的结果表
String subQuery =
"SELECT window_start, window_end, user, COUNT(url) as cnt " +
"FROM TABLE ( " +
"TUMBLE( TABLE EventTable, DESCRIPTOR(ts), INTERVAL '1' HOUR ))
" +
"GROUP BY window_start, window_end, user ";
// 定义 Top N 的外层查询
String topNQuery =
"SELECT * " +
"FROM (" +
"SELECT *, " +
"ROW_NUMBER() OVER ( " +
"PARTITION BY window_start, window_end " +
"ORDER BY cnt desc " +
") AS row_num " +
"FROM (" + subQuery + ")) " +
"WHERE row_num <= 2";
// 执行 SQL 得到结果表
Table result = tableEnv.sqlQuery(topNQuery);
tableEnv.toDataStream(result).print();
env.execute();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
这里为了更好的代码可读性,我们将 SQL 拆分成了用来做窗口聚合的内部子查询,和套用 Top N 模板的外层查询。 (1)首先基于 ts 时间字段定义 1 小时滚动窗口,统计 EventTable 中每个用户的访问次数,重命名为 cnt;为了方便后面做排序,我们将窗口信息 window_start 和 window_end 也提取出来,与 user 和 cnt 一起作为聚合结果表中的字段。 (2)然后套用Top N模板,对窗口聚合的结果表中每一行数据进行OVER聚合统计行号。这里以窗口信息进行分组,按访问次数 cnt 进行排序,并筛选行号小于等于 2 的数据,就可以得到每个窗口内访问次数最多的前两个用户了。
+I[1970-01-01T00:00, 1970-01-01T01:00, Alice, 3, 1]
+I[1970-01-01T00:00, 1970-01-01T01:00, Bob, 1, 2]
+I[1970-01-01T01:00, 1970-01-01T02:00, Cary, 2, 1]
+I[1970-01-01T01:00, 1970-01-01T02:00, Bob, 1, 2]
2
3
4
可以看到,第一个 1 小时窗口中,Alice 有 3 次访问排名第一,Bob 有 1 次访问排名第二;而第二小时内,Cary 以 2 次访问占据活跃榜首,Bob 仍以 1 次访问排名第二。由于窗口的统计结果只会最终输出一次,所以排名也是确定的,这里结果表中只有插入(INSERT)操作。也就是说,窗口 Top N 是追加查询,可以直接用 toDataStream()将结果表转换成流打印输出。